PR [Learning to Prompt for Vision-Language Models]
Learning to Prompt for Vision-Language Models

Abstract
- CLIP과 같은 Vision Language 모델은 Vision-Language 분야에 큰 변화를 가져옴
- CLIP은 물론 제로샷 예측이 가능하긴 하지만, 그 성능이 부족함
- 따라서 원래 CLIP을 다른 downstream task에 전이학습 시키려면, 그 분야의 전문가가 전이학습 시킬 프롬프트를 수동으로 작성해줘야했음
- 부족한 성능을 채워주기 위한 하나의 전이학습 방식을 이 논문에서는 소개하고자함
→ CoOp (Context Optimization)
CoOp는? → CLIP 모델은 건드리지 않고, 입력하는 프롬프트만을 학습시켜서 새로운 데이터셋에 전이시키는 방식
- CLIP을 특정 작업에 맞춰 최적화하여 성능을 최대치로 끌어내는 과정이라고 생각
- 기존의 전이학습 방식
- Fine-Tuning (CLIP 모델의 전체 파라미터를 다시 학습)
- Linear Probe (CLIP 모델의 파라미터는 얼려두고, 마지막에 분류기 하나만 추가하여 학습)
CoOp는 위의 2가지 방식 중간에 있는 방법!
결론적으로 수동으로 작성한 프롬프트로 전이학습한 CLIP 모델보다 CoOp방식으로 (one or two shot)전이학습한 CLIP 모델이 더 효율적으로 성능을 끌어올릴 수 있었다.
Introduction
기존의 Vision Model을 SOTA 수준으로 끌어올리려면?
→ VIsion Model에게 부여하는 데이터의 라벨이 엄청 명확해야한다. (서로 구분이 확실하게 되어야함)
- 하지만, 예를 들어 금붕어, 화장실 휴지 와 같은 라벨들도 시각 모델의 데이터로 활용되려면 그저 class num이 부여된다.
- 즉, 텍스트를 의미가 아닌 번호로 취급
- 결국 ‘금붕어’, ‘화장실 휴지’ 라는 텍스트가 가진 의미가 단순히 분류를 위한 번호로 바뀌면서 전혀 활용되지 못함
최근 Vision-Language 모델의 사전학습 방식
- CLIP, ALIGN은 대조학습 방식을 사용하여 학습되고, 이후 다양한 downstream task들에 활용되기 위해서는 prompting 방식으로 전이학습이 된다.
- 대조학습? → 이미지와 텍스트에 각각 서로 다른 인코더를 사용하여 인코딩하고, 하나의 feature space(임베딩 공간)에서 서로 짝이 맞는 쌍은 가까이, 짝이 맞지 않은 이미지와 텍스트는 멀리
- Prompting
- Synthesize Classification Weights
- CLIP은 새로운 downstream task에 적용할때 학습이 필요없다.
- 텍스트 인코더에 Prompt를 전달하면, 해당 프롬프트에 해당하는 벡터(Weights)를 즉석에서 합성하여 생성(Synthesize)
하지만, 전이학습에 맞는 제대로된 프롬프트를 생성하는 것은 쉬운 일이 아니다!
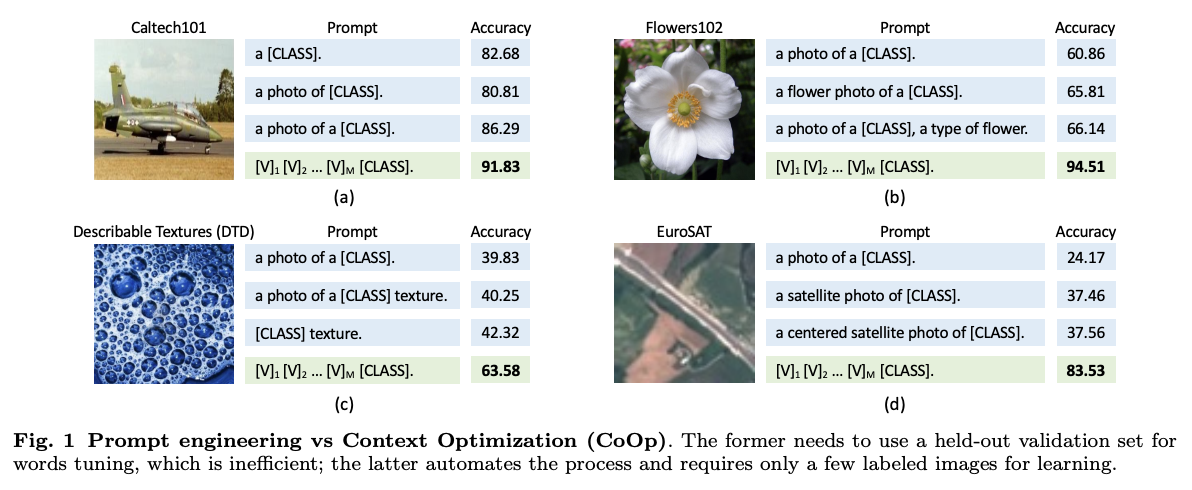
- 굉장히 많은 시간이 걸리고, 프롬프트가 조금만 달라져도, 많은 것이 바뀐다.
- 예시로, 프롬프트에 ‘a’ 하나를 추가해서 5%의 성능을 끌어올린 적도 있다. (Caltech 101)
- 전이학습하려는 분야에 대한 전문지식이 필요
→ 사진을 보면 얼마나 전이학습 성능에 프롬프트가 영향을 많이 끼치는지 확인할 수 있다.
최근 NLP 분야의 프롬프트 학습 연구를 활용
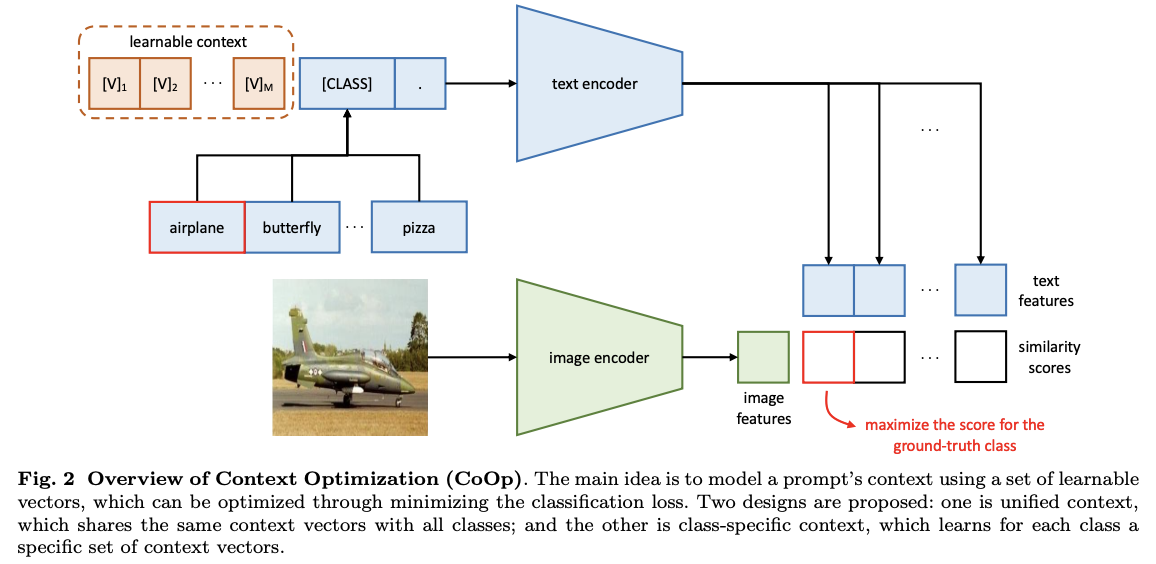
- CoOp (Context Optimization) 방식을 소개
- 프롬프트 엔지니어링을 자동화 (CLIP 과 같이 사전학습된 VIsion-Language Model을 위해)
- CLIP 모델을 효율적으로 전이학습 시키기 위한 프롬프트를 자동으로 생성
- CoOp도 학습을 해야한다!
- 학습을 한다는 것의 의미
- ‘모델 학습’ → 함수 f(x) 자체를 바꾸는 것
- ‘CoOp’ 학습 → 함수의 입력값 x를 최적의 x로 설정하기 위해 학습
- 학습을 한다는 것의 의미
- 각각의 클래스를 설명하는 프롬프트를 벡터 형태로 생성
- 각 벡터의 초기 값은 랜덤 or 사전학습된 word 임베딩으로 설정
- 초기에 프롬프트의 개수를 5개로 설정하면, 사진에서 초기 부분에 보이는 learnable context가 5개 생성
- 어떻게 학습 가능한 벡터를 구성할 것인가?
- Unified Context (통합 문맥)
- 모든 클래스가 똑같은 문백 벡터를 공유
- ex) 이것은 [- - -]의 사진 입니다. 라는 문장 틀을 만들고, 괄호 안의 단어만 바꾼다.
- Class-Specific Context (클래스별 문맥)
- 각 클래스마다 서로 다른 문백 벡터를 따로 배정
- Unified Context (통합 문맥)
- 학습 과정
- 모델이 얼어있는데 어떻게 학습이 될까?
- 정답과 예측값 사이의 오차를 줄이는 방향으로 학습
- CLIP 모델의 파라미터는 얼린 상태로 진행
- 오차가 발생하면, 얼어있는 텍스트 인코더를 통과하여 거꾸로 입력 벡터까지 내려와서 각 벡터의 값을 수정
→ CLIP 모델 내부의 방대한 지식을 역전파를 통해 입력 벡터 쪽으로 전이
- 모델이 얼어있는데 어떻게 학습이 될까?
💡CoOp 전이학습 방식의 주요 기여
- CLIP 과 같은 모델을 실제 현장에서 사용하기엔 프롬프트 엔지니어링 문제가 존재, 프롬프트를 수동으로 만들어야한다는 비효율성이 있음 (CoOp을 통해 비효율성을 해결)
- 수동으로 프롬프트를 생성하는 대신, 자동화하기 위해 연속 프롬프트 학습이라는 방법을 제안
- 프롬프트로 생성되는 벡터들은 모두 실수 벡터이기 때문에, 숫자가 연속적으로 변함
- Unified Context , Class-Specific Context (공용/클래스별 전용) 2가지 구현 방식
- 사람이 수동으로 만든 프롬프트 보다 성능이 좋으며, 기존의 전이학습 방식보다도 성능이 뛰어난 최초의 방식이다. 또한, 적용하려는 도메인이 바뀌어도 튼튼하다. (Robust)
Related Work
2.1 Vision Language Models
- 프롬프트 엔지니어링을 통해 downstream 분류 작업 범용성이 좋다.
- CLIP, ALIGN 과 같은 Vision Language Model 들은 다음 3가지의 장점을 가지고 있다.
- Transformer를 활용한 텍스트 표현 학습
- 대용량 미니배치 대조 학습
- 웹 스케일의 학습 데이터셋
- 이미지와 텍스트를 연결하려는 시도는 2013년부터 있었지만, Transformer와 같은 기술이 없었기에 다소 원시적인 방식이었다.
- CoOp는 더 좋은 Vision-Language 모델을 만드려고 하는 것이 아닌, 해당 모델을 실제 문제에 더 잘 적용하고 배포할 수 있도록 돕는 기술이다.
2.2 Prompt Learning in NLP
- CoOp을 비롯한 Vision-Language Model분야의 발전은 NLP 분야의 성공을 가져오는 것으로 시작됐다.
- Prompt Learning의 시초는 NLP분야이다.
- NLP 분야의 Cloze Test (빈칸 채우기) 에서 프롬프트를 조금만 바꾸어도 정답률이 확 달라지는 것을 알게되었고, 이 문제가 Prompt Learning의 시작이었다.
- NLP 분야에서 프롬프트를 만드는 방법은 크게 2가지로 발전했다.
- 이산적 방법
- 진짜 사람이 쓰는 단어(Token) 중에서 최적의 조합을 찾음
- 연속적 방법 (CoOp이 선택한 방식)
- 단어 대신 실수 벡터를 최적화
- 이산적 방법
CoOp는 NLP의 ‘Prompt Learning’ (모델이 더 잘 학습하도록 프롬프트를 조정)을 Computer Vision 분야에 도입한 첫 시도
Methodology
3.1 Vision-Language Pre-Training
Model
- Vision-Language 가 사전학습하는 방식들을 소개
- CLIP과 같은 모델은 2개의 인코더가 존재한다.
- 텍스트 인코더 (Transformer 기반)
- 이미지 인코더 (CNN 기반(ResNet), ViT(Transformer) 기반)
💡 CLIP 모델의 내부 Process
- 토큰화 (Tokenization) 주어진 텍스트를 토큰화 (글자를 ID 번호로 바꾼다)
- Byte Pair Encoding 방식을 사용
- 단순히 띄어쓰기 기준으로 주어진 텍스트를 토큰화하는 것이 아닌, 자주 나오는 단어 조각 단위로 쪼갠다. (apples → apple + s)
- 모든 문자를 소문자로 변환
- ‘a photo of a dog’ 라는 텍스트는 [320, 1125, 560, 320, 1980] 같은 숫자 리스트로 변환된다.
- CLIP은 총 49,152개의 단어 조각을 가지고 있음
- 포장하기 (Formatting)
- “encompassed with the [SOS] and [EOS] tokens and capped at a fixed length of 77.”
- [SOS], [EOS] 를 통해 문장의 시작과 끝을 표기
- 77로 길이를 고정
- 임베딩 및 변환 (Embedding & Transformer)
- “mapped to 512-D word embedding vectors, which are then passed on to the Transformer.”
- 각 숫자를 512개짜리 실수 리스트(Vector)로 바꾼다.
- 생성된 512차원 벡터들이 Transformer 모델로 입력된다.
- 최종 추출 (Feature Extraction)
- Transformer를 통과하면 77개의 토큰이 모두 변함
- [EOS] 토큰의 위치에 있는 벡터는 앞의 모든 단어 정보를 요약해서 담고 있다고 가정하기 때문에 [EOS] 토큰의 위치에 있는 벡터를 선택
- [EOS] 벡터를 (Layer Norm + Linear Projection) 거친 후에 최종적으로 해당 문장의 의미를 담은 벡터로 출력
Training
- 2개의 임베딩 공간을 독립적으로 사용하며 이 2개의 공간을 정렬한다.
- 대조 손실을 활용
- 이미지 - 텍스트 쌍의 batch를 받으면, CLIP은 서로 매칭되는 쌍 사이의 코사인 유사도를 최대화하고, 짝이 맞지 않는 쌍 사이의 코사인 유사도는 최소화한다.
- CLIP의 유연성을 위해 4억개 이상의 이미지- 텍스트 쌍 데이터셋을 수집
Zero-Shot Inference
- CLIP의 학습 방식은 Zero-shot에 적합하다.
왜? → 텍스트 인코더에 의해 즉석에서 생성된 가중치 벡터들을 이미지 특징들과 비교하여 텍스트가 가진 잠재적인 표현을 클래스 예측에 활용
- CLIP은 고정된 분류 클래스가 없고, 텍스트 인코더가 존재한다.
- 사용자가 텍스트를 입력하면, 해당 텍스트의 특징을 담은 벡터를 만들어내고, 생성한 벡터(Syenthesized Weights)와 이미지 특징을 비교!
- f : 이미지 인코더에 의해 추출된 이미지 x의 특징
- w_i : 텍스트 인코더에 의해 생성된 가중치 벡터
- K : 해결하고자 하는 문제에 존재하는 정답 후보의 총 개수
최종 예측 확률 계산 수식
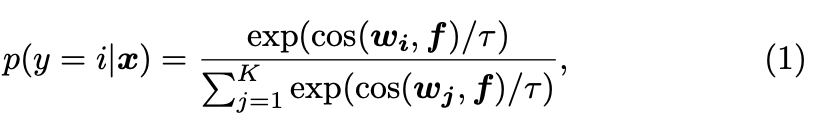
- τ : CLIP에 의해 학습된 온도 파라미터 (모델이 정답을 고를 때 얼마나 확신을 가질지, 코사인 유사도를 통해 계산된 유사도 점수의 분포를 스케일링하여 미세한 점수 차이를 크게 증폭)
- cos() : 코사인 유사도
| 기존의 분류 모델 (Classification) | 정적인 클래스 |
|---|---|
| (사전에 정의된 Label내에서만 예측) | |
| Vision-Language Model | 동적인 클래스 |
| (사용자가 텍스트를 입력하는 순간, 그 즉시 분류기가 생성된다. 텍스트 인코더를 활용) |
CLIP 모델의 사용 예시
- 이미지를 100장 가지고 있다고 가정 (CLIP 모델에 부여)
- CLIP 모델을 활용하여 ‘강아지를 찾아줘.’ 라고 텍스트 작성
- CLIP 모델은 문장 형식의 텍스트를 분류기(Weights)로 변환하고, 부여한 100장의 이미지를 모두 이미지 인코더를 통해 변환된 이미지 임베딩과 비교하여 가장 코사인 유사도가 높은 이미지를 반환!
→ 부여한 100장의 이미지 중, 강아지 사진이라고 CLIP이 분류한 이미지를 반환!
3.2 Context Optimization
- 논문에서 제안하고 있는 Context Optimization (CoOp)는 기존 prompt tuning 방식을 벗어나 모델의 파라미터들은 얼리고, 연속적인 벡터들을 통해 프롬프트를 생성한다.
Unified Context
- 모든 클래스가 동일한 context (문맥)을 공유
- 텍스트 인코더에 부여된 프롬프트는 아래의 수식으로 구성할 수 있다.
- [V]m은 모두 같은 차원인 벡터이며, M 은 context 토큰의 수를 구체화하는 하이퍼파라미터이다.
- 프롬프트 t를 텍스트 인코더 ( g() ) 에 부여함으로써 분류 가중치 벡터를 얻을 수 있다.
- 예측 확률은 아래의 수식을 통해 계산될 수 있다. (Softmax 함수)
- 위의 식에서 클래스가 변하면 ti 가 바뀐다. (i 번째 클래스 이름으로 변경)
(2) 번 식에서처럼 class token을 마지막에 배치하지 않고 식의 중앙에 위치시키면, 학습을 위한 유연성을 증가시킬 수 있다.

- (4) 번 식처럼 class token 을 식의 중앙에 위치하게 되면 유연성이 증가함 (아래의 2가지 방식을 통해)
- class token 뒤에 ([V] M/2+1 ) 마침표와 같은 종료 신호를 부여하면 종료 신호를 학습하여 뒷 부분을 생략하여 조기 종료시킴
- class token 뒤에 추가적인 묘사를 붙여서 이미지의 설명력을 높일 수도 있음
Class-Specific Context
- 각각의 클래스에 독립적인 context 벡터들을 활용하는 방식
- 세밀한 분류 작업 (Fine-Grained classification)에는 Class-Specific Context가 더 효율적임
Training
- Cross-entropy를 기반으로, classification Loss 를 최소화하는 방향으로 학습이 이루어지며, 기울기는 text encoder 부분까지 역전파된다.
- text encode (입력부분) 까지 기울기가 역전파되면서 기존의 사전학습된 Vision- Language Model의 풍부한 설명력을 습득한다.
- 연속적인 표현 (벡터를 연속적인 값으로 표현)은 임베딩 공간을 탐색할 수 있기 떄문에, 사람이 수동으로 만든 프롬프트보다 수학적으로 훨씬 더 완벽하고 정교한 프롬프트를 찾을 수 있다.
3.3 Discussion
- CoOp 방식은 CLIP과 같은 거대한 Vision-Language 모델의 문제점에 맞는 해결 방안이다.
- 기존의 NLP 분야의 Prompt Learning 방식과는 차이점이 있다.
- backbone 아키텍처가 근본적으로 다르다.
- Vision-Language Model은 이미지와 텍스트를 모두 입력 데이터로 활용
- Language Model은 텍스트 데이터만을 다룬다.
- 사전학습 방식이 다르다.
- Vision-Language Model : Contrastive Learning (대조학습)
- Language Model : Autoregressive Learning (자기회귀)
Experiments
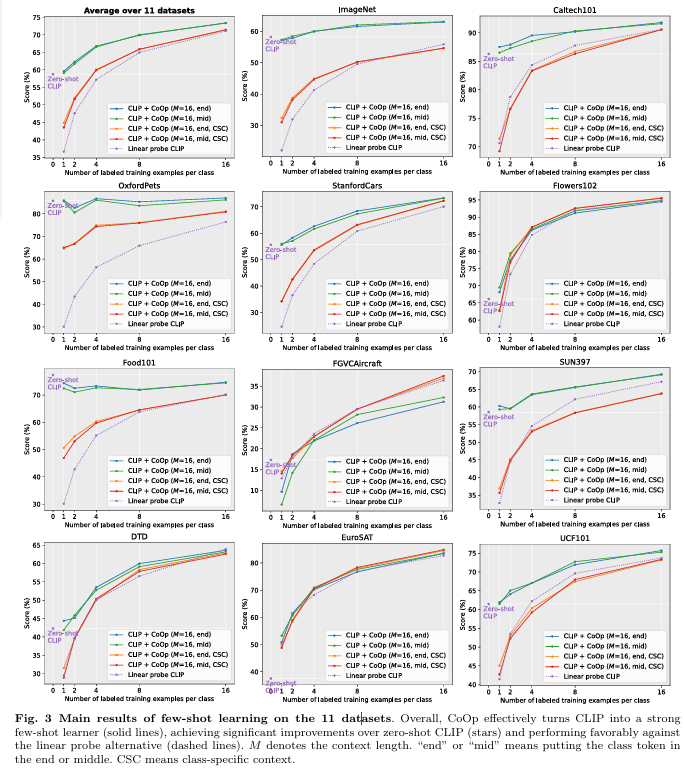
4.1 Few-Shot Learning
Datasets
- 11개의 classification 데이터셋을 활용하여 검증
- 결과적으로 CoOp (논문에서 제안하는 전이학습 방식)은 CLIP을 강한 few-shot learner로 효율적으로 바꿈
- zero-shot, linear probe과 비교하였을 때 확실한 발전을 이룸
- 그래프에서 M은 문맥의 길이를 뜻함 (Class Name을 제외한 프롬프트의 길이)
Training Details
- CoOp은 4가지의 버전이 존재
- class token을 맨 뒤, 중간에 위치하는 방식 2가지, 그리고 각각 통합 문맥을 활용하는 방식과, 클래스별 문맥을 활용하는 방식
- ResNet-50이 Image-Encoder의 backbone으로 활용됨
- M = 16
- context vector 들은 모두 랜덤한 실수로 설정
- 가우시안 분포는 평균이 0이고, 표준편차가 0.02인 종 모양의 분포에서 숫자를 랜덤으로 선택
- 확률적 경사 하강법
- Learning Rate : 0.02
- 스케줄 (Cosine Annealing) <학습이 진행될수록 속도를 어떻게 조절할 것인가?? → 코사인 어닐링 방식
- 처음에는 0.002, 나중에는 코사인 곡선을 그리며 점점 속도를 0에 가깝게 부드럽게 줄여나감
- Epoch : 200 (16/8shots), 100 (4/2shots), 50 (1 shot)
Baseline Methods
- Zero-shot CLIP, Linear Probe 를 비교 대상으로 설정
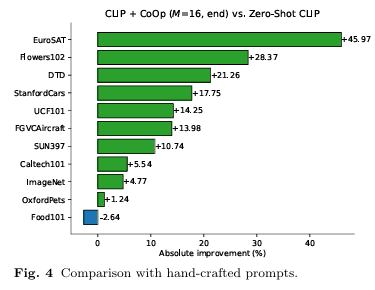
Zero-shot CLIP : CLIP 논문의 저자가 작성한 ‘프롬프트 만드는 공식’을 따른 Hand-Crafted 프롬프트 사용

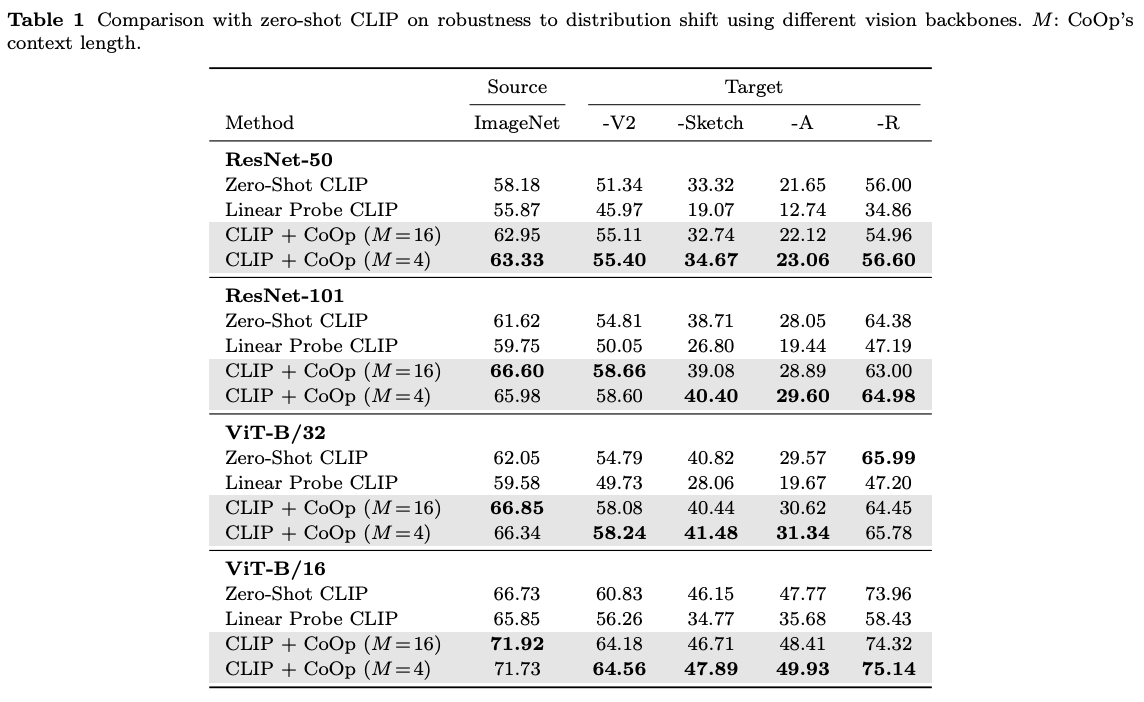
- 가장 성능을 끌어올리기 힘든 ImageNet 데이터셋에 대해서 4.77%의 성능 향상을 이룬 것과, EuroSAT, DTD와 같은 특정 분야에서 각각 45%, 20%의 성능 향상을 가져온 것은 CoOp가 얼마나 효율적인 방식인지를 입증
- Linear Probe : CLIP 모델은 얼리고, 그 위에 선형 분류기 하나만 얹어서 학습
- ‘좋은 모델 위에 선형 분류기 하나 붙이는 게 최고다’라는 연구 결과를 따름 (SOTA 급)
- Fig 3에서 확인할 수 있듯이, Linear Probe는 zero-shot의 성능까지 내기 위해서는 적어도 4-shot이 필요하지만, CoOp의 4-shot 성능은 이미 엄청났기 때문에, CoOp가 더 강한 도메인 일반화 능력을 가지고 있다고 입증한다.
Unified vs Class-Specific Context
- 평균적으로 통합 문맥을 사용하는 것이 더 좋은 성능을 냈다.
- 일반적인 목표 (ImageNet & Caltech 101 등) 에서는 통합 문맥의 성능이 더 좋았다.
- 정교화된 목표를 가진 데이터셋에 대해서도 통합 문맥의 성능이 더 좋지만, EuroSAT, DTD와 같은 특정 목표에 대해서는 클래스별 문맥을 사용하는 것이 더 성능이 좋았다.
Class-Specific Context가 더 성능이 안좋은 이유?
→ Unified 문맥 방식과 비교했을 때, 더 파라미터의 수가 많기 때문에 데이터의 수가 적을 때 (8 이하의 few-shot)는 통합 문맥 방식의 성능이 더 좋다.
4.2 Domain Generalization
- Domain Generalization (도메인 변화) → 정답 (Class) 가 바뀌는 것이 아니라, 스타일이 바뀌는 것이다!
- 같은 ‘강아지’를 찾는 것이지만, 카메라로 찍은 강아지 사진, 혹은 연필로 스케치한 강아지 사진 모두 구별할 수 있나?
→ CoOp는 가짜 상관관계를 배울 수 있기 떄문에 위험하다!
CoOp는 사진 데이터를 가지고 프롬프트를 최적화하기 때문에, CoOp이 사진 데이터 내의 특징에 과적합될 수도 있다.
Zero-shot CLIP, Linear Probe, CoOp 을 비교하여 다양한 전이학습 방식을 사용해도 CLIP의 풍부한 설명력이 사라지진 않을까?
Dataset
- ImageNet 데이터셋 사용
- ImageNetV2, ImageNet-Sketch, ImageNet-A, ImageNet-R (모두 ImageNet과 클래스 이름이 같다)
→ 즉, 데이터셋의 스타일 (Sketch, A, R)은 모두 달라졌지만, 맞추처야할 클래스 이름은 같다. (따라서, CoOp이 배운 프롬프트를 적용하여 성능을 테스트해볼 수 있음)
Results
- 데이터의 클래스는 갖지만, 이미지의 스타일이 달라져도 (Distribution shift가 있어도), CoOp 방식은 CLIP은 강건성을 뛰어 넘었다.
→ CoOp 방식으로 최적화한 프롬프트가 범용성이 있다(generalizable)는 것을 입증
- context token을 더 적게 사용했을때 더 모델이 강건했고, Linear-Probe 전이학습 방식은 성능이 좋지 못했다.
4.3 Further Analysis
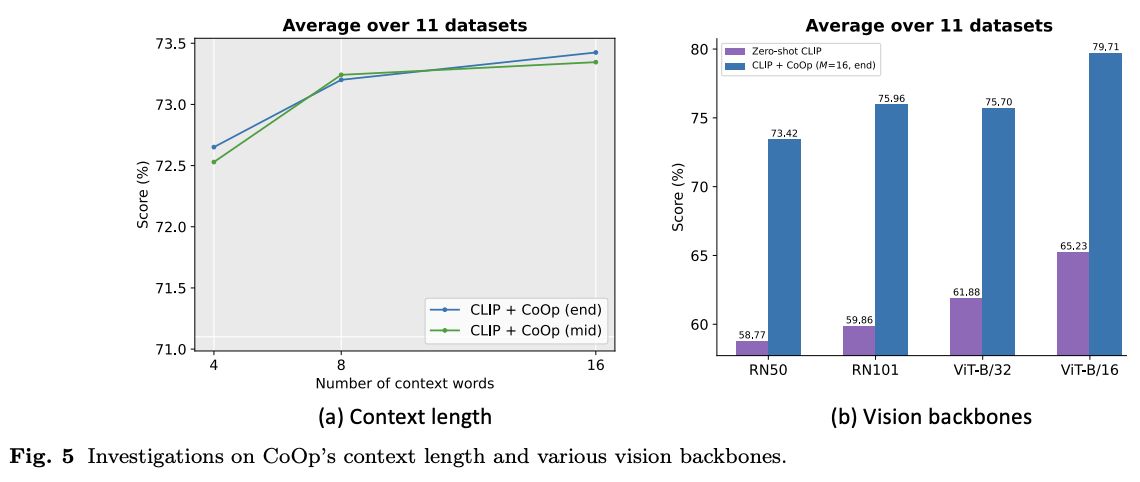
Context Length
- 몇개의 context token을 사용해야하나?
→ 앞서 더 적은 context token을 사용할때가 성능이 더 좋았다고 소개
- 앞서 사용한 11개의 데이터셋에 대해 context length를 4, 8, 16개로 늘려가며 실험
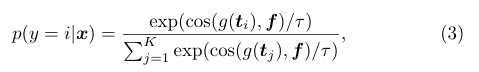
- 실험 결과, class name 토큰을 문장의 중앙에 위치하고, context token의 개수를 늘리는 것이 성능이 가장 좋았음
→ context token의 개수를 정하는 golden-rule (정해진 규칙)은 없고, 성능과 강건성 사이의 균형을 유지하는 것이 필요함
Vision Backbones
- CNN과 ViT를 백본으로 사용하며, 더 발전된 모델을 backbone으로 활용할수록, 더 성능이 좋았다.
- 어떠한 백본 아키텍처에도 CoOp 방식으로 생성된 프롬프트와 hand-crafted 프롬프트 사이의 차이는 명확하다.
Comparison with Prompt Ensembling
- CLIP의 저자들은 서로 다른 hand-crafted (수동) 프롬프트들을 합치는 것이 모델의 추가적인 성능 향상을 가져올 수 있다고 설명
→ CoOp으로 생성된 프롬프트들은 Prompt Ensembling 한 것과 비교하였을 때 이점이 있는지 확인
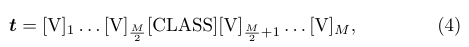
- 성능 비교 결과, 여전히 CoOp 방식으로 생성된 프롬프트를 활용하였을때 성능이 더 좋았으며, 후에 CoOp의 발전 방향을 prompt ensembling 관점에서 고려할 것임
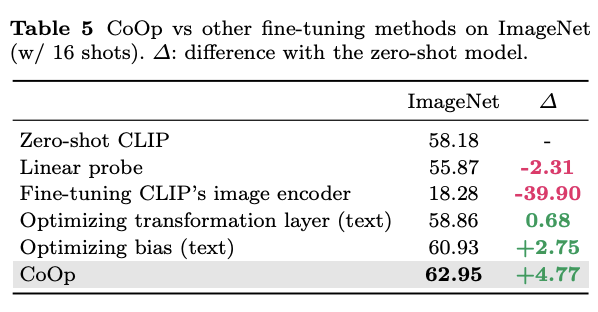
Comparison with Other Fine-Tuning Methods
CLIP의 이미지 인코더를 Fine-Tuning 한 모델과도 비교
CLIP에 transformation layer를 추가해도, 편향을 최적화하는 방식으로 CLIP을 Fine-Tuning해도, 그 성능은 CoOp를 넘지 못했다.
Initialization
CoOp 학습을 시작할 때, 학습 가능한 실수 벡터들에 처음에 초기화하는 방법
- 무작위 초기화 (Random Initialization)
- 가우시안 분포를 따르는 랜덤한 숫자로 초기화
- 수동 초기화 (Manual Initialization)
- 사람이 흔히 사용하는 문장, a photo of a 의 임베딩 값으로 초기화
→ 굳이 Manual 방식을 선택할 필요가 없다. 랜덤으로 초기화를 해도, CoOp는 결국 최적의 프롬프트를 생성한다.
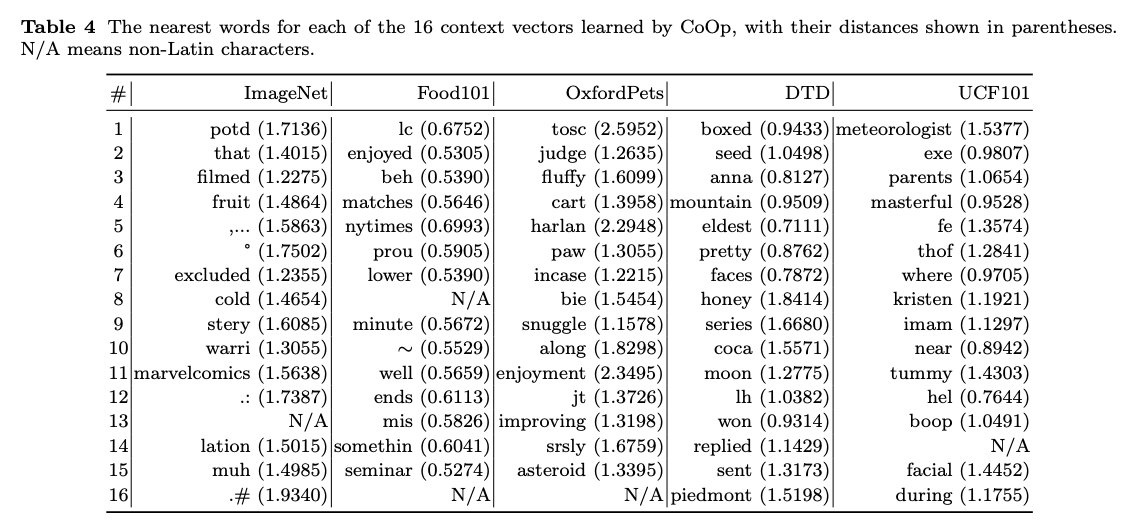
Interpreting the Learned Prompts
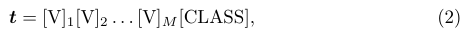
- 어떻게 CoOp 방식을 통해 생성된 최적의 프롬프트(실수 형태의 벡터)를 자연어로 해석할 것인가?
- 번역 방법
- 학습된 벡터와 CLIP이 알고 있는 49,152개의 단어 벡터들을 비교하고, 유클리드 거리를 측정하여 수학적으로 거리가 가장 가까운 단어를 찾음
결과 → 가끔 이미지와 관련된 단어가 나오지만, 단어들을 나열해보면, 문장이 되지 않음
따라서, CoOp가 학습한 벡터는 인간의 사전에 있는 단어로는 완벽하게 표현할 수 없는 그 이상의 의미를 가지고 있다고 표현
Conclusion, Limitations and Future Work
💡Conclusion
- CLIP과 같은 사전학습된 거대 Vision-Language Model들은 강력한 수용력과 표현력을 가지고 있지만, 후속 응용에 있어서는 미완성인 상태였다.
자동화 (Automated Adaptation)
- CoOp는 사람이 일일이 손대지 않고, 자동으로 최적화하는 기술을 성공적으로 도입
강건성 (Robustness)
- 학습을 시키면 새로운 환경에 약해지기 마련이지만, CoOp은 학습을 시켜도 여전히 강건성을 유지
Limitations
- 성능은 좋지만, 아직 학습이 완료된 최적 벡터들이 정확히 어떤 것을 의미하는지 모름
- Food101 데이터셋에 대한 성능이 좋지 않은 것으로 보아, 노이즈에 약함
Future Work
- CoOp은 구조가 단순하기 때문에, 응용할 곳이 다양함
- Cross-dataset Transfer
- A 데이터셋에서 배운 프롬프트를 B데이터셋에서 사용
- Test-time Adaptation
- Test-Time 도중, 실시간으로 프롬프트를 수정하여 적용
- Mega-size Models
- CLIP 보다 더 큰 초대형 모델들에 적용
- Cross-dataset Transfer