PR [Learning Transferable Visual Models From Natural Language Supervision(2021)]
Learning Transferable Visual Models From Natural Language Supervision(2021)

Abstract
- 기존의 CV 시스템 : 미리 정해진 고정된 클래스만 인식하도록 학습, 새로운 시각 개념을 학습하려면 추가적인 레이블링 데이터가 필요 (모델의 일반성 제한)
- CLIP : 이미지에 대한 가공되지 않은 Raw 자연어를 새로운 형태의 광범위한 지도 소스로 활용
- 사전학습 후, 자연어를 활용하여 학습된 시각 개념을 참조하여 후속 테스크에 대한 Zero-shot Transfer (제로-샷 전이)가 가능하게 한다.
⇒ CLIP은 대규모 웹 데이터와 자연어 감독을 통해 학습, 파인 튜닝 없이도 광범위한 CV 테스크에 전이되는 범용적인 시각 모델
Introduction
- 가공되지 않은 텍스트로부터 직접 학습하는 사전학습 (Pre-training) 방법들은 지난 몇 년간 NLP 분야에 큰 변화를 가져옴.
- Text-to-Text 가 표준화된 입출력 인터페이스로 개발되면서, 특정 Task에 구애받지 않는 아키텍처들이 특수화된 출력 헤드나 데이터셋별 맞춤화 없이도 후속 데이터셋으로 제로-샷 전이를 할 수 있게 되었다.
- Text-to-Text : 입력 텍스트를 받아 출력 텍스트를 생성하는 방식 (이전에는 작업마다 다른 출력 구조가 있었음)
- 하지만, 컴퓨터 비전 분야에서는 여전히 수동 레이블링된 데이터셋에서 사전 학습하는 것이 표준적이었다.
그렇다면 논문에서 말하는 NLP의 혁명적인 방식은?
⇒ Transformer 아키텍처를 기반으로, 정답이 없는 방대한 텍스트 데이터에서 모델 스스로 학습할 규칙을 만들어냄 + Text-to-Text 방식 (BERT, GPT 계열)
→ 웹 텍스트로부터 직접 학습하는 확장 가능한 사전학습 방법론이 컴퓨터 비전 분야에도 적용될 수 있나?
- 기존의 한계점 (NLP 분야의 Supervision 방식을 Computer Vision 분야에 적용했을 때)
- 저조한 성능, 유연성-감독의 범위 (성능이 저조해서 감독의 범위를 제한하자, 모델의 유연성도 같이 떨어짐)
- CLIP의 결정적인 차별점 : NLP Supervision + Weak Supervision (각 방식의 장점만을 뽑아옴)
- Strong Supervision(강한 감독 방식) 은 최고의 정확도를 달성하지만, 데이터를 하나하나 레이블링해줘야함. (데이터셋이 제한적이고, 다른 Task로의 확장성이 낮음)
- Weak Supervision(약한 감독 방식) 은 모델이 학습하는 규칙이 부정확하며, 자연어가 가진 무한한 개념을 포착하지 못함
CLIP ⇒ 약한 감독의 규모 + 자연어 감독의 유연성
- 약한 감독의 규모 : 약한 감독 연구들은 인터넷에서 대용량 데이터를 자동 수집하여 활용, CLIP 또한 사람이 일일이 레이블링하지 않고, 인터넷에서 대량으로 쌍을 이루는 4억 개의 (이미지, 텍스트)쌍을 사용하여 데이터 규모 확보
- 자연어 감독의 유연성 : 기존의 정적인 레이블에서 벗어나 무한한 수의 텍스트 문장을 동적으로 활용하여 엄청나게 다양한 레이블을 생성
쉽게 생각하면, 이전에는 레이블을 생성할 수 있는 범위가 제한적이었다면, 이제는 무한한 자연어를 가지고 수많은 레이블을 동적으로 생성할 수 있다. 거기에 데이터셋도 Scale이 커지니까 모델 자체에 엄청난 유연성이 부여된다.
Approach
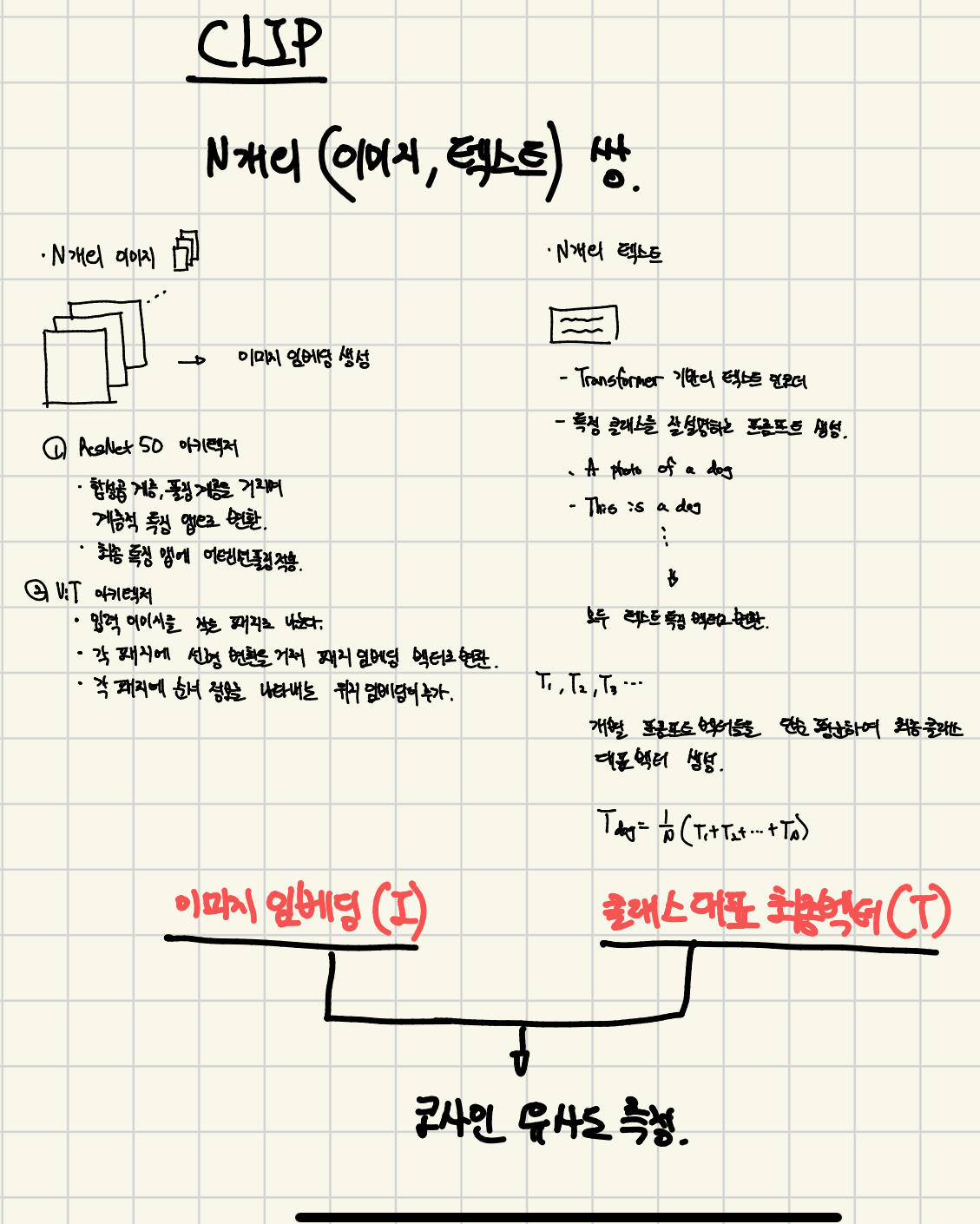
2.1 Natural Language Supervision (자연어 감독)
- CLIP의 접근 방식의 핵심 : 자연어를 학습 신호로 인식하는 점이 핵심
- 장점
- 확장성 : 전통적인 형식 없이 인터넷 텍스트에서도 학습할 수 있기 때문에 데이터 확장이 용이
- 유연한 전이 : 단순히 표현을 학습하는 것을 넘어, 표현을 언어와 연결하여 유연한 제로-샷 전이를 가능하게 한다.
2.2 Creating a Sufficiently Large Dataset (충분히 큰 데이터셋 생성)
- 인터넷에 공개적으로 누구나 접근가능한 형태의 대규모 데이터셋을 생성하려고 노력
- 인터넷 상의 다양한 공개 소스에서 수집한 4억개의 (이미지, 텍스트) 쌍으로 새로운 데이터셋 구성
- 약 50만개의 쿼리를 사용하였으며, 데이터 셋의 균형을 위해 쿼리당 수집되는 쌍의 개수를 최대 20,000쌍으로 제한
2.3 Selecting an Efficient Pre-Training Method (효율적인 사전 학습 방법 선택)
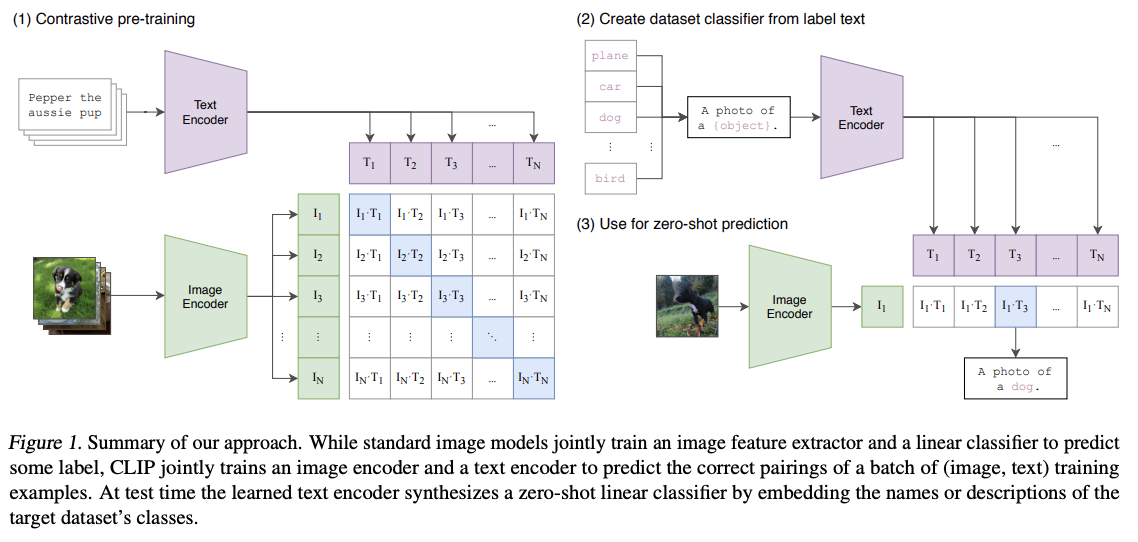
- 초기 접근 방식
- 이미지 CNN과 텍스트 트랜스포머를 처음부터 공동으로 훈련시켜 이미지의 캡션을 예측 (VirTex방식) (효율적이지 않음)
- 캡션을 정확히 예측하는 생성 모델 방식 시도 (매우 느림)
- 최종 선택 (대조 학습)
- 텍스트의 정확한 단어를 예측하는 대신, 이미지와 텍스트가 서로 짝이 맞는지만 예측 (더 효율적)
- N개의 (이미지, 텍스트) 실제 쌍을 포함하는 하나의 배치 사용
- 이 N개의 이미지와 N개의 텍스트로 만들 수 있는 가능한 쌍은 총 NxN개
- 긍정 쌍 (N개) : 실제 짝이 맞는 N개의 쌍에 대해서는 임베딩 간의 코사인 유사도를 최대화
- 부정 쌍 (N^2 - N개) : 짝이 맞지 않는 나머지 쌍에 대해서는 임베딩 간의 코사인 유사도를 최소화
- 손실 함수 : 대칭적 교차 엔트로피 손실
- 단순화 과정
- 표현 공간과 대조적 임베딩 공간 사이의 ‘비선형 투영’ 대신 ‘선형 투영’ 사용
- 사전 훈련된 가중치를 사용하지 않고 처음부터 (From Scratch) 학습
- 온도 매개변수 τ를 하이퍼파라미터로 설정하지 않고, 모델이 학습 과정에서 스스로 최적의 스케일링을 찾도록 설정
2.4 Choosing and Scaling a Model
- 이미지 인코더 아키텍처 (2가지 주요 이미지 인코더 계열 실험)
- ResNet 계열 (기존 전역 평균 풀링 대신 어텐션 풀링 사용)
- 기존의 전역 평균 풀링 : Convolution Layer를 거쳐 나온 최종 특징 맵의 모든 픽셀 값의 평균을 구하기 때문에, 객체의 정확한 위치 정보나 중요한 세부 정보가 손실될 수 있다.
- 어텐션 풀링 (CLIP) : 이미지의 중요한 부분을 선별적으로 포착 (전체 이미지 중에서 전역 문맥과 가장 관련성이 높은 부분만 Attention 부여하여 추출된 특징 벡터를 생성)
- Vision Transformer (ViT) 계열
- ViT는 이미지를 텍스트처럼 처리하기 위해 패치 임베딩(각 패치를 선형변환하여 벡터로 변환), 위치 임베딩(각 패치가 이미지의 어느 위치에 있는지에 대한 정보를 담은 벡터 생성), 결합 (패치 임베딩과 위치 임베딩 결합)
- CLIP의 수정 : 결합된 최종 임베딩에 계층 정규화를 적용
- ResNet 계열 (기존 전역 평균 풀링 대신 어텐션 풀링 사용)
- 텍스트 인코터 아키텍처 (Transformer)
- 입력 : 소문자 토큰을 사용, 최대 시퀀스 길이는 76으로 제한 (SOS 텍스트의 시작을 알림, EOS 텍스트의 끝을 알림)
- 출력 : Transformer의 최종 출력 계층에서 EOS 토큰에 해당하는 활성화 값을 텍스트의 최종 특징 표현으로 사용
2.5 Training
- 데이터셋 : WIT (4억개의 이미지 텍스트 쌍)
- 에포크 : 32
- Optimizer : Adam
- 정답이 아닌 쌍의 가중치 감소, 코사인 학습률 감소
- 매우 큰 미니 배치 크기 : 32,768
Experiments
3.1 Zero-Shot Transfer
- 기존의 제로-샷 학습 : 모델이 보지 못한 객체 카테고리로 일반화하는 것 (새로운 클래스 레이블에 매핑)
- CLIP의 정의 : 보지 못한 데이터셋으로의 일반화, 즉 태스크 학습 능력을 측정 (파인 튜닝 없이 즉시 일반화하여 성능을 발휘하는 능력 측정)
- CLIP : 이미지와 텍스트가 짝이 맞는지 예측하도록 훈련 (제로-샷 분류 시 이 능력을 재사용)
- 분류 과정
- 이미지 임베딩 : 이미지 인코더가 이미지 특징 벡터를 계산
- 텍스트 임베딩 (분류기 가중치) : 데이터셋의 모든 클래스 이름을 자연어 프롬프트로 변환하여 텍스트 인코더에 입력, 텍스트 인코더는 프롬프트들을 특징 벡터로 계산하는데, 이 벡터들이 곧 선형 분류기의 가중치 역할을 한다.
- 예측 : 이미지 임베딩과 모든 텍스트 임베딩(가중치) 간의 코사인 유사도를 계산하여 가장 유사도가 높은 텍스트를 최종 예측으로 선택
- 분류 과정
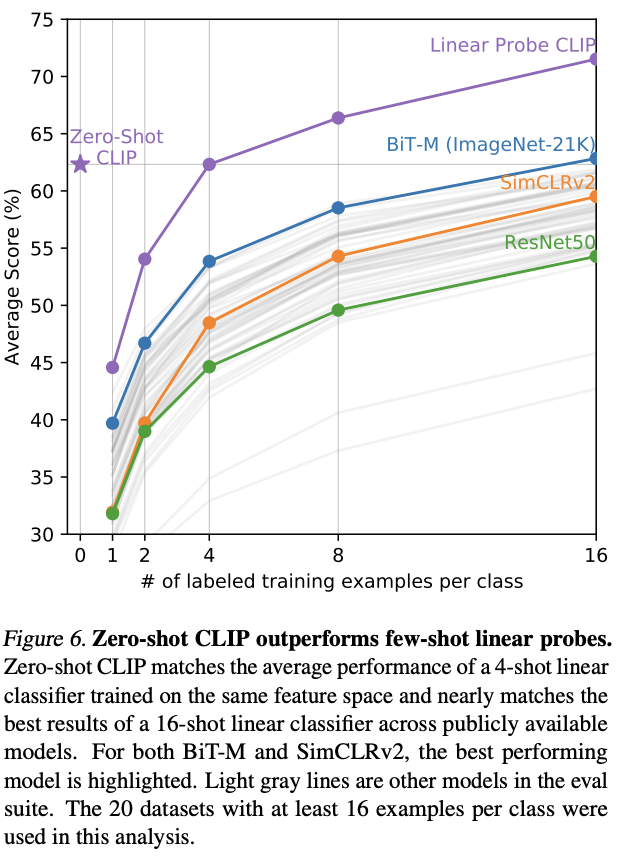
→ 이 방식으로 CLIP을 제로-샷에 사용
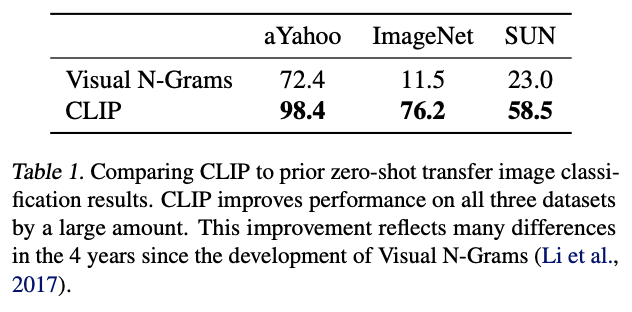
성능 비교
- CLIP의 최고 성능 모델은 기존의 11.5% 였던 제로-샷 정확도를 76.2%까지 끌어올렸다.
성능 최적화
- 기존 데이터셋의 단순한 클래스 이름은 CLIP이 학습한 자연어 문맥과 분포가 다르고, 다의성 문제를 일으킴
- 해결책
- 기본 프롬프트 (템플릿)을 사용하여 모델이 학습한 자연스러운 문맥을 제공
CLIP (제로-샷)의 성능 저조 영역 분석
- 위성 이미지 분류, 합성 장면 객체 수 세기
- 공간적 추론, 세부적인 지식을 필요로 하기 때문에, CLIP의 자연어 감독으로는 이러한 복잡하고 추상적인 논리 구조를 효과적으로 학습 못함
- 림프절 종양 감지, 자율 주행 거리 인식, 독일 교통 표지판 인식
- 도메인의 전문 지식을 필요로 하기 때문
Few - Shot 학습과의 비교
- 본래 1-shot 학습 (하나의 예시를 가지고 학습) 이 zero-shot 학습보다 우수해야하지만, CLIP의 제로-샷 성능은 동일한 특징 공간에서의 4-shot Logistic 회귀 성능과 일치
→ 그만큼 데이터를 효율적으로 활용하고 있다는 점을 강조
3.2 Representation Learning (표현 학습)
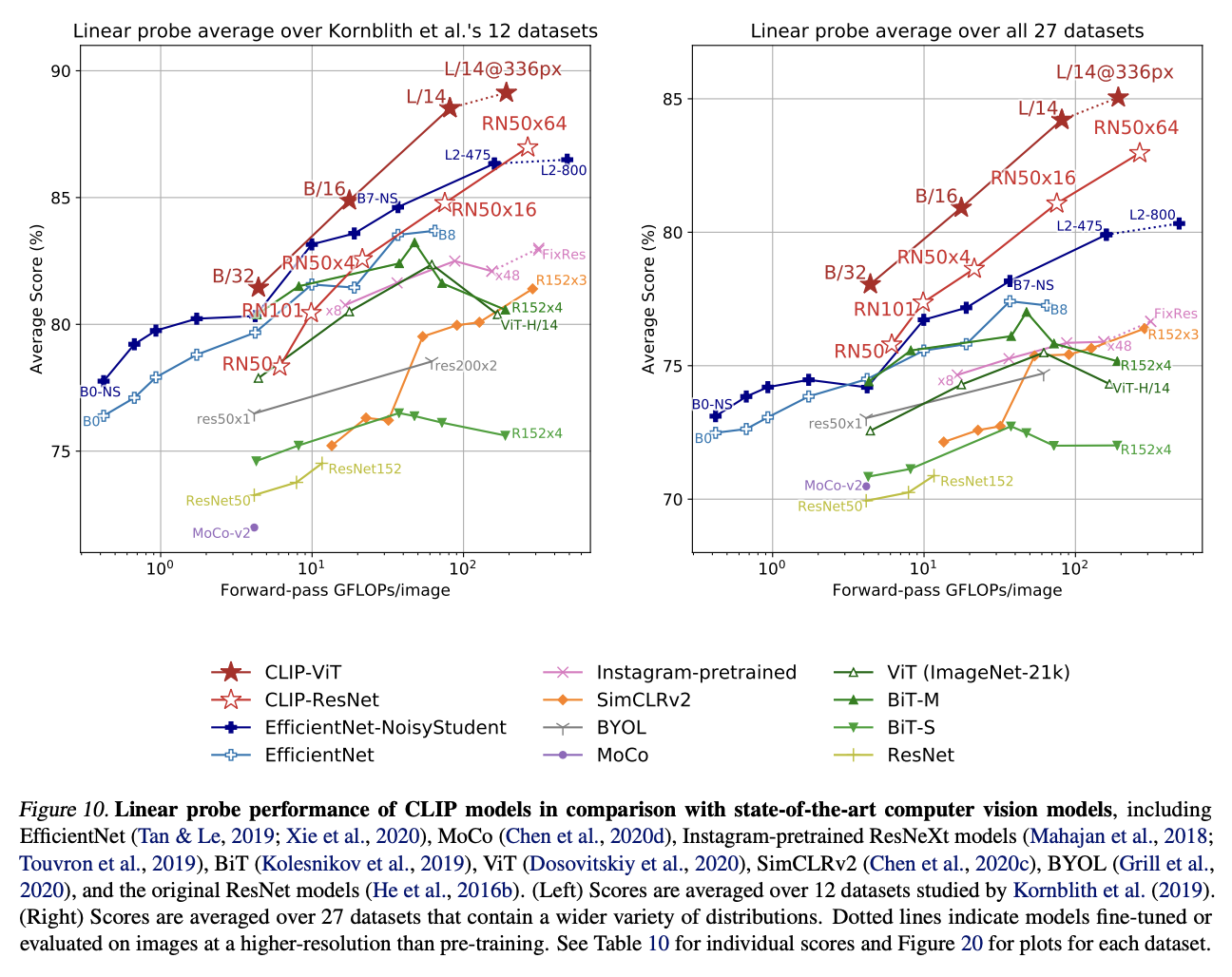
- CLIP의 특징 추출 능력을 평가하기 위해 Zero-shot이 아닌 Linear Classifier (선형 분류) 기반의 평가를 수행
일반적인 방식 : 파인 튜닝이 선형 분류보다 성능이 우수하여 더 선호되지만, CLIP은 선형 분류 기반 평가를 고수
이유
- 파인 튜닝은 전이 단계에서 표현을 조정하여 사전 학습 단계의 실패를 감출 수 있고, 선형 분류기는 제한된 유연성으로 인해 일반적이고 강건한 표현 학습의 실패를 더 잘 드러낸다.
- ResNet-50 , ResNet-101과 같은 소형 CLIP 모델은 다른 ResNet 모델보다 성능이 우수하지만, ImageNet-21k로 훈련된 EfficientNet 계열에는 미치지 못했다.
- ViT의 효율성 - Vision Transformer를 아키텍처로 선택했을때가 ResNet 아키텍처를 활용했을때보다 계산이 3배 더 효율적이기 때문에, 더 높은 전체 성능을 달성할 수 있었다.
결론
| CLIP의 압도적인 우위가 드러난 태스크 | OCR 및 밈, 위치/장면 인식, 활동 인식, 세밀 분류 등 |
|---|---|
| EfficientNet이 우위를 점한 영역 | ImageNet 훈련데이터셋, 저해상도 데이터셋, 특수/복잡 태스크 |
| 모든 CLIP 모델 | 계산 효율성, 성능 향상, 태스크 다양성 측면에서 그 이점이 명확 |
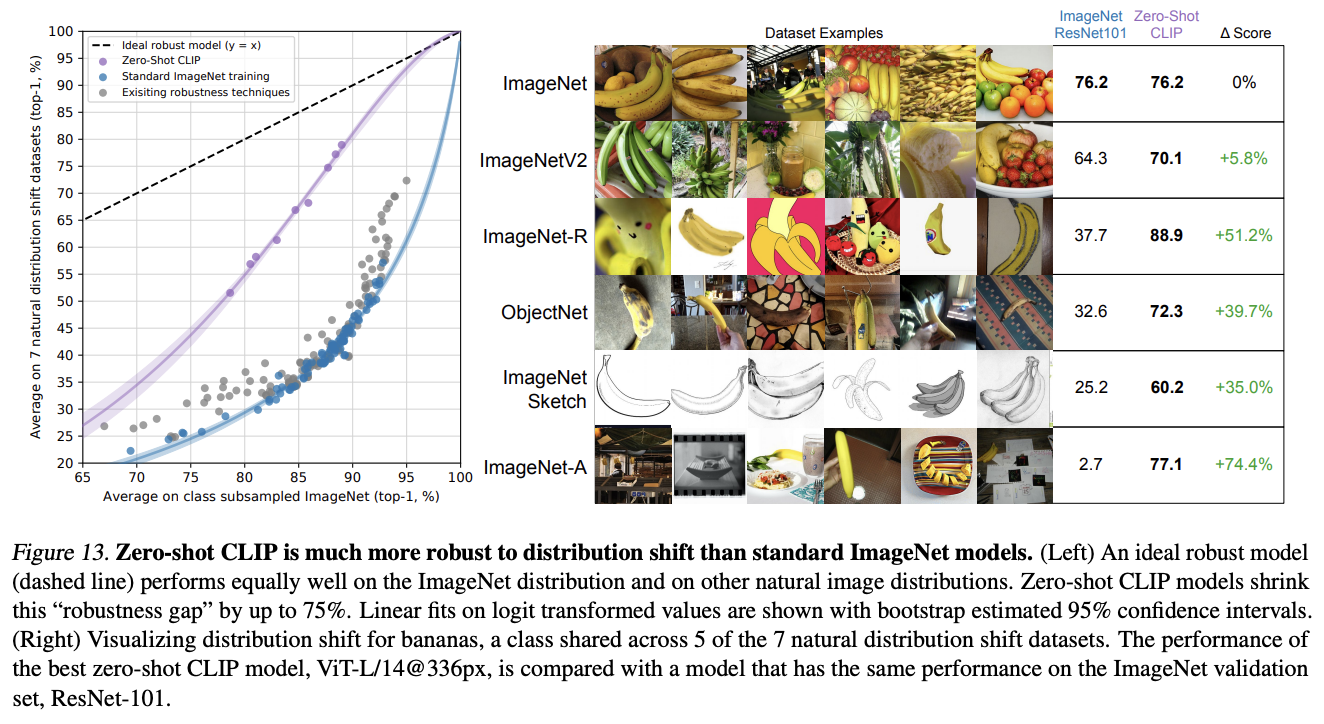
3.3 Robustness to Natural Distribution Shfit (자연적인 분포 변화에 대한 강건성)
- 기존의 ImageNet : 훈련데이터셋이 굉장히 깨끗하고 정제된 데이터
- 훈련 데이터 내에서만 통하는 상관관계에 제한적인 성능을 가지고 있다.
→ CLIP은 4억 쌍의 광범위하고 다양한 자연어 감독을 통해 훈련되었기 때문에, 데이터셋 내에서 존재하는 상관관계에 덜 제한적이다.
- 실제로 CLIP의 제로-샷 모델은 기존 ImageNet과 비교하여 유효 강건성을 크게 향상시켰고, ImageNet 정확도와 분포 변화 정확도 사이의 격차를 최대 75%까지 감소시켰다.
결론적으로, 자연어 감독 (기존에 존재하는 자연어를 활용하여 새로운 클래스를 동적으로 정의, 학습)을 통한 Zero-shot 전이는 ImageNet의 허위 상관관계를 피하게하며, 실용적이고 강건성을 확보하는 효과적인 방법이다.
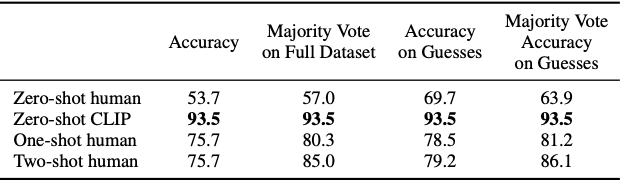
Comparison to Human Performance
- CLIP의 Zero-shot과 Few-shot 성능을 인간의 학습 효율성과 비교하여, 기계와 인간 학습 방식의 차이점을 연구
- 평가 데이터셋 : Oxford IIT Pets 데이터셋 (3669장, 37개의 고양이,강아지 품종 클래스)
- 참가자 : 5명의 인간 작업자
- 태스크 : 37개 품종 중 가장 잘 맞는 것을 선택하거나 ‘모르겠다’를 선택하도록 설정
- CLIP의 성능은 인간의 성능보다 월등히 높았다.
💡
- 하지만 여기서 주목해볼만한 점은, 인간은 실험과정에서 자신이 품종을 정확하게 분류하지 못할것으로 판단되면 ‘모르겠다’라고 답했다.
- 즉, 분류에 필요한 정보가 부족하다고 느낄 때 오답을 추측하기보다 불확실성을 표현
- 인간은 Zero-shot에서 One-shot으로 넘어갈때 22%의 성능 향상을 보임.
- 이 성능 향상은 주로 자신이 Zero-shot 예측 때에는 모르겠다고 표기했거나 불확실했던 이미지들에서 발생
즉, one-shot 예제를 자신이 불확실했던 개념에 대한 결정적인 정보로 활용함
- 하지만 CLIP의 경우
- 자연어 프롬프트 기반의 유사도 비교를 통해 강제로 예측을 수행
- 불확실성을 명시적으로 인지, 활용 X
⇒ 인간보다 성능이 좋다는 것에 집중하는 것이 아니라, 인간이 one-shot 예제를 활용하는 방식을 참고하여 알고리즘을 수정
(모르는 것을 인지하고, few-shot 때 자신이 모르는 것을 보완하기 위해 데이터를 효율적으로 사용)
Data Overlap Analysis (데이터 중복 분석)
- 만약 대규모 웹 데이터셋이 평가용 데이터셋과 의도치 않게 중복된다면?
이상적인 방법 : 모든 잠재적인 평가 데이터를 미리 알고 훈련 전에 중복을 제거
→ 한계가 있음
- CLIP이 선택한 방식 : 중복이 얼마나 발생하고, 중복이 미치는 영향을 정량적으로 기록, 분석
- 중복 탐지 및 분할
- 각 평가 데이터셋에 대해 중복 탐지기를 적용
- 훈련 데이터의 가장 가까운 이웃(Nearest Neighbors)를 찾고, 정밀도를 최대화하는 임계값을 설정하여 데이터셋을 2개의 새로운 집합으로 나눔
- Overlap : 훈련 예제와 유사도가 임계값 이상인 예제 (중복 데이터)
- Clean : 유사도가 임계값 미만인 예제 (중복이 없는 깨끗한 데이터)
- 오염도 = Overlap / Overlap+Clean
- 정량적 영향 측정
- 3가지 데이터 분할 (All, Overlap, Clean)에 대한 CLIP의 Zero-shot 정확도를 계산
- 통계적 유의성 검증
- 중복 탐지 및 분할
- 분석 결과
- 중복 없음
- 기존의 연구들과 중복 분석 결과가 일치
Limitations
- 성능 및 효율성 문제
- SOTA(최고수준)(단순 지도 학습 기준 모델 : ResNet-50)와의 성능 차이가 크지 않다.
- 전체 SOTA(최고 수준)에 도달하기 위해서는 컴퓨팅 수준에서 약 1000배의 추가 컴퓨팅이 필요 (계산 및 데이터 효율성을 개선해야함)
- 특정 태스크에 대한 취약점
- 세밀분류 - ex) 자동차 모델, 꽃 종 등 세부적인 차이를 구별할때 성능이 저조
- 추상적/체계적 태스크 - ex) 객체의 개수를 count
- 새로운/특수 태스크 - ex) 사진 속 가장 가까운 자동차까지의 거리 분류
- 강건성의 근본적인 문제 미해결
- 자연적인 이미지 분포에는 잘 일반화되지만, 훈련 데이터셋에 전혀 없는 데이터에 대해서는 일반화가 미흡
- 유연성의 제한
- 출력 제한 : 제로-샷 분류기가 미리 정의한 개념 목록 중에서만 선택 가능
- 비효율성 문제 : 생성적 모델 방식에 대해서는 계산 효율성이 낮음
- 샘플 효율성 문제
- 딥러닝의 낮은 데이터 효율성 문제를 해결 X
- 대신 수억 개의 예제를 사용하여 문제를 보완하기만 했음
훈련 규모 : 32에포크 동안 128억 장의 이미지를 반복하려면 405년이 걸림
(데이터 효율성을 개선하는 방식을 찾아야함)
- 딥러닝의 낮은 데이터 효율성 문제를 해결 X
Broader Impacts (추가적인 영향성)
- CLIP은 재훈련 없이 자연어를 통해 임의의 클래스를 쉽게 생성할 수 있는 능력을 가지고 있다.
- 긍정적 영향 : OCR, 이미지 검색, 지리적 위치 파악 등 광범위한 응용 분야에 쉽게 적용 가능
- 부정적 영향 : 사회적 함의가 큰 태스크(CCTV 영상에서 특정 인물 분류)에 부적합할 수 있음
7.1 Bias(편향) 분석
- 필터링되지 않은 웹 데이터로 훈련되었기 때문에 사회적 편향이 내재되어있다.
- 교차 인종/성별 그룹 성능
- 다양한 인종과 성별 분류 정확도가 높다 (모든 인종 카테고리에서 95% 이상으로 높은 정확도)
- 비인간/범죄 관련 용어 편향
- FairFace 이미지 중 4.9% 정도가 비인간 카테고리로 오분류
- 흑인 그룹 이미지에서 오분류율이 가장 높았다.
- 남성 이미지의 16.5%가 범죄 관련 클래스로 오분류
- 여성 이미지의 9.8%가 범죄 관련 클래스로 오분류
- 또한, 직업/성별 편향도 존재
7.2 Surveillance (감시)
- 사회적 민감성이 높은 감시 태스크에 대한 CLIP의 성능 분석
- CCTV 이미지 분류
- Zero-shot 성능이 매우 저조
- 유명인 식별
- 100개 클래스 : 59.2%의 정확도
- 1000개 클래스 : 43.3%의 정확도
→ 단순히 이름만으로 이 정도의 Zero-shot 식별 능력을 보인다는 것은 주목할만함
- CCTV 이미지 분류
7.3 Future Work (향후 연구)
- Zero-shot 성능은 좋지만, Few-shot 환경에서는 인간보다 비효율적이다.
- CLIP이 가진 사전 지식을 Few-shot 학습 시 효율적으로 통합하고 업데이트하는 방향으로 알고리즘을 개발
- 인간처럼 적은 데이터만으로도 성능을 크게 올리는 것이 목표
- CLIP은 새로운 클래스를 동적으로 생성하는 능력이 있지만, 이 능력은 아직 무한한 유연성을 가지고 있진 않음
- 효율성과 창의적인 유연성을 부여하도록 연구
- 사회적 책임 및 규범 확립
- 필터링되지 않은 웹 데이터에서 유해한 사회적 편향이 학습되었기 때문에, 이를 정확하게 분석하고 해결하는 것이 목표
Related Work (관련 연구)
- 자연어 감독을 훈련의 규칙으로 사용하는 연구
- 기존의 자연어 감독 (Natural Language Supervision)은 매우 넓은 영역을 포괄하고, NLP 분야는 자연어를 감독 신호로 활용하는 창의적인 방법들을 탐구해왔다.
- 이러한 NLP의 성공을 바탕으로 이미지에 대한 학습에도 이를 활용하고자 하는 것에 의의가 있다.
- 컴퓨터 비전에서의 자연어 활용
- 이전에도 이러한 시도들은 존재했다.
- Image Retrieval(Mori et al., 1999), Object Classification(Wang et al., 2009) 등
- 이전에도 이러한 시도들은 존재했다.
- 텍스트-이미지 검색 및 임베딩 공간 학습
- 연구 흐름 : 초기에는 예측 기반 목표에 초점을 맞췄지만, 시간이 지나면서 커널 CCA 및 랭킹 목표와 같은 기법을 사용하여 공동의 다중 모달 임베딩 공간을 학습하는 방향으로 전환
- CLIP의 목표 : 공동 임베딩 공간 학습 연구의 최신 형태이며, 대조학습을 사용하여 높은 효율성과 성능을 달성
- 시각-언어 공동 모델
- 기존 VL 모델들은 사전학습된 서브 시스템을 결합하는 형식이었다면, CLIP은 이미지 모델을 자연어 감독을 통해 처음부터 학습시키는 것에 초점을 맞췄다.
Conclusion (결론)
CLIP
- 자연어 처리 분야에서 웹 스케일 사전 학습의 성공 사례를 컴퓨터 비전으로 전이하는 것이 목표였다.
- CLIP 모델은 훈련 목표를 최적화하는 과정에서 사전 학습 기간 동안 광범위한 종류의 태스크를 수행하는 능력을 학습
- 태스크 학습 능력
- 자연어 프롬프트를 통해 발현되며, 많은 기존 데이터셋으로 Zero-shot 전이가 가능
쉽게 이해해보자..
- 기본적으로 CLIP은 주어진 이미지가 어떤 이미지인지 알려줄 수 있다.
- 하지만, 단순히 이미지가 어떤 이미지인지 알려주는 것을 넘어, 이미지 속의 내용을 문장 형식으로 설명하는 능력을 활용
- 이미지를 분류하기 위해 ‘문장 형식의 프롬프트’를 사용하기 때문에 분류의 기준 자체가 문장이다.
이미지에 대한 새로운 문장을 스스로 생성하는 것은 아님
이미지에 대한 새로운 설명을 생성하진 않지만, 막대한 데이터의 양을 통해 이 한계를 돌파하고자 한다.