PR [Vision-Language Models for Vision Tasks : A Survey]
Vision-Language Models for Vision Tasks : A Survey

Abstract
1 Introduction
- 이미지 인식 (Visual Recognition)은 Computer Vision 연구분야에서 다양한 산업에서의 적용을 위한 기초이다.
- 딥러닝의 등장으로 이미지 인식 연구는 엄청 성과를 이루었다. (하지만, 다음과 같은 과제를 남겼다.)
- 아무것도 없는 상태 (from scratch)에서부터 딥러닝 모델을 학습시키는 것은 굉장히 시간이 오래 걸린다.
- DNN을 학습시키기 위한 데이터셋을 확보하기가 힘들다.
- Pre-Training, Fine-Tuning and Prediction 방식의 등장
- DNN을 먼저 엄청난 양의 데이터를 통하여 사전 학습하며, 사전 학습 (Pre-Trained)된 모델은 특정 문제에 맞춰서 Fine-Tuned 된다.
⇒ 위에서 소개한 딥러닝의 등장이 남긴 과제를 해결하기 위한 과정을 가속화! (완전히 해결한 것은 아니고, 여전히 특정 문제에 (task-specific) 맞춰 fine-tuning 하는 것과, fine-tuning을 하기 위한 데이터를 확보하는 것에 대한 개선점은 아직 존재)
- Vision-Language Model Pre-training and Zero-shot Prediction
- 해당 방식의 등장으로 인해 VLM 모델은 (이미지-텍스트) 쌍으로 이루어진 대규모 데이터 셋을 통해 사전학습되며, fine-tuning 과정 없이도 다양한 task(분야?)에 적용이 가능했다.
- VLM의 pre-training 과정이 CLIP 모델과 같은 ‘대조학습’ 방식을 사용하여 vision-language의 유사성을 잘 포착하며, zero-shot prediction에 큰 기여
- ‘대조학습’ : 서로 맞는 이미지-텍스트 쌍은 최대한 가깝게, 맞지 않는 쌍은 최대한 멀게 설정
- zero-shot prediction : 훈련 과정에서 한 번도 배운 적 없는 클래스(class)나 레이블(label)에 속하는 데이터에 대해 예측하는 것
전이 학습 (Transfer Learning), 지식 증류 (Knowledge Distillation)과 같은 다양한 연구에 기여
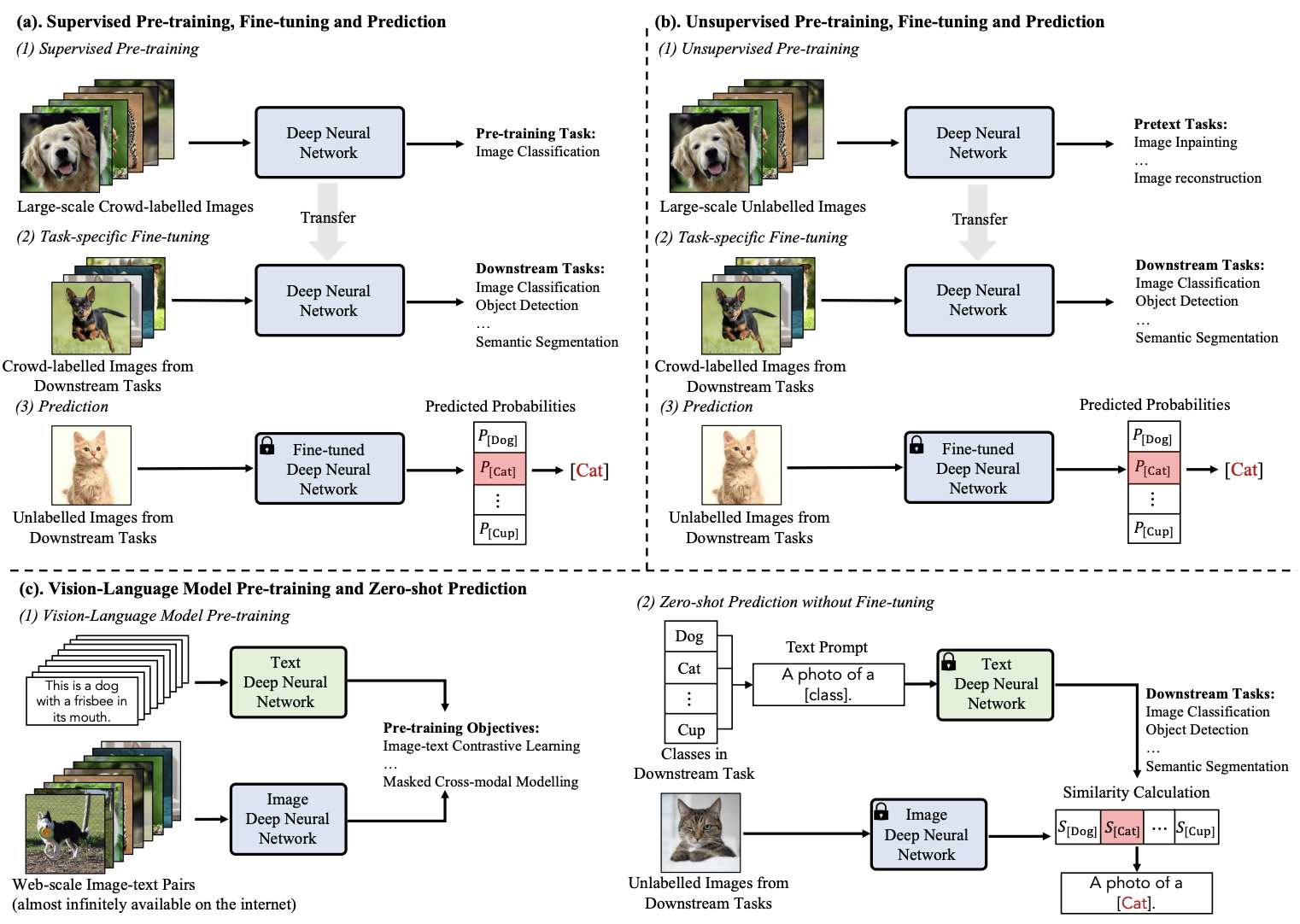
2 Background
2.1 Training Paradigms for Visual Recognition
이미지 인식 기술의 발전 5단계
- Traditional Machine Learning and Prediction
- Deep Learning from Scratch and Prediction
- Supervised Pre-training, Fine-tuning and Prediction
- Unsupervised Pre-training, Fine-tuning and Prediction
- Vision-Language Model Pre-training and Zero-shot Prediction
2.1.1 Traditional Machine Learning and Prediction
- 딥러닝 이전의 Visual Recognition
→ 사람이 ‘무엇을 봐야할지’ 미리 정해주고 학습시키는 방식으로 연구
2.1.2 Deep Learning from Scratch and Prediction
- 딥러닝의 등장
- End - to - End 학습 가능 (입력 데이터가 주어지면 사람의 개입없이 하나의 통합된 신경망 모델이 최종 출력까지 모든 것을 처리)
한계점❓ → 느림 수렴 속도 (학습속도?), 데이터 수집의 어려움
2.1.3 Supervised Pre-Training, Fine-tuning and Prediction
- 지도학습을 통해 사전학습된 모델을 Fine-Tuning하여 목적에 맞게 변화시키는 방식으로 발전
⇒ 모델의 학습속도를 가속화하고, 한정된 학습 데이터를 가지고도 좋은 성능을 기록
2.1.4 Unsupervised Pre-Training, Fine-tuning & Prediction
- 사전 학습 단계에서 많은 양의 라벨화된 데이터가 필요한 것을 막기 위하여, 정답이 없는 데이터로부터 훈련하고, 특징을 뽑는 비지도학습 방식이 등장
⇒ 이후, 목적에 맞게 Fine-Tuning하여 사용하는 방식으로 발전
2.1.5 VLM Pre-training and Zero-shot Prediction
- 자연어 처리 분야에서 영감을 받아, 인터넷에서 쉽게 수집할 수 있는 이미지-텍스트 쌍의 데이터를 통하여 vision-language에 대한 고차원적인 지식을 학습하고, Zero-shot predictions이 가능해졌다.
- 이후 VLM을 발전시키기 위한 시도
- 다양한 텍스트-이미지 데이터 활용
- 크고, 표현력이 풍부한 모델 개발
- 새로운 사전학습 목표 설계
2.2 Development of VLMs for Visual Recognition
이미지 인식을 위한 VLM 모델의 발전 과정
2.3 Relevant Surveys
- 지금까지 Visual Question Answering, Natural Language for Visual Reasoning, Phrase Grounding과 같은 분야에 대한 Survey만 존재하였음.
💡 해당 논문에서는..!
- 최근의 VLM 사전학습 방식
- VLM이 학습한 지식을 Visual Recognition에 적용하는 2가지 접근법
- Visual Recognition을 위한 VLM의 벤치마킹
3 VLM Foundations
3.1 Network Architectures
- VLM 사전학습은 ‘이미지와 텍스트의 핵심 특징을 잘 뽑아내는 딥러닝 네트워크를 만드는 과정’
- 텍스트/이미지 인코더 : 텍스트/이미지 샘플을 입력받아 텍스트/이미지 임베딩(숫자)으로 변환
3.1.1 Architectures for Learning Image Features
- 어떻게 이미지 특징 학습?
- CNN 기반의 아키텍쳐, Transformer 기반의 아키텍쳐
CNN-based Architectures
- VGG, ResNet, EfficientNet과 같은 합성곱 네트워크 (이미지 특징들을 학습하기 위해 설계)
- ResNet : 합성곱 블록들 사이에 skip connections 를 통하여 기울기 소실/폭발 문제를 완화하고, 더욱 더 깊은 딥러닝 모델을 가능하게 한다.
- skip connections : 이전 계층에서 나온 정보를 바로 다음 계층이 아니라, 몇 개의 계층을 건너뛰고 전달
- ResNet : 합성곱 블록들 사이에 skip connections 를 통하여 기울기 소실/폭발 문제를 완화하고, 더욱 더 깊은 딥러닝 모델을 가능하게 한다.
vision-language 모델링과 특징들을 더 잘 추출하기 위해서 다양한 연구가 이루어졌다.
- 예시) ResNet-D
- antialiased rect-2 blur pooling 사용
- antialiased rect-2 blur pooling? ⇒ 다운샘플링 과정에서 발생하는 계단 현상을 방지하는 기술
- global average pooling(전역 평균 필터) → attention pooling(어텐션 풀링) (transformer multi-head attention) 대치
- 이미지의 최종 특징 맵에서 중요한 부분에 더 높은 가중치를 부여
- antialiased rect-2 blur pooling 사용
Transformer-based Architectures
대표적인 Transformer 아키텍쳐를 가진 이미지 학습 모델인 ViT
- multi-head self-attention layer와 feed-forward network로 구성된 Transfomer 블록들을 층층이 쌓는다.
- multi-head self-attention layer : 이미지 정보들 간의 관계를 파악
- feed-forward network : multi-head self-attention layer에서 얻은 새로운 정보들을 개별적으로 처리/변환
- 이미지 분할 (Split into patches)
- 벡터화, 위치 정보 추가 (Linear Projection & Position Embedding)
💡 ViT 수정 내용 : 준비된 이미지 벡터들을 Transformer 인코더 처리 전에 정규화 계층 추가 (이 부분에!)
- Transformer 인코더 처리
3.1.2 Architectures for Learning Language Features
- 어떻게 텍스트 특징들을 학습?
- Transformer 아키텍쳐가 이를 담당하며, CLIP과 같은 모델들 또한 표준적인 Transformer 구조를 기반으로 한다.
3.2 VLM Pre-training Objectives
- VLM의 핵심으로써, VLM 사전학습 목표는 풍부한 vision-language 사이의 상관관계를 위해 설정되었음
- 크게 Contrastive Objectives, generative objectives, alignment objectives로 나뉜다.
3.2.1 Contrastive Objectives (대조학습 목표)
Image Contrastive Learning
- 서로 다른 이미지 특징들을 학습하는 것이 목표
임베딩 공간에서 positive keys(같은 이미지)와는 가까이, 그리고 negative keys(다른 이미지)와는 멀리
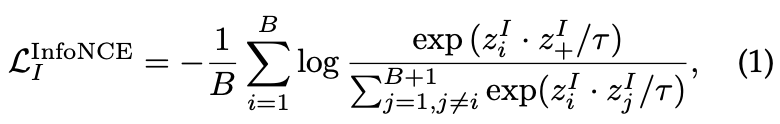
- τ : 학습의 강도를 조절하는 하이퍼파라미터
Image-Text Contrastive Learning
- 이미지 텍스트 VLM 대조 학습 방식
- 이미지 ↔ 텍스트 양방향으로 학습이 이루어지며, image-text infoNCE 손실을 최소화하는 방향으로 진행된다.
infoNCE ⇒ 많은 노이즈들과의 대조를 통해 정보량을 최대화하는 손실함수 (오답들 사이에서 하나의 정답을 구별하게 하여 오답들과 최대한 많이 비교하여 많은 정보량을 획득)
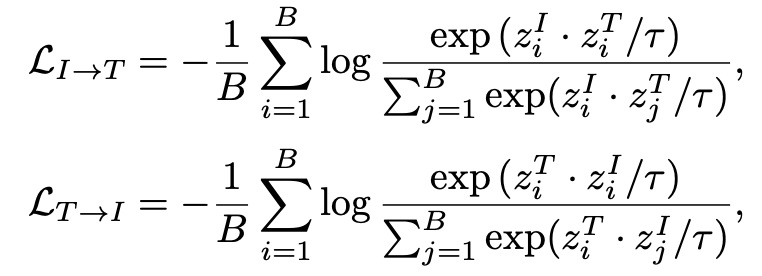
Image-Text-Label Contrastive Learning
- 이미지-텍스트 라벨 대조 학습은 위의 이미지 텍스트 대조 학습에 ‘지도’ 개념을 더하여 강화하였다.
- 원래 짝 (Image-Text)만을 정답으로 취급하던 방식에서, 같은 클래스 (라벨)에 속하는 모든 이미지와 텍스트를 정답으로 간주하도록 규칙 확장!
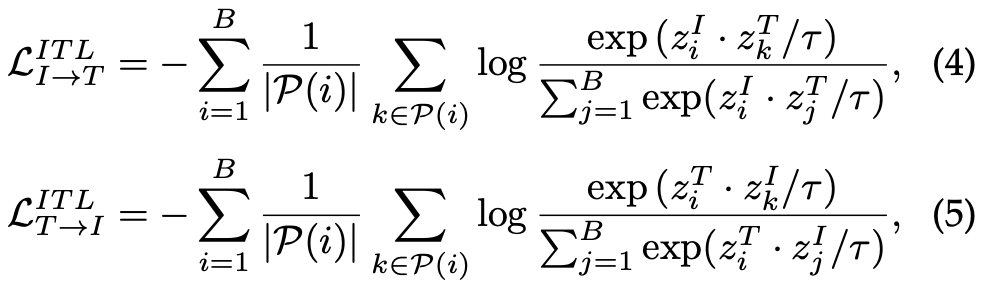
3.2.2 Generative Objectives
- 생성 학습 목표 (Generative Objectives)는 모델이 이미지/텍스트를 생성하는 과정에서 의미적 특징을 학습
Masked Image Modelling
- Cross-Patch 방식으로 이미지-텍스트의 유사도를 학습
Cross-Patch 방식 : 입력 이미지에 여러 패치들을 무작위로 설정하여 이미지를 일부분 가리고, 안가려진 부분을 토대로 가려진 부분을 채워나가는 과정!
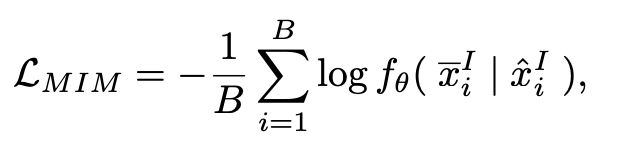
Masked Language Modelling
입력 텍스트 토큰들 중 일정 퍼센트를 마스킹하고, 마스킹되지 않은 토큰들을 토대로 다시 채워나간다.
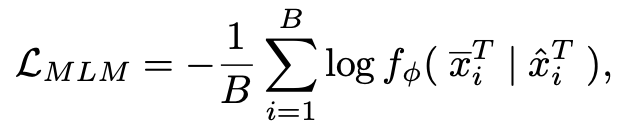
Masked Cross-Model Modelling
- 위에서 설명 2가지 방식을 통합
이미지-텍스트 쌍 데이터에서 이미지, 텍스트를 각각 무작위로 마스킹하고, 마스킹되지 않은 부분들을 토대로 다시 채워나간다.
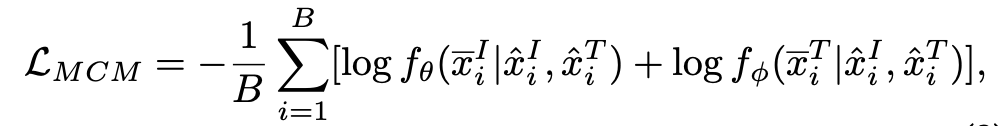
Image-to-Text Generation
- 이미지와 이전 문맥을 통하여 매 순간 다음 정답 단어를 가장 높은 확률로 예측하도록 훈련시킨다.
3.2.3 Alignment Objectives
- 정렬 목표 (Alignment Objectives)는 이미지-텍스트 쌍을 임베딩 공간에 두어서 global 매칭 혹은 region-word 매칭을 통해 이미지-텍스트를 정렬한다. (’정렬한다’ → [이미지,텍스트]가 동일한 의미를 공유하도록 만듦)
Image-Text Matching (전역적 매칭)
- global 상관관계를 아래와 같이 설정
- score 함수 S를 통하여 이미지와 텍스트 사이의 정렬확률(이미지와 텍스트가 서로 짝이 맞을 가능성)을 이진 분류 손실로 측정한다. (아래 식에서 p가 1이면 이미지와 텍스트가 서로 짝을 이루고, 0이면 이루지 않음)
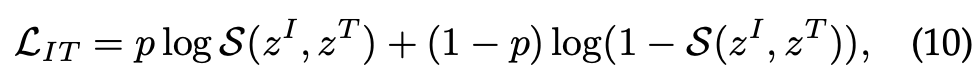
Region-Word Matching (지역적 매칭)
- local cross-modal 연관성(이미지의 일부분과 텍스트)를 측정 (특정 단어/구문 을 통하여 특정 영역/객체와 연결)
- 객체 탐지와 같은 분야에서 활용
3.3 VLM Pre-Training Frameworks
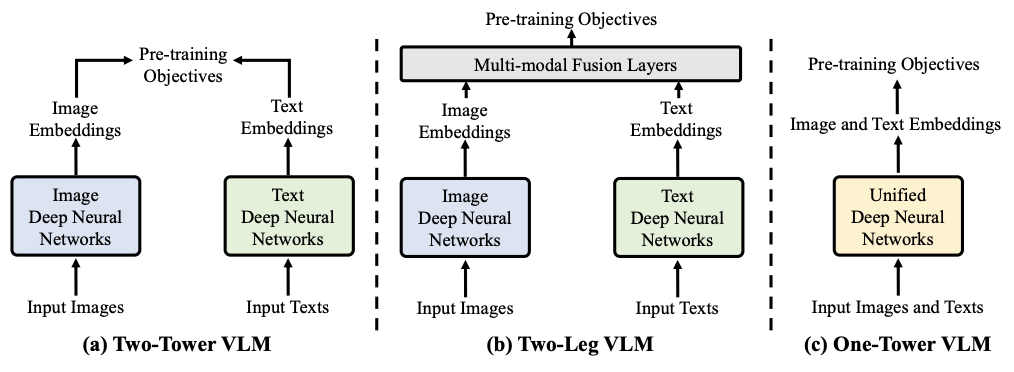
- two-tower 프레임워크가 VLM 사전학습에 가장 많이 활용된다.
- 이미지와 텍스트가 각각의 인코더에서 개별적으로 인코딩됨
- two-leg 프레임워크 (이것도 인코더가 각각 나뉘어있긴함)
- multi-modal fusion 계층을 추가하여 특징들 간의 상호작용을 가능하게 한다.
- one-tower 프레임워크
- 이미지와 텍스트를 하나의 인코더에서 통합하여 처리한다.
3.4 Evaluation Setups and Downstream Tasks
- VLM 모델들을 평가할때 가장 흔히 사용되는 방식 소개
3.4.1 Zero-shot Prediction
- zero-shot 예측은 사전 학습된 모델을 파인튜닝하지 않고도, 다양한 downstream 작업들(아래에 나오는)에 적용이 가능한지에 대해 평가하는 가장 흔한 방식이다.
Image Classification
Semantic Segmentation
Object Detection
Image-text Retrieval (이미지 텍스트 검색)
- 이미지를 가지고 관련된 텍스트를 찾음 / 텍스트를 가지고 관련된 이미지를 찾음
3.4.2 Linear Probing (선형 조사)
- 사전학습된 VLM 모델을 얼려서(절대 수정하지 않은 채로) VLM 자체가 얼마나 특징들을 잘 추출하는지 평가하는 방식
- 이미지 분류나, 행동인식 부분에 주로 활용된다.
4 Datasets
4.1 Datasets for Pre-Training VLMs
- crowd-labelled 데이터셋보다 image-text 데이터 셋이 더 확보하기 쉽고, 가격도 저렴
- image-text 데이터셋 말고도, 모델이 이미지의 지역적인 특징들을 잘 이해하기 위해 axuxiliary(부가의) 데이터셋을 활용하기 위한 연구들도 진행되었다.
5 Vision-Language Model Pre-Training
- VLM Pre-Training은 3가지의 학습 목표를 가지고 연구가 이루어졌다.
- Contrastive Objectives, Generative Objectives, Alignment Objectives
5.1 VLM Pre-Training with Contrastive Objectives
- 서로 다른 이미지 텍스트 특징들을 학습하기 위해 Contrastive Objectives를 설계
5.1.1 Image Contrastive Learning
- 이미지 양식에서 차별적인 특징들을 학습하는 것이 목표
- 이 방식은 이미지 데이터를 최대한 활용하기 위해 주 목표 외에 부가적인 목표로써 자주 활용
5.1.2 Image-Text Contrastive Learning
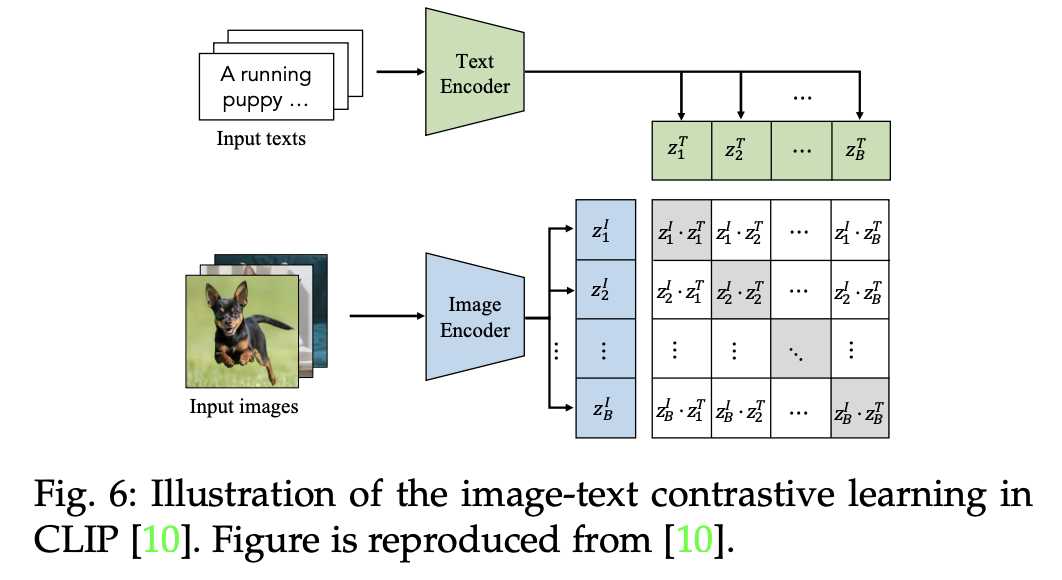
- Image-Text 대조는 이미지-텍스트 쌍의 거리를 가깝게하고, 서로 다른 이미지-텍스트의 거리는 멀게 설정함으로써 vision-language의 상관성을 학습
- 예시) CLIP
- 이미지와 텍스트의 임베딩 벡터들의 내적 (dot-product)을 통해 유사성을 측정
- 대칭적인 이미지-텍스트 infoNCE 손실 활용
- 대칭적인 이미지-텍스트 infoNCE? → (이미지→텍스트 방향의 점수, 텍스트→이미지 방향의 점수)
CLIP의 영향으로, ALIGN 모델은 18억개의 엄청난 양의 이미지-텍스트 쌍 데이터를 활용하여 사전 학습의 규모를 늘림
⇒ 해당 데이터 안에는 짝이 잘 맞지 않는 Noisy Data가 많이 섞임 (사전 학습에 있어서 데이터의 양으로 승부)
→ 노이즈에 강한 대조 학습 방법 사용
- ALIGN 처럼 양으로 사전 학습을 시키는 방식과, 데이터의 양은 적지만, 최대한의 정보를 뽑아내는 방식으로 사전 학습을 시키는 2가지 연구 동향이 나타남
- 양이 많지 않은 데이터를 효율적으로 사용하는 방법들
- DeCLIP : 최근접 이웃 supervision 제안
- 제한된 데이터 속, 비슷한 짝(이미지-텍스트)에서 효율적인 사전학습이 가능하도록 함
- OTTER : 가상의 (이미지-텍스트)짝을 만듦
- 사전학습시 필요한 데이터의 양을 줆임
- ZeroVL : 제한된 데이터 속에서 데이터를 최대한 활용
- 편향되지 않은 데이터 샘플링, 데이터 증강을 활용
- DeCLIP : 최근접 이웃 supervision 제안
- 대조 학습을 활용할때에 여러 단계로 나누어 활용하는 방식들 (Performing image-text contrastive Learning across various semantic levels)
- FILIP : 단어와 이미지의 각 부분들을 하나하나 비교하는 ‘지역적’ 방식 사용
- PyramidCLIP : 여러 개의 단계(이미지의 전체적인 부분 → 세부적인 부분를 추출하는 단계)로 나누어 대조학습을 활용하며, 단계들 사이의 Cross-level(수직적 정보 교환) 뿐만 아니라, 동일한 단계 내에서 Peer-level(수평적 정보교환) 방식을 모두 사용하여 학습
- 최근의 VLM 모델들은 이미지-텍스트 쌍으로 이루어진 데이터에 데이터 증강을 적용하여 학습하는 연구가 이루어지고 있음
- LA-CLIP, ALIP 모델 : 주어진 이미지에 대해 LLM을 사용하여 더 상세하고 풍부한 설명글(텍스트)를 생성하여 데이터의 질을 향상
- RA-CLIP : 이미지-텍스트 쌍을 학습할 때, 데이터 베이스에 의미적으로 관련된 다른 이미지-텍스트 쌍들을 불러와서 학습에 함께 활용
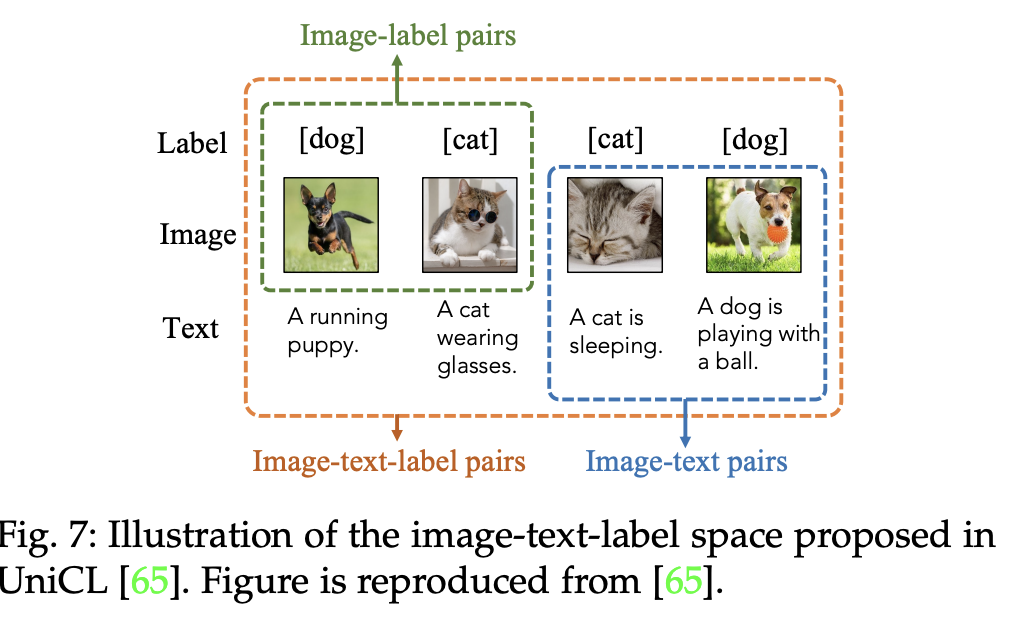
5.1.3 Image-Text-Label Contrastive Learning
- 해당 사전학습 방식은 이미지-텍스트 대조 학습 방식에 이미지 분류를 위한 라벨을 활용하는 방식
- 이미지 라벨을 활용하는 지도학습과 이미지-텍스트 쌍 데이터를 활용하는 VLM 비지도 학습 방식을 모두 활용
UniCL : Discriminative Features (범용적 특징, 다른 데이터들과 구별하도록 돕는 특징), Task-Specific(특정 목적에 맞도록 구분을 돕는 특징)
5.1.4 Discussion
- 대조 학습 (Contrastive Learning)
- 서로 맞는 이미지-텍스트 쌍은 서로 같은 임베딩 부여, 다른 이미지-텍스트 쌍은 서로 다른 임베딩 부여
- 이미지를 구별하는 특징, 그에 맞는 텍스트에 대한 특징들을 VLM에게 제공
- Zero-Shot 예측에 큰 기여
- 대조학습 방식의 한계점
- Positive, Negative 이미지 텍스트 쌍을 정확하게 가까이하고, 멀리하는 것(최적화)이 복잡
- 특징의 판별력을 조절하는 temperature(온도) 하이퍼파라미터에 크게 의존
- 이 temperature(온도) 하이퍼파라미터를 정하는 방식이 경험에 의존하는 비과학적 방식임
5.2 VLM Pre-training with Generative Objectives
- 생성적 VLM (이미지와 텍스트 입력을 바탕으로 새로운 콘텐츠를 생성하는 모델) 을 사전학습하는 방식
- 이미지 마스킹 방식, 텍스트 마스킹 방식, 이 2가지를 모두 활용하는 cross-modal modelling
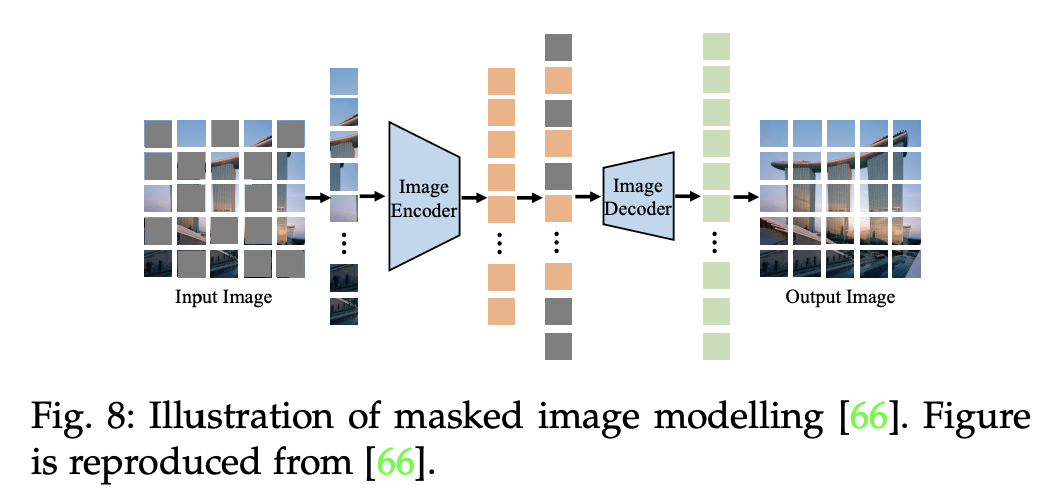
5.2.1 Masked Image Modelling
- 자기지도 학습 방식으로써, 이미지의 일부분을 마스킹 처리한 후, 인코더가 해당 부분을 예측하고 복원하도록 훈련시킴 (마스킹 안된 부분을 기반으로!)
- FLAVA : BeiT 모델에서처럼, 직사각형 모형의 블록으로 마스킹하는 방식을 채택
- KELIP, SegCLIP : 이미지 패치의 75%을 마스킹하여 모델을 학습시킴
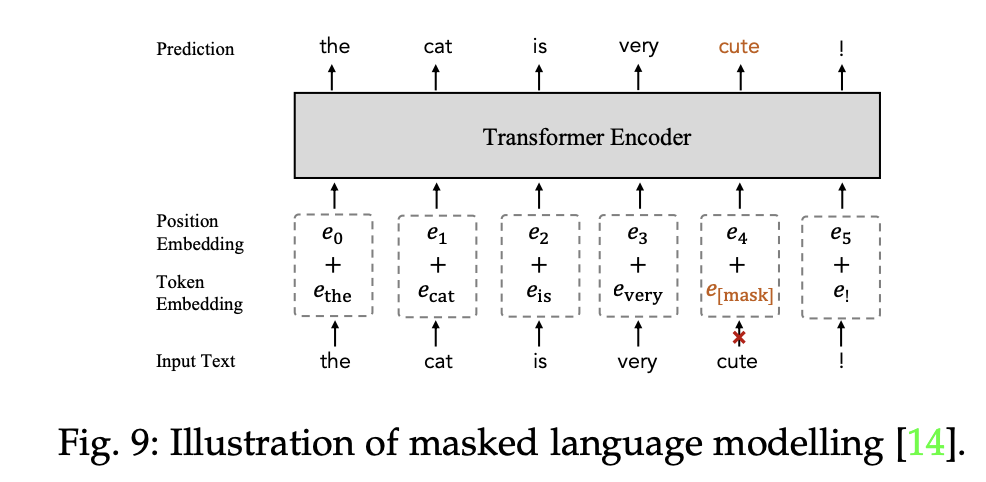
5.2.2 Masked Language Modelling
- 이미지 마스킹과 같이 문장의 일부 토큰을 마스킹하고, 마스킹된 텍스트 토큰을 예측하도록 학습
- FLAVA : 텍스트 토큰의 15%를 마스킹, 나머지 텍스트 토큰들을 바탕으로 마스킹된 텍스트 토큰을 예측하도록 학습
- FIBER : 더 좋은 언어특징 (Language Feature)를 학습하기 위해 Masked Language Modeling 방식채택
5.2.3 Masked Cross-Modal Modelling
- Masked Cross-Modal 방식
- 이미지 패치의 일부분을 마스킹, 텍스트 토큰의 일부분을 마스킹하여 VLM이 마스킹된 이미지 패치, 텍스트 토큰들을 마스킹되지 않은 부분들을 활용하여 복원하도록 학습
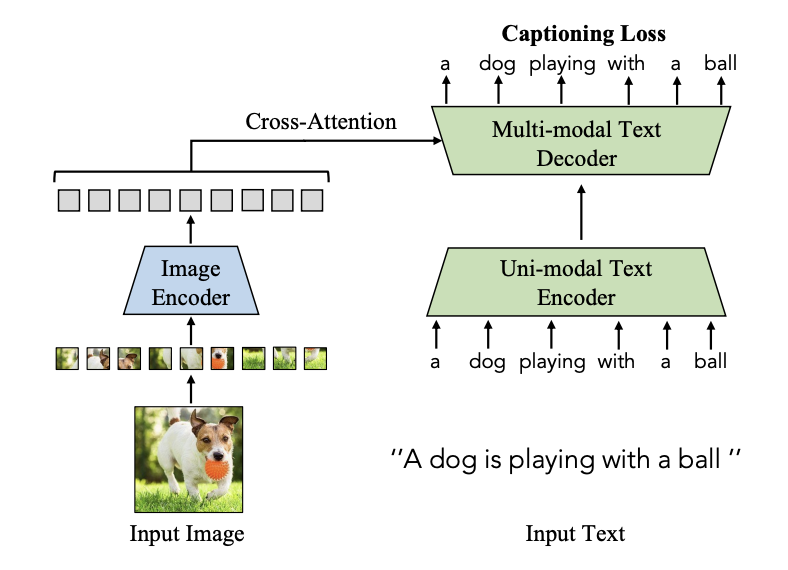
5.2.4 Image-to-Text Generation
- 주어진 이미지에 부합하는 텍스트를 생성하는 것이 목표
- VLM을 토큰화된 텍스트를 예측하도록 학습하여 Vision-Language Correlation(시각-언어 상관관계)의 세부적인 특징들까지 포착하도록 함
- 우선 입력된 이미지를 모델이 이해할 수 있는 숫자 벡터 형태(Intermediate Embedding)으로 바꾸고, 해당 이미지에 맞는 텍스트로 디코딩하여 문장 생성
- 텍스트 디코더가 문장을 생성하는 매 순간마다 이미지로부터 필요한 시각적 힌트를 참고! 라고 생각하자
5.2.5 Discussion
- 생성적 VLM 모델을 사전학습하는 방식은 이미지-언어의 특징들을 풍부하게 학습할 수 있기 때문에 다른 VLM의 사전학습 방식에도 추가적으로 사용되곤한다.
- 이미지/텍스트/Cross-Modal 마스킹 방식은 이미지-언어의 세부적인 특징들까지 학습하기 때문에 zero-shot 예측에 더 강함
5.3 VLM Pre-Training with Alignment Objectives
- 주어진 텍스트가 이미지를 잘 설명하고 있는지, 이미지에 부합하는 설명인지 예측하기 위해 이미지와 텍스트들을 정렬하는 것을 VLM의 목표로 삼는다.
5.3.1 Image-Text Matching
- 이미지-텍스트 매칭 방식
- 이미지 전체와 텍스트 전체를 보고 (Global image-text Correlation)을 이미지-텍스트 사이의 상관관계 (이미지와 텍스트가 쌍이 맞는지)를 예측하도록 함
- FLAVA 모델은 이미지-텍스트 쌍으로 이루어진 데이터들을 서로 쌍이 맞게 매칭함 (분류, 이진분류 손실을 통해)
- FIBER 모델 : 서로 맞지 않은 이미지-텍스트 쌍을 구분하는 강한 부정적인 특징들을 학습하도록하여 이미지와 텍스트들을 더 잘 정렬할 수 있도록 함
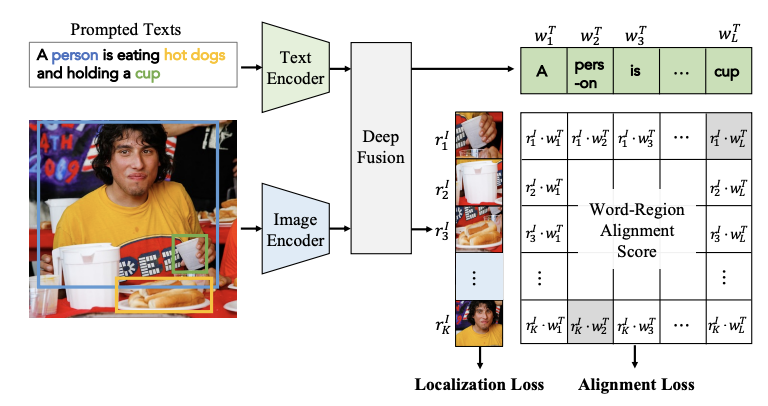
5.3.2 Region-Word Matching
- 이미지 전체가 아닌 일부분과, 텍스트의 일부분을 서로 맞게 정렬하는 것을 목표로 하여 이미지와 텍스트의 지역적인 상세한 특징들을 학습하도록 함
- zero-shot 예측에서도 좋은 예측력, 객체 탐지나 영상 분할 분야에서도 좋은 예측력을 가짐
- GLIP, FIBER, DetCLIP 모델들 모두 객체를 분류할때 활용하는 logits(모델의 최종 확률을 만들기 전의 데이터)을 지역적 이미지-언어 정렬 점수로 대체
- 영역-단어 정렬 점수 : 이미지와 텍스트의 지역적 특징들의 유사성을 내적한 점수
5.3.3 Discussion
- 이미지-텍스트가 서로 맞도록 정렬하는 Alignment Objectives는 이미지 데이터와 텍스트 데이터가 서로 맞는지에 대해 예측하도록 학습
- 장점
- 이미지와 텍스트 사이의 세밀하고 정교한 상관관계들을 잘 학습함
- 단점
- 이미지와 텍스트 사이의 관계에만 집중하기 때문에, 이미지 내부의 관계 (이미지 내에서 눈, 코 사이의 관계), 텍스트 내부의 관계(문법적 관계)를 잘 학습하지 못함
- 장점
⇒ 따라서 Alignment Objectives (정렬 목표)는 단독으로 사용되기보다는 다른 VLM 사전 학습에 추가되는 보조 손실로 자주 사용됨
5.4 Summary and Discussion
💡 VLM 사전 학습 모델
⇒ 이렇게 2가지의 연구 흐름이 VLM 연구의 큰 축을 이루고 있다.
6 VLM Transfer Learning
6장에서 소개할 것들
- 사전학습된 VLM의 전이학습 방식에 대한 동기
- 전이학습을 위한 기본적인 구성
- 3가지 전이 학습 접근법
6.1 Motivation of Transfer Learning
- 사전학습된 VLM 모델들이 다양한 다운스트림 작업에 적용될때 다음과 같은 2가지 차이점에 부딪힘
- 이미지와 텍스트 데이터의 분포 차이
- 데이터가 특정 이미지 스타일과 텍스트 형식을 가지고 있을 수 있음
- 학습 목표의 차이
- VLM 의 사전 학습 목표는 특정 작업에 얽매이지 않고, 범용적인 지식을 학습하도록 설정되지만, 실제 작업은 이미지 분류, 객체 탐지처럼 비교적 구체적이기 때문!
- 이미지와 텍스트 데이터의 분포 차이
6.2 Common Setup of Transfer Learning
- 전이 학습의 기본적인 구성 (3가지가 있음)
- Supervised Transfer (지도 전이 학습)
- 라벨(정답)이 있는 다운스트림 데이터 전체를 사용하여 미세 조정
- Few-shot Supervised Transfer ( 적은 데이터를 활용한 지도 전이 학습 )
- 아주 적은 수의 라벨이 있는 다운스트림 샘플만을 사용하여 미세조정
- Unsupervised Transfer (비지도 전이학습)
- 라벨 (정답)이 없는 다운스트림 데이터를 활용하여 미세 조정
- 3가지 방식 중 가장 어렵지만, 가장 유망하고 효율적임
- 최근에는 비지도 전이학습에 대한 연구가 활발함!
- Supervised Transfer (지도 전이 학습)
6.3 Common Transfer Learning Methods
- 기존에 존재하는 VLM 전이학습 방식을 3가지의 카테고리로 나눔
6.3.1 Tansfer via Prompt Tuning
- 자연어 처리 분야의 ‘prompt learning’에서 영감을 받은 방식
- 전체 VLM 모델을 미세조정하기 보다는, 다운스트림에 맞게 VLM을 조정하기 위해 최적의 프롬프트를 찾는 것 (이에 대해 아래와 같은 3가지 방향의 연구가 존재)
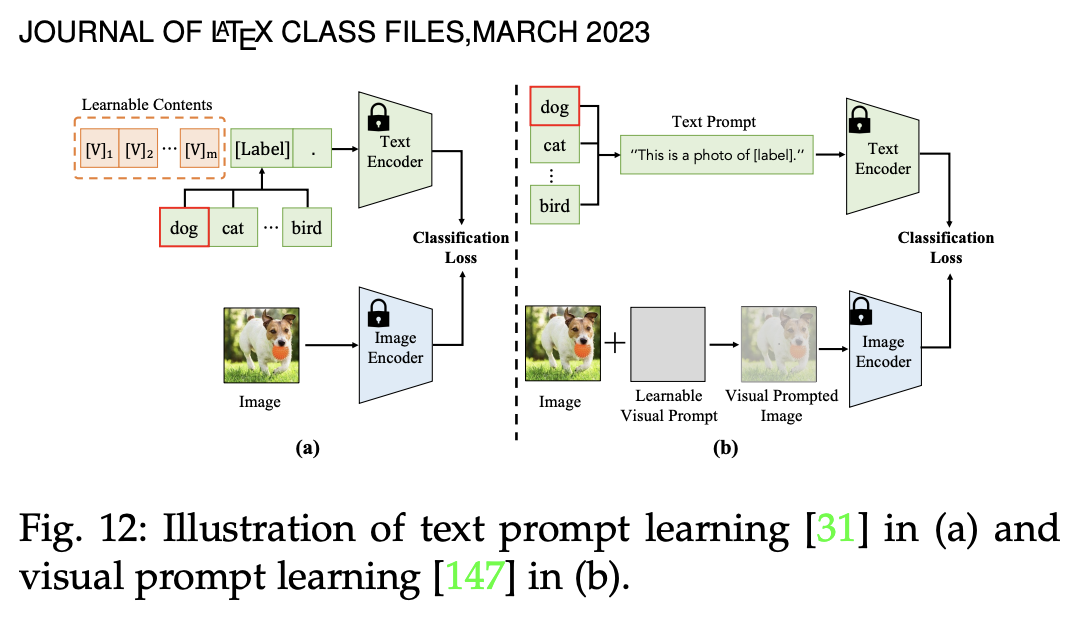
💡 Text Prompt Tuning
- 사람이 직접 프롬프트를 만드는(프롬프트 엔지니어링) 대신, 라벨이 있는 다운스트림 샘플들을 이용하여 최적의 프롬프트를 학습하는 방식
- 쉽게 이해해보자면,,
꽃 종류 3가지를 분류하는 다운스트림 작업이라면, 각각의 꽃 종류(장미, 튤립, 등)의 라벨이 있는 데이터 몇개를 샘플로 활용하여 3가지 꽃을 가장 잘 분류하는 최적의 프롬프트를 찾음 - 여기서 프롬프트는 모델이 최적화된 숫자 벡터들의 조합임
- 쉽게 이해해보자면,,
- CoOp 모델 (해당 기술의 초기 모델)
- 학습 가능한 단어 벡터를 사용하여 각 클래스 이름에 최적화된 문맥을 학습하는 방법 제안
- 과적합 방지 방식
- CoOp 모델은 모든 이미지에 동일한 학습된 프롬프트를 부여, 과적합 발생 위험이 높음
⇒ 입력되는 이미지 각각에 맞춰 동적으로 다른 프롬프트를 생성하는 방법 제안
- CoOp 모델은 모든 이미지에 동일한 학습된 프롬프트를 부여, 과적합 발생 위험이 높음
- 학습 가능한 단어 벡터를 사용하여 각 클래스 이름에 최적화된 문맥을 학습하는 방법 제안
- 그 이외의 개선 방법들
- SubPT 모델 : 프롬프트의 일반화 성능을 높이기 위한 부분 공간 개념 도입
- LASP : 학습 가능한 프롬프트가 너무 엉뚱한 방향으로 학습되지 않게 ‘규제’ 도입
- VPT : 일반화 성능을 위한 각 이미지에 맞는 ‘프롬프트 분포’ 모델링
- KgCoOp : 학습 때 보지 못한 새로운 클래스에 대한 일반화 성능 향상
- SubPT 모델 : 프롬프트의 일반화 성능을 높이기 위한 부분 공간 개념 도입
💡
Visual Prompt Tuning
- VLM 을 새로운 작업에 적용할 때, 텍스트 입력이 아닌 이미지 인코더의 입력을 조절하는 방식
- VLM 모델의 사전학습된 가중치는 수정하지 않고, 이미지 인코더에 들어가는 입력 데이터만 조정
- VLM 모델에 입력으로 활용되는 이미지 데이터 패치들 사이에 학습 가능한 패치(비주얼 프롬프트 벡터) 추가
- 학습 가능한 패치?
- 데이터가 아님! 모델의 파라미터라고 생각!
- 처음에는 그냥 무작위 숫자로 시작해서 훈련을 통하여 해당 숫자가 모델의 목적에 맞게 조금씩 조정됨
⇒ 이 숫자들은 학습이 끝나면 현재 특정 다운스트림 작업에 가장 최적화된 상태가 됨!
💡 Text-Visual Prompt Tuning
텍스트 프롬프트 튜닝 + 비주얼 프롬프트 튜닝
- 입력 이미지와 텍스트를 동시에 조절
- Visual Prompt Tuning처럼 이미지 패치 사이에 학습 가능한 비주얼 프롬프트 벡터 추가
- 똑같이 입력된 텍스트에도 학습 가능한 텍스트 프롬프트 벡터를 끼워 넣음
⇒ 학습이 진행되면서 텍스트, 이미지 데이터에 끼워져있는 프롬프트 벡터가 각각 특정 다운스트림에 가장 최적화된 상태로 학습이됨!
⇒ 이미지/텍스트 2가지 방식이 함께 협력하여 최종 손실을 가장 효과적으로 줄일 수 있는 방향으로 함께 조정
Discussion
- 프롬프트 튜닝 : 파라미터 효율적임! (거대한 딥러닝 모델의 아주 작은 일부 파라미터만 훈련 or 수정)
- 계산량이 적음
- 활용하기 쉬우며, 간단함 (추가적인 네트워크 레이어/네트워크 레이어의 변경 이 필요하지 않음)
- 고정된 프롬프트가 새로운 이미지와 잘 맞지 않아 예측 성능이 저하되는 융통성 부족의 한계는 아직 존재
- 고정된 프롬프트? : 특정 다운스트림 작업에 맞춰 프롬프트가 학습되었기 때문에 새로운 분야의 이미지에는 성능이 낮음
6.3.2 Transfer via Feature Adaptation
Feature Adaptation (특징 적응?)은 VLM이 이미지나 텍스트 특징들에 적응하도록 파인튜닝하는 방식 전이학습의 방식 중 하나
- 추가적인 light-weight 특징 adapter 모듈을 활용
- Clip-Adapter : 기존의 CLIP 모델의 텍스트, 이미지 인코더 뒤에 학습 가능한 선형 레이어를 여러개 삽입
- 새롭게 삽입된 선형 레이어들만 다운스트림 데이터로 학습, CLIP이 추출한 특징을 변환
- SVL-Adapter : 입력된 이미지에 대한 자기지도학습을 하는 추가적인 인코더를 아답터로 활용
결론 : 특징 적응기(feature adapter)는 VLM이 다운스트림 데이터에 적응하도록 하며, 앞서 소개한 전이학습 방법 프롬프트 튜닝의 대안으로 떠오르고 있음
Discussion
- Feature Adaptation
- 장점 : 해당 전이학습 방식이 굉장히 융통성(다양한 다운스트림 작업에 활용 가능)이 있으며, 효과적임
- 단점 : 네트워크의 구조를 수정해야하며, 데이터에 대한 지적 재산권 문제를 다룰 수 없다.
6.3.3 Other Transfer Methods
- 위에서 소개한 방법 이외에도 다양한 전이학습 방법이 존재
- Wise-FT : 원본 VLM의 가중치와 미세 조정된 VLM의 가중치를 결합하는 방식
- Mask-CLIP : 이미지 인코더 아키텍처를 수정, 이미지 전체에 대한 풍부한 이미지 특징 추출
- VT-CLIP : 시각적 유도 어텐션 도입
- CuPL & VCD : GPT-3와 같은 LLM을 활용하여 단순한 텍스트 프롬프트를 더 상세한 프롬프트로 확장
6.4 Summary and Discussion
- VLM의 전이 학습 방식의 가장 메인이 되는 방식 2가지
- Prompt Tuning
- Feature Adapter
- 지금까지는 few-shot 지도 전이학습에 대한 연구가 활발했다면, 최근에는 비지도 전이 학습에 대한 연구가 활발하게 이루어지고 있다.
7 VLM Knowledge Distillation
- VLM 지식 증류
- 사전학습된 VLM은 다양한 시각 및 텍스트 개념을 포괄하는 범용적인 지식을 가지고 있음
- 하지만, 객체 탐지, 영상 분할과 같은 ‘조밀한 예측’(Dense Prediction)은 픽셀 단위의 이해를 요구함
⇒ 어떻게 VLM이 가지고 있는 시각, 텍스트에 대한 범용적인 지식을 조밀한 예측 작업을 위해 설계된 모델에 전달(증류)할 수 있을까?
7.1 Motivation of Distilling Knowledge from VLMs
- 지식 증류와 전이 학습의 차이점
| 지식 증류 (Knowledge Distillation) | 전이 학습 (Transfer Learning) |
|---|---|
| VLM의 ‘지식’만을 가져와 완전히 다른 구조를 가진 모델에게 전달 (VLM 아키텍처에 얽매일 필요 X) | 기존의 사전학습된 VLM 아키텍처는 그대로 둔 상태에서 일부 작은 부분만 수정/추가하여 새로운 작업에 적응시킴 |
| Faster R-CNN, DETR 같은 탐지 모델의 아키텍처의 장점을 살리면서 VLM 지식을 전달하는 것이 가능! | 만약 다운스트림 작업이 원본 VLM 아키텍처에 적합하지 않아도 그 구조를 무조건 따라야함 |
7.2 Common Knowledge Distillation Methods
대부분의 지식 증류 방식은 이미지 전체에 대한 지식 수준을 이미지의 일부(지역적) 혹은 픽셀 단위의 작업(더 세밀한 작업들)들을 해결하는 모델에 전달하는 방식임 (객체 탐지(Object Detection) or 영상 분할(Semantic Segmentation))
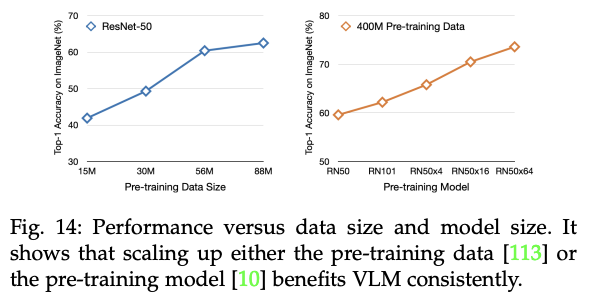
7.2.1 Knowledge Distillation for Object Detection
Open-Vocabulary Object Detection
- 일반적인 객체 탐지 모델 : ‘개’, ‘자동차’ 등 정해진 클래스만 알기 때문에 어휘력이 제한적
- CLIP과 같은 VLM 모델들은 인터넷의 수십억 개의 이미지-텍스트 쌍으로 학습되었기 때문에 어휘력이 더 넓음!
- ViLD, ZSD-YOLO, OADP 모두 객체 탐지 성능을 높이기 위해 VLM의 방대한 지식을 증류(전달)받음
⇒ VLM의 이 방대한 지식을 기존 객체 탐지 모델에 증류(전달)하는 방법을 연구
Prompt Learning을 통한 지식 증류를 연구
- ‘프롬프트’를 학습하는 방식으로, VLM의 지식을 탐지기에 전달
VLM이 생성한 가상 라벨 활용
- 이미 학습된 VLM을 일종의 ‘자동 라벨링 기계’로 사용하여 객체 탐지 학습에 필요한 데이터를 생성
7.2.2 Knowledge Distillation for Semantic Segmentation
- 영상 분할(Semantic Segmentation)을 위한 지식 증류 방법
- 객체 탐지와 마찬가지로, 이미지의 픽셀이 설명하고 있는 클래스 목록의 범위를 확장하기 위해 (어휘력 향상)
- CLIPSeg : 영상 분할만을 위한 모델로써, 가벼운 트랜스포머 디코더를 추가
- LSeg : CLIP의 텍스트 임베딩과 픽셀 단위의 이미지 임베딩 사이의 상관관계를 최대화
Knowledge Distillation for weakly-supervised semantic (약한 지도 학습 환경에서의 VLM의 지식 증류)
- 약한 지도 (weak-supervision) 이란?
- 정교한 픽셀 단위의 정답 없이, 이미지 레벨의 라벨과 같이 불완전하고 약한 형태의 정답만을 활용
- 강한 지도 : 사진 속에 소파, 고양이를 픽셀 단위로 특정 지어줌
- 약한 지도 : 그냥 이미지 전체에 대한 설명 (고양이와 소파야)
- 약한 지도의 가장 큰 한계점 : 이미지 내에 특정 객체가 있다는 정보만으로 ‘어떤 픽셀’이 그 객체를 나타내고 있는지 알기 힘듦
⇒ 클래스 활성화 맵의 품질을 높이는 데 VLM의 지식을 활용 (클래스 활성화 맵 : 모델이 특정 픽셀을 객체로 판단할때, 이미지의 어느 부분을 주로 보았는지를 보여주는 히트맵)
- CLIP-ES, CLIMS
7.3 Summary and Discussion
- 전이학습과 비교해보았을떄, 지식 증류 방식은 더 융통성이 있으며, 원본 VLM의 구조에 구애받지 않고 다양한 다운스트림 작업에 적용 가능
- 대부분의 지식 증류 연구는 객체 탐지 혹은 영상 분할 작업을 다루고 있다.
8 Performance Comparison
8.1 Performance of VLM Pre-Training
- 사전학습된 VLM 들이 어느 정도의 성능을 보여주는지 Zero-shot Prediction(제로샷 예측) 평가 방식을 통해 비교/분석
- 평가 방식 : 모델을 추가로 fine-tuning하지 않고, 사전 학습만 된 상태로 평가
평가 항목 : 이미지 분류, 객체 탐지, 영상 분할 등 여러 종류의 시각 인식 작업에 대해 평가
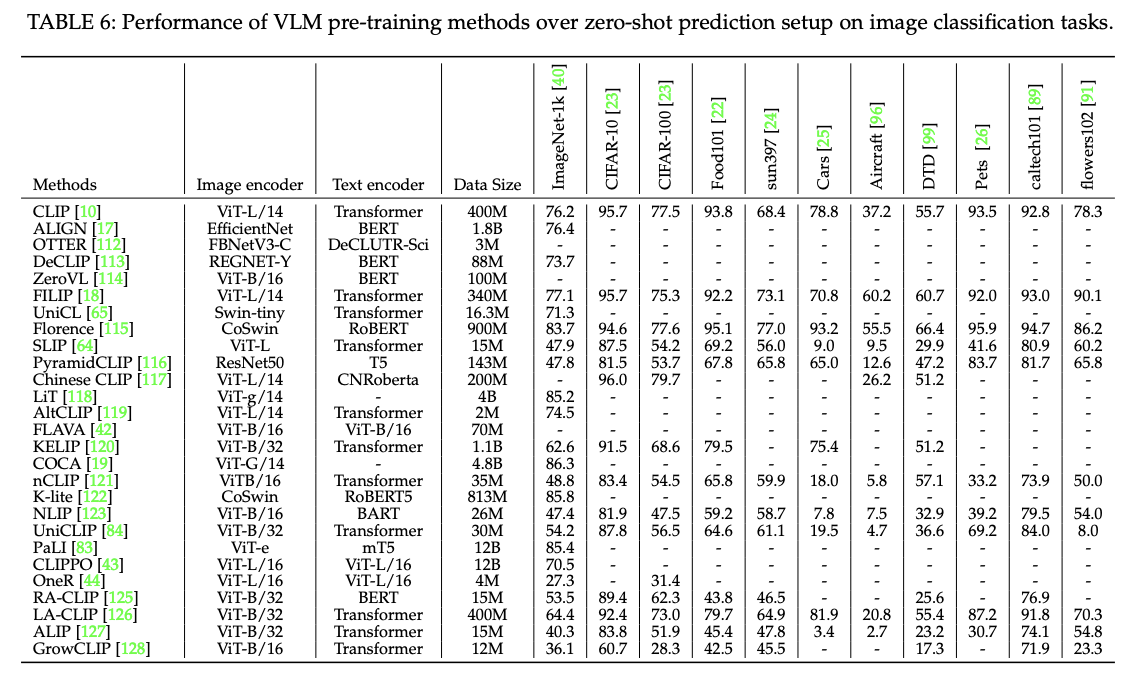
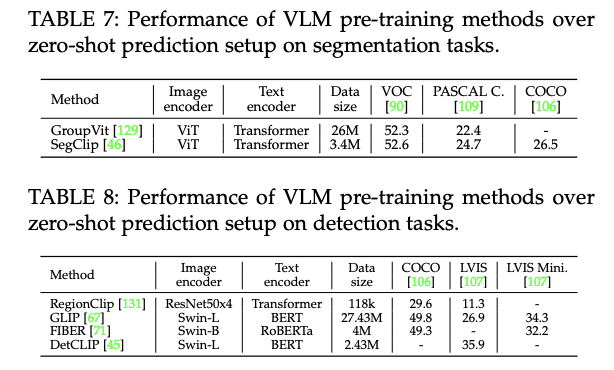
- 위의 테이블 7,8을 통해서도 알 수 있듯이, 특정 작업 (객체 탐지, 영상 분할) 분야에서도 좋은 성능을 보임
- 숫자가 낮다고 생각했지만,, 제로샷 예측 평가라는 매우 어려운 조건하에서 달성된 점수이며, 객체 탐지나 영상 분할과 같은 특정 작업에 fine-tuned되지 않은 상태라는 것을 감안했을때, 좋은 성능이라고 볼 수 있다.
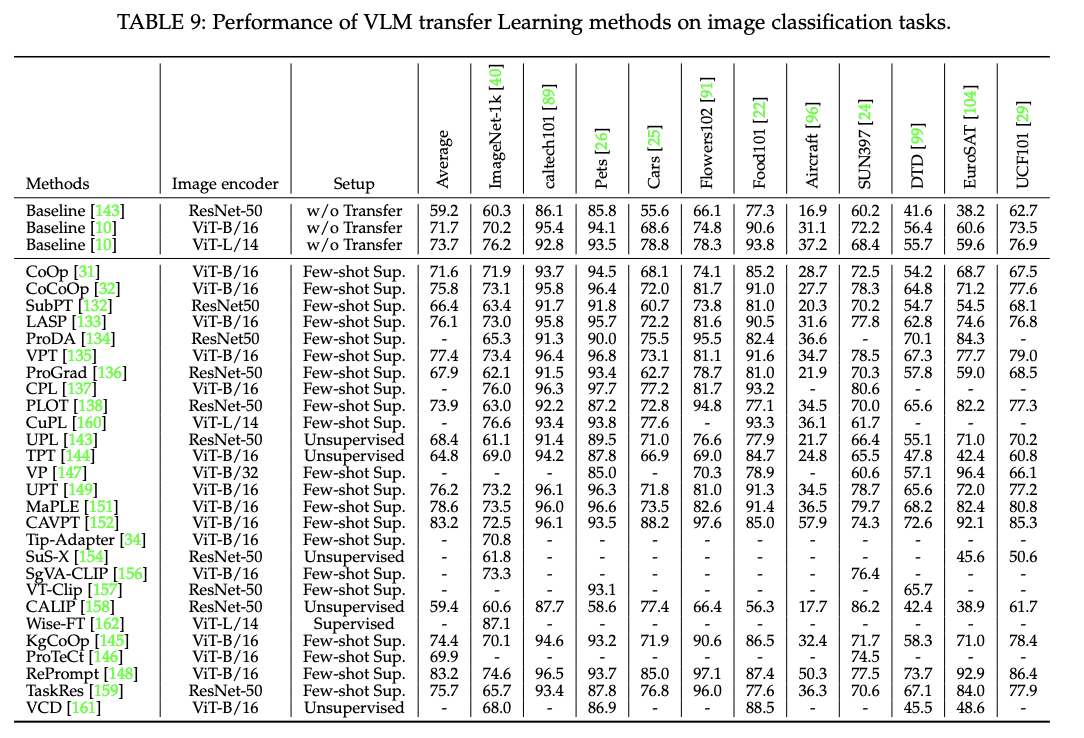
8.2 Performance of VLM Transfer Learning
- VLM 전이학습의 성능
- 지도 전이학습, few-shot 지도 전이학습, 비지도 전이학습 방식으로 나누어 진행
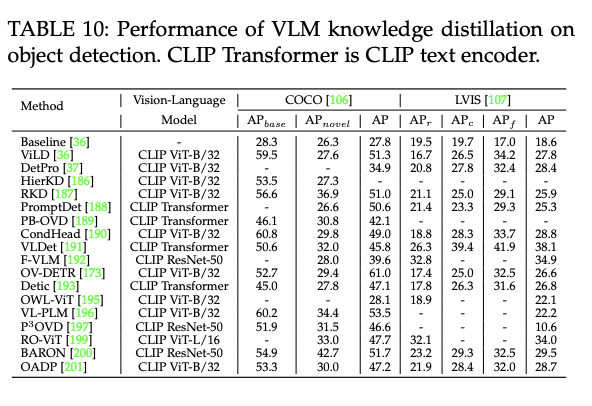
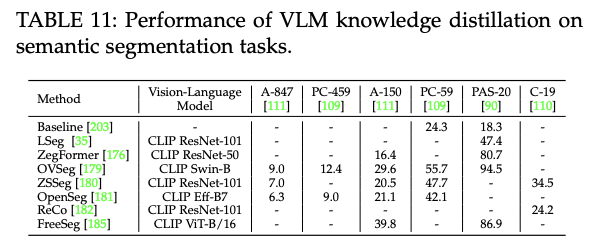
8.3 Performance of VLM Knowledge Distillation
- VLM 지식 증류 방식의 성능
- 어떻게 객체 탐지/영상 분할 분야에서 지식 증류가 도움을 줄 수 있는지 확인
- 객체 탐지에 가장 많이 사용되는 데이터셋, 영상 분할에 가장 많이 사용되는 데이터셋 활용

8.4 Summary
9 Future Directions
- VLM 사전 학습 (Pre-Training)의 미래 연구 방향
- 세밀한 시각-언어 상관관계 모델링 - 이미지 전체가 아닌 특정 부분(픽셀/패치)과 텍스트를 연결
- 시각과 언어 학습의 통합 - 하나의 통합된 Transformer인코더 안에서 이미지-텍스트 한번에 처리
- 다중 언어를 사용한 사전 학습 - 영어 중심이 아닌 다양한 언어로도 사전 학습 가능(문화적, 지역적 편향)
- 데이터의 효율성 - 더 적은 데이터로도 훈련 가능해야함
- LLM의 활용 - LLM을 활용하여 더 풍부하고 정확한 텍스트 설명을 생성하여 이를 활용해야함
- VLM 전이 학습 (Transfer Learning)의 미래 연구 방향
- 비지도 VLM 전이 학습
- 데이터에 의존하며, 과적합 위험이 있는 지도/소수샷 학습을 넘어 라벨이 없는 상태에서도 학습이 가능해야함 (이 분야 더 연구가 필요하다!!!)
- 테스트 시점 VLM 전이 학습
- 각 다운스트림 작업마다 훈련을 따로 해야하는 비효율을 극복하기 위해, 예측을 수행하는 테스트 시점에서 즉석으로 프롬프트를 적응시킬 수 있어야함
- LLM을 활용한 VLM 전이학습
- 사람이 직접 프롬프트를 만들거나, 데이터로 학습하는 대신, LLM을 통해 다운스트림 작업을 가장 잘 설명하는 프롬프트를 자동으로 생성하는 연구 필요
- 비지도 VLM 전이 학습
- VLM 지식 증류 (VLM Knowledge Distillation)의 미래 연구 방향
- 다수의 VLM로부터 지식 증류
- 하나의 VLM이 아닌, 여러 VLM모델로부터 지식을 전달 받을 수 있어야함
- 다른 시각 인식 작업으로의 확장
- 객체 탐지, 영상 분할 이외에 사람 재식별, 인스턴스 세분화 등 더 넓은 시각 인식 작업에도 적용될 수 있어야함
- 다수의 VLM로부터 지식 증류
10 Conclusion
- VLM의 핵심 가치
- 시각 인식을 위한 VLM은 웹 데이터를 효과적으로 사용할 수 있으며, 특정 작업에 대한 파인튜닝 없이도 제로샷 예측이 가능함
⇒ 구현이 간단하면서도 광범위한 시각적 인식 작업에서 큰 성과
- VLM 데이터셋, 접근법, 성능에 대한 정보를 요약하여 VLM 사전 학습의 최근 발전에 대한 전체적인 그림을 파악할 수 있으며, VLM의 앞으로의 연구 방향을 제시