PR [A Survey on Multimodal Large Language Models]
A Survey on Multimodal Large Language Models

Abstract
- LLM을 활용한 멀티 모달 task들은 GPT-4V 이후로 큰 주목을 받고 있다.
- 해당 논문에서는 MLLM (Multimodal Large Language Models)의 최근 행보를 요약하고 추적하는 것을 목표로 삼는다.
- MLLM의 기본구조와 관련된 개념들(아키텍처 등)을 구체화하고, 학습 과정과 데이터, 평가
- 어떻게 MLLM이 다양한 분야로 확장될 수 있는 지?
- Multimodal의 할루시네이션(hallucination)과 M-ICL, M-CoT등과 같은 확장된 기술들
- 향후 연구 방향과 존재하는 한계점
1 Introduction
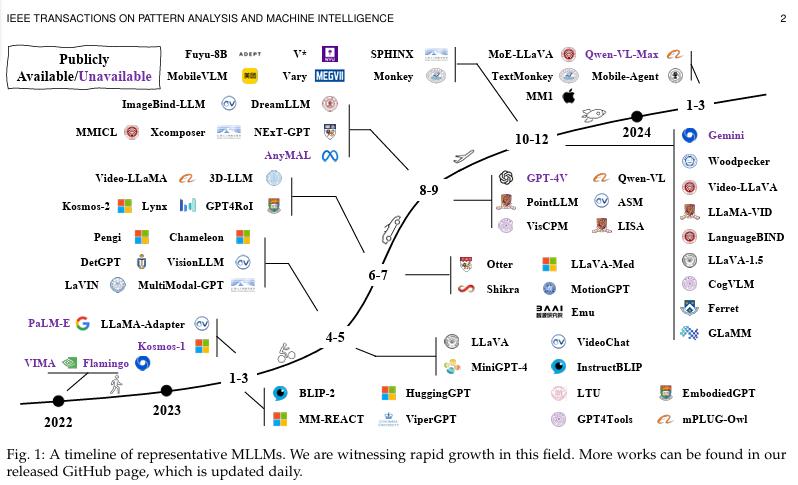
- 최근 몇년간 LLM 분야에서는 비약적인 발전을 이루어냈다. (Context-Learning, Chain of Thought)
- 자연어 처리 분야에서 zero/few shot 에 있어서는 놀라운 성능을 가지고 있지만, 아직 vision과 관련된 부분에 있어서는 ‘blind’하다. (이산적인 텍스트만을 이해하기 때문)
- 멀티모달 분야의 발전과정은 크게 2가지의 방향으로 구분된다.
- CLIP 과 같이 텍스트와 이미지 인코더를 활용하여 하나의 임베딩 벡터 공간에서 유사도를 측정하여 downstream multimodal tasks로 이어지는 방식
- OFA(One-for-All)와 같이 sequence-to-sequence 방식으로 멀티모달 tasks를 수행하는 방식
(OFA → 하나의 모델이 모든 종류의 task를 처리)
→ MLLM은 굳이 따지자면 2번 방식에 속한다고 볼 수 있다. (GPT, Gemini)
하지만, 이전의 전통적인 방식과는 2개의 명시적인 특성을 가지고 있다.
- MLLM은 LLM을 기반으로하며, 수십억개의 파라미터를 가지고 있으며, 이전 모델에서는 불가능
- MLLM은 모델이 가진 모든 잠재력을 해방하기 위해 새로운 학습 패러다임을 사용
→ 이렇게 2가지의 특성을 통해 MLLM은 새로운 능력을 가진다. (이미지를 통해 웹 코드 작성, 밈의 내재적인 의미 이해 등)
초기의 MLLM 관련 연구들은 이미지, 비디오, 오디오를 통해 텍스트를 생성하는 것에 집중했었다.
이후 후속 연구들
- Better Granualrity Support - 모델이 더 세분화된 부분에 집중할 수 있도록
- 더 정밀한 능력을 가지도록 하는 연구
- Input and Output Modalities
- 모델의 입력과 출력을 더 다양한 방식으로 발전시키기 위한 연구 (이미지, 비디오, 오디오, point cloud 등)
- point cloud? → 3차원 공간에 찍힌 점들의 집합 (3D 데이터)
- 모델의 입력과 출력을 더 다양한 방식으로 발전시키기 위한 연구 (이미지, 비디오, 오디오, point cloud 등)
- Improved Language Support
- English 뿐만 아니라 중국어 등 다른 언어들로의 확장
- Extension to more Realms and Usage Scenarios
- 더 다양한 tasks 로의 확장
따라서 해당 논문에서는 이렇게 빠르게 발전해나가는 MLLM 분야에 대한 basic ideas와 main method, 그리고 MLLMs의 현주소와 같은 정보들을 제공하는 것을 목표로함
- Mainstream Architectures
- Training Strategy and Data
- Performance Evaluation
- Important Topics about MLLMs
- 어떤 방향으로 어떻게 더 발전할 수 있을까?
- Multimodal의 hallucination을 어떻게 해결할 수 있을까?
- 3가지의 주요 방식에 대해 소개
- M-ICL (추론 단계에서 활용, few-shot 성능 향상을 위함)
- M-CoT (복잡한 문제들에 주로 활용)
- 혼합되고 복잡한 문제들을 사용자들의 요구에 알맞게 LLM-based system들이 해결할 수 있도록 develop
- 3가지의 주요 방식에 대해 소개
2 Architecture
전형적인 MLLM은 추상적으로 보면 3개의 모듈로 나누어볼 수 있다.
- Pre-trained Modality Encoder
- 주어진 데이터들을 전처리 (LLM이 다룰 수 있는 벡터 표현(feature)로 변환)
- Pre-trained LLM
- MLLM의 뇌에 해당되며, Encoder를 통해 전처리된 데이터를 이해하고 처리
- Modality Interface (2개를 연결)
- Encoder가 생성한 feature를 LLM의 토큰 임베딩 공간과 형식에 맞게 projection/align
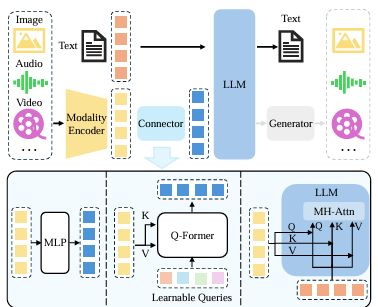
2.1 Modality Encoder
- raw information (images, audio .. )를 압축된 표현 (compact representation)으로 변환
- 처음부터(from scratch) 학습시키기 보단 pre-trained된 인코더를 활용
예시) CLIP
- 사전 학습된 엄청난 크기의 image-text 쌍을 학습한 visual/text 인코더를 활용
- 텍스트와 어느 정도 맞춰진 encoder를 활용하는 것이 LLM과 함께 정렬시키는 pre-training이 더 쉬움
가장 흔히 사용되는 image encoders
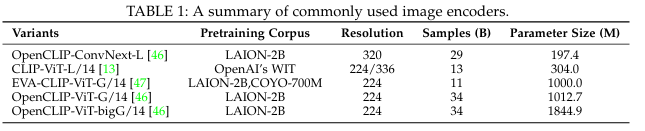
→ MiniGPT-4은 EVA-CLIP 인코더를 활용하고, Osprey는 cnn 기반의 인코더를 활용하는 등, LLM은 이미지 형태의 입력을 받는 것에 있어서 flexible함
이렇게 LLM이 입력으로 받는 형태에 대한 유연성을 가질 수 있는 이유? → Modality Interface
💡 어떤 Encoder를 선택해야할까?
- 더 높은 해상도에서 이미지를 처리하는 encoder를 선택하는 것이 경험적으로 놀랄만한 성능 향상을 가져옴
- 파라미터 크기와 학습 데이터의 구성은 입력 이미지의 해상도와 비교해 보았을 때 덜 중요하다
- 높은 해상도를 구현하는 방식
- direct scaling → 인코더에 더 높은 해상도의 이미지를 입력하거나, 인코더 자체를 사전학습된 더 높은 해상도의 인코더로 교체
- CogAgent 는 저해상도, 고해상도, 2개의 독립적인 인코더를 활용함
patch-division methods
→ 높은 해상도의 이미지를 patch 단위로 자르고, 저해상도 인코더를 재활용함
- 높은 해상도를 patch 단위로 쪼갠 sub-image와 기존의 이미지를 저해상도로 downsampling한 이미지를 모두 인코더에 부여하여 local feature들과, global feature 모두 얻고자함
또한, 각 모달리티에 대해 이미 잘 학습된 인코더를 MLLM의 Modality Encoder로 사용해도됨
2.2 Pre-trained LLM
- pre-trained된 LLM을 사용하는 것이 더 효율적이고, 실용적이다.
- 가장 많이 사용하는 pre-trained LLMs

( Qwen은 중국어, 영어 모두 지원하는 bilingual LLM)
- LLM의 파라미터 크기를 scaling up 하는 것은 이미지 인코더의 해상도를 높이는 것과 비슷하게 추가적인 이점을 가져온다.
- 그저 LLM 을 7B에서 13B로 scaling up하는 것 자체로 성능적인 부분에서의 개선을 이룰 수 있다.
- 34B LLM이 되면, 영어로만 학습을 했음에도, 중국어에 대한 zero-shot이 곧바로 가능했다.
💡 최근에는 Mixture of Experts (MoE) 아키텍처에 대한 연구가 많이 이루어지고 있다.
- 모든 파라미터들을 항상 다 쓰는 구조를 가진 dense 모델들과 달리, MoE는 일부 파라미터만 선택적으로 활성화하는 sparse 구조이기 때문에, 연산량은 비슷하게 유지하면서도 전체 파라미터의 수를 크게 증가시킬 수 있다.
- MM1, MoE-LLaVA는 기존의 dense 모델들보다 더 좋은 성능을 보임
2.3 Modality interface
💡 LLM은 오직 텍스트를 인지하기 때문에, 다른 modality(image, video, audio ..)와 자연어를 이어주는 작업이 필수적임
- Large Multimodal Model을 end-to-end (처음부터 끝까지 한 번에) 학습시키는 것은 비용이 너무 큼
가장 실용적인 방식 →
- 학습 가능한 connector 를 사전학습된 visual encoder와 LLM사이에 두는 것
- Expert Models를 활용하여 이미지를 language로 번역하여 LLM 에 전달
Learnable Connector
- LLM이 효율적으로 이해할 수 있는 공간에 다른 유형의 정보들을 투영해야함
- multimodal information이 어떻게 결합되는지에 따라 2가지의 방식으로 나뉜다.
- token - level fusion
- feature - level fusion
Token-level Fusion
- 인코더로부터 출력된 features들을 토큰으로 변환한 후에, LLMs에 보내기 전에 텍스트 토큰들과 이어준다.
- BLIP-2, Q-Former : 이미지 인코더를 통해 생성된 patch features를 attention의 key/value로 설정, learnable Query Tokens를 생성하여 patch features와의 attention을 통해 이미지 정보들을 가져옴 → 최종 Visual Tokens를 생성
- Learnable Query Tokens → tokens for LLM
- LLaVA : 이미지 인코더를 통해 생성된 Visual Tokens에 1,2개의 선형 레이어인 MLP를 적용하여 word embeddings로 이미지 특징들을 투영
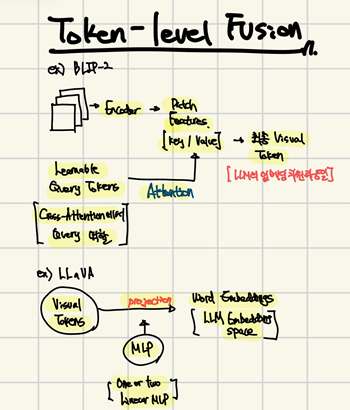
→ 이후의 ablation(제거) 연구에서 modality adapter의 type 보다는, visual tokens의 개수와 입력 해상도가 더 중요하다는 것을 보여줌.
💡 즉, Q-Former냐, 단순 MLP냐, 같은 타입보다, 얼마나 많은 시각 토큰을 LLM에 전달하는지, 인코더에 어떤 resolution을 주는지가 더 중요하다.
- VQA 기준으로는 token-level fusion이 더 성능이 좋았으며, BLIP-2와 같은 cross-attention/feature-level 구조는 제대로 성능을 내기 위해서는 hyper-parameter 서치를 더 복잡하게 해야함
Feature-level Fusion
- 텍스트 특징들과, visual 특징들의 더 깊은 상호작용을 가능하도록 하는 추가적인 module을 삽입
- Flamingo : LLM의 얼린 transformer layer 사이에 cross-attention layer를 추가하여서 언어적인 특징에 외부 시각 단서를 섞어 증강을 시킴
- CogVLM : 각각의 Transformer Layer에 visual expert 모듈을 삽입하여 언어 feature와 시각 feature가 서로 융합되도록 하는 구조
- Visual Expert : 시각 토큰 전용 서브-네트워크 + cross-attention 이미지 토큰 처리에 특화된 경로를 따로 둠, LLM의 원래 FFN, attention은 텍스트에 최적화되어 있지만, visual expert를 추가함으로써 이미지 경로도 추가해줌
→ visual feature와 language feature가 더 잘 fusion되도록 도움
| Token - level Fusion | Feature - level Fusion |
|---|---|
| 인코더로부터 출력된 feature들로 token을 생성하여 LLM에 전달 | 텍스트 특징 , visual 특징들이 더 깊이 상호작용하도록 추가적인 module 삽입 |
| Visual Tokens, Text Tokens 가 각각 서로 다른 토큰 시퀀스 (종류가 2개라고 생각) | Vision, Language feature를 LLM에 보내기 전에 별도의 추가적인 모듈을 통해 충분히 섞은 후, 결과를 LLM에 전달 |
Expert Model
Multimodal input 을 학습 없이 Language로 변환
→ LLM은 이 방식으로 다양한 형태(image, video, audio ..)의 input을 이해할 수 있음
Expert Model을 사용하는 것은 구조가 단순하지만, learnable interface를 사용하는 것보다 유연하지 않다.
- 다양한 multimodal input을 텍스트로 변환하는 것은 정보 손실을 일으킬 수 있다.
3 Training Strategy and Data
- MLLM은 3가지의 학습 과정을 거친다.
- pre-training, instruction-tuning, alignment tuning
3.1 Pre-training
3.1.1 Training Detail
- 서로 다른 형태의 데이터(modalities)를 align 하는 것을 목표로 함
- large-scale의 텍스트와 쌍을 이루는 데이터를 수반함 (image-text , audio-text, video-text)
아래의 사진처럼, 모델은 하나의 이미지가 주어지면, 이미지의 캡션을 예측하도록 학습된다.

- 자기회귀적 (Autoregressively)으로 이미지에 대한 캡션을 예측함 (Cross-Entropy Loss 활용)
- CLIP은 텍스트와 이미지 사이를 비교하여 대조 학습 방식으로 학습한다면, MLLM은 이미지를 보고 텍스트를 한글자씩 생성(Autoregressive)하는 방식
- 가장 흔한 접근은 사진학습된 모듈은 얼려주고, 학습가능한 인터페이스(Learnable Interface)를 학습하는 것이다. (학습가능한 인터페이스, 연결장치(Learnable Interface) → 2개의 서로 다른 분야의 모델을 연결해주는 장치)
→ 다양한 형태의 데이터(modalities)를 사전학습된 지식을 잃지 않고, 정렬시키는 것이다.
- 다양한 모듈들을 얼리지 않고, 정렬을 위해 더 많은 파라미터들을 학습 가능하도록 하는 방식도 있다.
- 학습시에 중요한 것은 결국 데이터의 품질이다.
- 짧고, 쓸데없는 정보가 섞여있는 (Noisy) 캡션 데이터는, 낮은 해상도를 활용하여 학습 속도를 높이는 전략을 선택하고, 더 길고 깨끗한 데이터를 활용할 경우엔, 해상도를 높여서(448 이상) 모델의 Hallucination을 줄이는 방식을 선택한다.
3.1.2 Data
- Pretraining Data는 2개의 역할을 수행함
- 다양한 모달리티를 정렬 (align different modalities)
- 언어적인 지식을 제공
- Pre-training 시 가장 흔히 활용하는 데이터셋
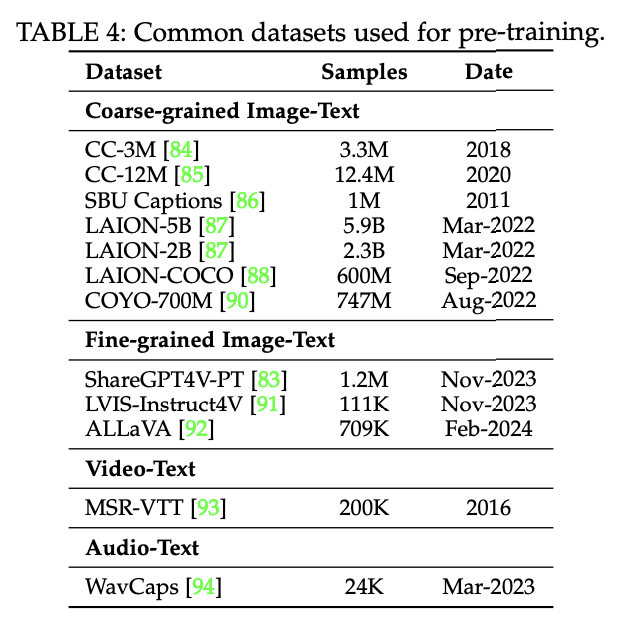
- Coarse-grained caption data는 공통적으로 가지고 있는 전형적인 특징들이 몇 가지 있음
- 인터넷에서 추출해온 데이터이기 때문에 데이터의 양이 방대하다.
web-scrawled 데이터이기 굉장히 짧고, 다른 불필요한 요소들이 많이 포함되어 있다.
→ 또한, 웹사이트에 있는 이미지의 대체 텍스트(alt-text)에서 추출되었기 때문!
따라서, 자동화 툴을 사용하여 이 데이터들을 깨끗하게 정제하는 과정을 거친다.
ex) CLIP을 사용하여 이미지와 텍스트 쌍의 유사도가 특정 임계값보다 낮은 경우를 찾아냄
What is alt-text?
→ HTML 소스 코드에서 alt=”” 부분에 해당하며, 일반적인 웹 서핑 중에는 보이지 않지만, 네트워크 문제로 이미지가 로드되지 않을때, 글자로 대신 나옴
- CC
- CC-3M 데이터셋은 웹-스케일의 캡션 데이터셋이고, 웹사이트에서 이미지를 대체하기 위해 작성한 텍스트를 활용했다.
- 다음과 같은 복잡한 파이프라인을 통해 데이터를 정제하고자함
- 이미지 데이터에 관해서는 부적절한 내용과 종횡비(aspect ratio)를 가진 이미지를 필터링
- 텍스트 데이터에 관해서는 NLP tools를 활용하여 annotations를 생성하고자 하였고, 사전에 정의된 heuristics를 기준으로 샘플링했음
- NLP tools를 활용한 annotations → 단지 텍스트 데이터를 더 작게 나누는 것을 넘어, 텍스트를 분석하여 꼬리표를 단다고 생각 (품사 확인, 개념 추출 등)
- heuristics? → 사전에 사람이 정의해둔 규칙 (길이 규칙, 형식 규칙, 반복 규칙 등)
- image-text pairs → 이미지는 분류기를 통해 label을 달고, 생성한 text annoations는 labeling된 이미지와 겹치지 않는다면 제거
- CC-12M : CC-3M의 연장선으로, 데이터를 정제하는 과정을 약간 완화하여 더 많은 양의 데이터를 구축하는데 집중
- SBU Captions
- Flickr 사이트에서 가져온 1M 개의 이미지-텍스트 쌍으로 이루어진 이미지-캡션 데이터셋
- 이미지 데이터셋 → Flickr 웹사이트에서 많은 검색어를 부여하여 얻음
- 이미지에 대한 descriptions가 이미지와 맞도록 하기 위해 이미지들은 다음과 같은 요구사항들을 충족해야함
- 이미지의 설명 (description)은 충분한 길이를 가져야함
- 이미지에 대한 설명이 너무 짧은 것을 방지하기 위함
- 이미지에 대한 설명은 on, under와 같이 공간적인 의미를 가진 단어를 최소 2개 포함하고 있어야함
- 이미지의 설명 (description)은 충분한 길이를 가져야함
- LAION
- 웹 스케일의 데이터셋으로, 인터넷에서 수집한 이미지 데이터들과 그 이미지를 대체하는 텍스트 (alt-text)로 이루어진 데이터셋
- 이미지-텍스트 쌍을 필터링 하기 위해서, 다음과 같은 과정을 수행
- 이미지에 대한 설명이 너무 짧거나, 이미지의 크기가 너무 작거나 큰 경우에는 필터링됨
- 데이터 중복 제거 (Image deduplication)
- CLIP을 통해 이미지와 텍스트에 대한 임베딩을 추출하고, 부적절한 내용을 담거나, 이미지와 텍스트 임베딩 사이에 낮은 코사인 유사도를 가진다면 drop
- COYO-700M
- 747M의 이미지-텍스트 쌍으로 이루어졌으며, CommonCrawl에서 추출
- Data Filtering
- 부적절한 크기, 내용, 형식이나 종횡비를 가진 이미지 데이터셋은 필터링됨. 또한, pHash를 통해 대규모 공용 데이터셋인 ImageNet이나 MS-COCO와 겹치는 이미지는 필터링됨
- 텍스트에 관해서는, 영어로된 텍스트, 충분한 길이, 명사, 그리고 적절한 문장들만 남김
- 문장의 시작과 끝의 공백 제거, 10번 이상 등장하는 텍스트 제거
- image-text pair에 관해서는, 중복되는 샘플들은 제거됨
→ 여기까지의 데이터셋들은 모두 coarse-grained Data (거친 입자 데이터셋)
이 데이터셋들 뿐만 아니라, 최근에는 MLLM들을 prompting을 통해 high-quality fine-grained data를 생성하려는 시도가 많음
→ 이러한 방식으로 생성된 데이터셋은 fine-grained data
하지만 이 방식은 비용이 높음 → 처음으로 이 한계를 극복한 것이 ShareGPT4V 연구
- 소량의 데이터를 먼저 생성하고, 그 데이터를 학습한 모델로 대량의 데이터를 생산
3.2 Instruction-tuning
3.2.1 Introduction
Instruction → 모델이 사용자가 의도한 바를 더 잘 이해하도록 하기 위함
- Instruction을 통해 튜닝된 모델은 일반화 능력이 상승하고, 제로샷 성능도 좋아짐
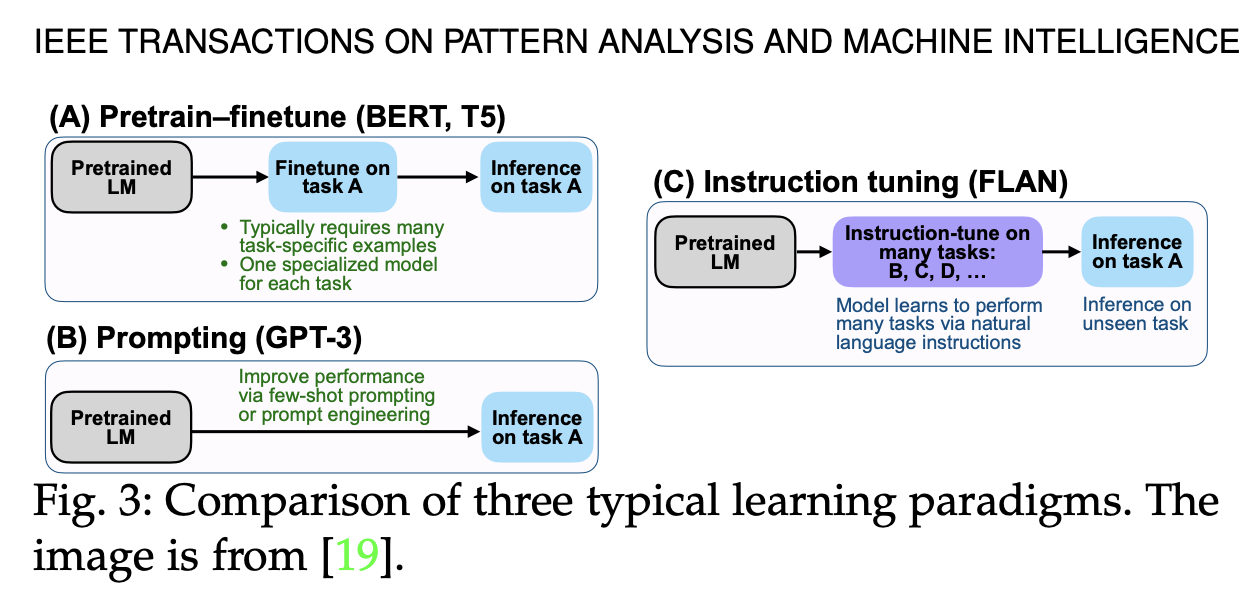
- Fine-Tuning 방식은 많은 양의 task-specific 데이터가 필요함 → fine-tuning하기 위한 데이터셋이 필요함
Prompting 방식
→ 대용량의 데이터의 의존성을 줄이고, prompt-engineering을 통해 구체적인 task를 수행할 수 있음
하지만, few-shot 성능은 발전이 되지만, zero-shot 성능은 아직 평균 수준에 머무름
Instruction-Tuning 방식
→ 앞의 2개의 방식(특정 task를 해결하는 능력을 배우는)과 다르게, Unseen Task 에 일반화하는 방식을 배움
→ Multi-task prompting과 성격이 비슷함 (여러가지 task를 수행할 수 있음)
Unseen Task와 Zero-shot
- Unseen Task(문제의 성격) → 한번도 학습하지 않은 종류의 작업
- Zero-shot(문제를 푸는 방식) → 어떤 문제를 풀 때, 그 문제에 대한 예시를 하나도 받지 않고 task 수행
즉, 모델의 성능이 좋다는 것은 Unseen Task에 대한 Zero-shot 성능이 좋다는 것이다!
3.2.2 Training Detail
- Multimodal Instruction sample은 최적의 instruction 과 input-output 쌍을 포함
- Instruction → 전형적으로 자연어 문장이며, task를 설명하는 문장이다. ex) “Describe the image in detail”
- Input → 이미지-텍스트 쌍 , image 둘 다 가능

- 위의 사진은 instruction template이며, instruction은 기본적으로 유연성을 가짐
- 또한, Instruction Template은 일회성 문답 뿐만 아니라, 여러 번 주고받는 연속 대화 형식으로도 확장해서 사용 가능 (multi-round conversations)
- output → instruction을 따른 input에 맞는 정답
Multimodal Instruction
- 💡 triplet form (I,M, R)
- I → instruction (자연어 텍스트 그 자체)
- M → Multimodal Input (이미지 혹은 다른 형태의 데이터, 그냥 그 데이터 그 자체. 이미지면 .jpg, .png 인 상태이고 앞으로 임베딩화 될 대상임)
- R → 주어진 instruction(I)를 따르며, 입력으로 받은 멀티모달 데이터에 맞는 이상적인 정답 답변 (자연어 상태)
- 아래와 같이 MLLM은 주어진 instruction과 입력값을 통해 정답을 예측함

- A → 모델이 예측한 정답
- θ → 모델의 파라미터
기본적으로 모델이 학습하고자 하는 대상 (training objective)는 LLM이 학습하는 방식인 auto-regressive objective 이며, MLLM은 정답을 구겅하는 다음 토큰을 예측함
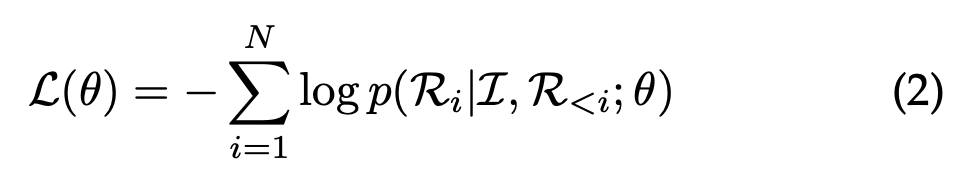
- 손실 함수 → 앞의 정보들이 주어졌을 때, i번째 정답 토큰이 나올 확률을 의미
- I (멀티모달 지시어) → instruction과 멀티모달(Input)을 합친 입력 정보
- R<i (과거의 정보) → i 번째 토큰이 나오기 전까지 이미 생성된 앞부분의 정답 토큰
- 위의 식을 보면, N은 ground-truth response (예측의 정답)
- 즉, 1번째 단어부터 N 번째 단어까지 순서대로 훑어가면서, i 번째 단어를 맞힐 때는 항상 지시어(I)와 앞서 나온 단어들을 통해 맥락을 모두 고려함
- 모델의 예측 능력 : θ
- 마지막에 시그마를 통해 최종 손실을 구함
정리하자면 → 실제 정답인 R_i를 타겟으로 삼고, 모델의 가중치 (θ)가 정답을 맞힐 확률을 높이는 방향으로 학습
3.2.3 Data Collection
- instruction data는 더 까다롭고, 비용이 많이 들기 때문에 수집하는데 어려움이 있다.
- 따라서 논문에서는 이러한 특성을 가진 instruction data를 수집할 수 있는 방식 3가지를 제안한다.
- data adaptation, self-instruction, data mixture
Data Adpatation
- 사전에 생성된 고품질의 데이터셋을 instruction-formatted 데이터셋으로 변형시키는 방식
- ex) VQA data
- input : Image, natural language question
- output : textual answer
→ 자연스레 input은 multimodal형식이고, 출력은 텍스트이기 때문에 이를 instruction 데이터로 활용 가능
- 왜 VQA 데이터를 활용할 수 있는가? input이 이미지와 텍스트, 멀티모달 형식이며, 출력에 대한 정답 또한 사람이 직접 검수한 정답(텍스트 형식)이기 때문
- ex) VQA data
VQA 데이터셋을 활용하되, input으로 주어지는 텍스트는 instruction으로 대체됨!

- 그렇다면 어떻게 instruction을 만드는가?
- 수동 설계 (Hand-crafted/Manual Design)
- GPT를 활용한 반자동 생성 (Semi-automatic Generation)
그럼에도 VQA 데이터셋에 있는 caption 데이터는 간결하기 때문에, MLLM의 출력 길이에 미치지 못할 수 있다는 한계가 존재 (단답형의 저주)
- 어떻게 한계를 극복할 것인가?
- instruction 내에 명시적으로 구체화하는 것
- 기존의 존재하는 정답의 길이를 확장하는 것
Self-Instruction
- 현존하는 multi-task dataset들은 스케일이 크지만, 실질적으로 multiple rounds of conversation 같은 실질적인 문제에 대해서는 부족하다.
- 한계를 극복하기 위한 시도
→ Self-Instruction
- 몇개의 샘플들을 활용하여 LLM로 하여금 instruction 데이터를 생성하도록 하는 방식
- 수동으로 설계된 몇개의 instruction을 LLM에게 description으로 부여하여 비슷한 instruction sample을 만들도록 prompting하는 방식
- LLaVA → 이미지를 텍스트 형식의 캡션과 그에 맞는 바운딩 박스로 번역하고, GPT-4를 텍스트만을 사용하여 prompting하여 새로운 데이터(instruction)을 만들도록 한다.
즉, LLaVA가 생성한 이미지에 대한 캡션과, GPT를 통해 생성한 instruction, 그리고 정답 (LLaVA or GPT) 이렇게 Triplet 데이터셋을 구성함

Data Mixture
- Multimodal instruction 뿐만 아니라, language-only 형식의 모델과의 질의응답 과정은 모델이 instruction을 따르는 능력과 대화 능력을 증진시킬 수 있음
- LaVIN → 매 학습 단위(minibatch)마다 텍스트 전용 대화 데이터와 이미지-텍스트가 섞인 데이터를 랜덤하게 섞어서 학습에 사용
- MultiInstruct → 단일 모달과 멀티모달 데이터를 융합
3.2.4 Data Quality
“instruction-tuning 데이터는 데이터의 질이 데이터의 양만큼이나 중요하다”
- 노이즈가 섞인 데이터셋으로 사전학습한 모델의 성능은 데이터의 규모가 작지만, 깨끗한 데이터로 학습했을때보다 더 낮았다.
- 데이터의 품질을 평가하는 방식
- Prompt Diversity
- instruction의 다양성이 모델의 성능을 높이는데에 있어서 가장 중요했다.
- instruction의 다양성은 모델의 성능뿐만 아니라, 일반화 능력까지 향상시켰음
- Task Coverage
- Visual Resoning (시각 정보를 바탕으로 논리적 추론을 수행)이 VQA나 Image Captioning 보다 더 고차원적이고 복잡한 지능을 요구함
- 따라서, instruction의 다양성만큼이나 instruction의 복잡성은 모델이 유연하고, 더 정교하게 물체를 찾아낼 수 있는지에 대한 핵심 전략임
- Prompt Diversity
3.3 Alignment Tuning
3.3.1 Introduction
- Alignment Tuning은 주로 모델을 사용자 선호도 (말투, 대화의 맥락 등)를 맞추기 위해 사용됨
- 가장 대표적인 방법은 Reinforcement Learning with Human Feedback(RLHF), Direct Preference Optimization(DPO)이 있다.
3.3.2 Training Detail
Reinforcement Learning with Human Feedback(RLHF)
- 학습 과정에서 Human Annotation (사람(연구자)이 직접 선택)을 학습의 가이드라인 (Supervision)으로 활용하여 강화학습 알고리즘을 사용자의 선호도에 맞춘다.
- What kind of preference?
- 전문가의 선호
- 일반 사용자의 선호
- 사회적 윤리 및 안전성 선호
- Policy Model (최종적으로 학습할 Main MLLM), Reward Model (Policy Model을 보조하는 역할)
아래의 3가지 단계를 거친다.
- Supervised fine-tuning (기초 모델 설정)
- 사전학습된 모델을 원하는 출력값을 가지도록 fine-tuning → Policy Model
- instrucion-tuned model로부터 policy model 이 정의된다면 이 과정을 생략될 수 있음
→ instruction-tuning 된 모델이 사전에 준비되었다면 이 단계는 생략될 수 있음.
- Reward Modeling (독립적으로 학습시킴)
- 모델에게 Multimodal prompt (image & text)를 부여하고, 그것에 대한 response 중, 사용자의 선호 (preferences)에 맞는 response에 더 높은 보상을 주도록 학습, 선호되지 않는 답변에는 낮은 보상을 부여. (아래의 식을 통해 이를 수행함)
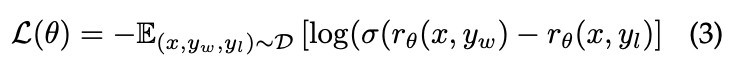
- 이 식에서 D는 사람의 annotations를 통해 라벨링이된 데이터셋임
- Reinforcement Learning
- PPO (Proximal Policy Optimization)을 활용하여 policy 모델을 학습
모델의 학습 안정성을 위해 KL Penalty (KL Divergence)를 사용
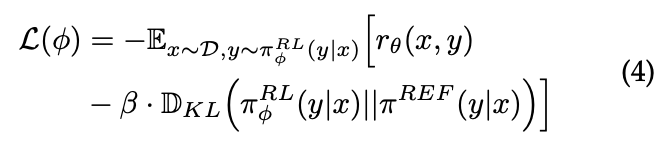
- (4)식은 강화학습 단계에서 모델이 최종적으로 최소화해야할 손실함수 (Loss Function)
- 중간의 -를 기준으로 앞쪽의 식은 reward model이 주는 점수를 의미
- -를 기준으로 뒷부분은 KL 페널티 항
- β : 얼마나 penalty를 줄지를 결정하는 계수
→ 즉, 모델은 사용자의 preference에 맞는 response에는 높은 보상을 주며 학습을 하지만, 모델의 학습 안정성을 위해 KL penalty를 사용함
💡 이 방식으로 학습한 강화학습 모델이 생성하는 답변의 확률분포가 인간이 선호하는 답변 영역으로 이동하게됨 → 즉, human preference에 맞는 response를 생성할 수 있게 학습함
Direct Preference Optimization (DPO)
- 이중분류 손실을 통해 human preference labels로부터 배움
- PPO-RLHF 알고리즘은 따로 reward model을 학습시켰다면, DPO 알고리즘은 전체 파이프라인을 2개의 단계로 나누어서 학습한다.
- human preference data collection (인간 선호 데이터 수집)
- Preference Learning
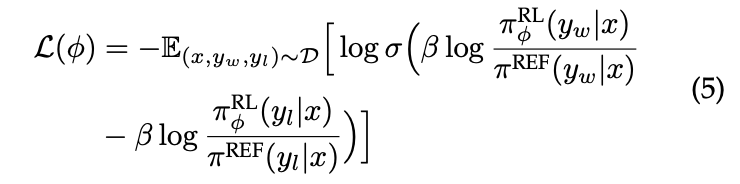
- 최종적으로 학습할 식
- 원래 모델 (REF) 대비 현재 모델 (RL)이 y_w (좋은 답변)을 선택할 확률을 human preference를 따르지 않는 답변을 선택할 확률보다 커지도록 최적화
RLHF-V(data collection, 1st step)는 fine-grained (segment-level) preference data pairs를 모델의 답변에서 hallucination을 고쳐가며 수집하여 dense한 DPO(Preference Learning 2nd step)에 사용할 수 있게 함
Silkie → GPT-4V를 prompting하여 preference data를 수집, DPO를 통해 instruction-tuned 모델에 증류(distill)시킴
3.3.3 Data
- 여기서 계속 말하는 Data Collection은 모델이 생성한 답변에 대한 feedback이라고 생각하면 됨.
→ feedback을 통해 어떤 답변이 더 나은가?를 판단할 수 있음
- 이러한 데이터(alignment-tuning을 위한)는 수집하기 어렵고, 그 양도 적음
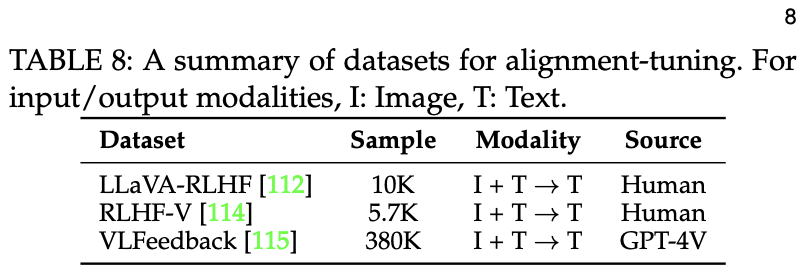
가장 대표적인 데이터셋 (Preference Data)
4 Evaluation
- 기존의 다른 multimodal model의 evaluation(평가) 방식과 MLLM의 평가방식은 몇가지 차별점이 있다.
- MLLM은 많은 능력을 가지고 있기 때문에, 종합적으로 평가하는 것이 중요
MLLM의 평가는 크게 질문 장르를 다양화하여 평가하고, closed-set과 open-set 평가로 나눌 수 있다.
Closed-set Evaluation 폐쇄형 평가 답변의 후보가 정해져 있는 상태에서 정답을 고르도록 하는 평가 방식 Open-set Evaluation 개방형 평가 답변의 형식을 제한하지 않고 모델이 자유롭게 문장을 생성하도록 하는 방식
4.1 Closed-set
- 답변의 후보가 사전에 정의되어 있는 상태에서 모델을 평가하는 방식
- task-specific dataset에 대해 주로 수행
- Evaluation Setting (1)
- Fine-Tuning 후 모델이 한번도 보지 못한 데이터셋에 대한 zero-shot 성능 확인
- Evaluation Setting (2)
- 특정 분야 (domain-specific tasks)에 대한 데이터셋으로 평가를 진행
→ 하지만 이 평가 방식들은 선택된 task에 따라 데이터셋의 크기와 같은 한계에 부딪혔고, 결과적으로 MLLM을 포괄적으로 평가하기 힘듦
따라서, MLLM만을 위한 새로운 benchmarks(기준)을 개발하기 위한 노력들이 있었음 (MLLM을 위한 종합 평가 데이터셋)
- MME → 14개의 지각 및 인지 문제를 포함하여 사람이 직접 수동으로 생성한 instruction-answer pair 데이터셋
- MMBench → 모델의 지능을 고차원적으로 평가
- Video-ChatGPT & Video-Bench → 비디오 분야의 차별화된 benchmarks
4.2 Open-set
- closed-set과 비교해보았을때, MLLM이 챗봇과 같은 역할을 하기 때문에 open-set questions는 더 유연하다.
- 따라서, closed-ended output보다 더 판단하기 애매할 가능성이 존재한다.
- 평가 표준은 manual scoring, GPT scoring, case study
- manual scoring → 사람이 직접 모델이 생성한 답변을 평가
- 주로 특정한 차원에 대한 평가를 하기 위해 사람이 직접 설계한 질문들이 포함됨
- GPT scoring → manual scoring 방식이 굉장히 Labor-intensive 하기 때문에 제안됨
- 멀티모달 대화에 대한 성능을 평가하기 위해 주로 사용됨
- 모델이 생성한 답변과, GPT-4가 생성한 답변 모두 비교를 위해 GPT-4로 보내진다.
→ 이후 GPT 계열의 모델들을 prompt하여 평가에 사용함
- Case Study → 다양한 분야의 데이터를 통해 평가
- ex) GPT-4V 모델에 대한 평가를 진행하기 위해 다양한 분야에 걸친 문제들과, 복잡한 문제들, 농담과 실내 네비게이션 등을 포괄하는 샘플을 활용하여 평가
- manual scoring → 사람이 직접 모델이 생성한 답변을 평가
5 Extensions
MLLM이 어떤 방향으로 확장되고 있는지?
Granularity Support (모델의 세밀함)
- 모델의 input & output 각각에 대해 모델이 더 세밀해질 수 있도록 연구
- input
- 사용자의 프롬프트 (시각적 지시)를 영역이나 픽센단위로 더 자세하게 지정하여 모델에게 부여할 수 있다. (Finer Control이 가능하다)
- output
- Input의 세밀함의 발전과 함께 output 또한 grounding capabilities가 발전
- Grounding Capabilities? → 텍스트와 시각 정보를 결합할때, 단순히 단어로만 표현하는 것이 아니라, 실제로 이미지 안에서의 좌표까지 출력하는 것
- input
Modality Support
- Modality Support는 MLLM이 얼마나 다양한 형태의 데이터를 동시에 이해하고 처리할 수 있는 능력을 의미
- 이미지, 오디오, 비디오 등 다양한 형태의 데이터를 이해하고 처리할 수 있음
- 2D 뿐만 아니라 3D point cloud (3차원 공간상에 흩어져 있는 수많은 점)와 같은 입체적인 구조 또한 이해
Language Support
- 현재까지의 모델들은 대부분 영어 (English)만을 지원함
- 하지만, 다른 언어까지 학습시킬때는 학습단계를 여러 단계로 나누어 진행하는 방식을 선택
- Qwen-VL 은 중국어로 번역된 학습 데이터를 학습시에 포함시켰으며, 전체 데이터의 약 22.7%가 중국어 데이터였음
Scenario/Task Extension
- common tasks (사람처럼 다양한 일상적인 요청을 알아듣고 수행) 을 수행하도록 학습하는 것을 넘어서, 특정 세분화된 작업에 적용하기 위한 연구들이 진행됨
- MobileVLM → 모델을 경량화하여 연산속도를 가속
- Mobile-Agent, CogAgent → real-world에서 사용자와 상호작용하며 도움
- augment MLLM → 다양한 domain의 작업을 수행하기 위해 MLLM을 증강시킴
- LLaVA-Med → MLLM에 의학적인 지식을 불어넣어서 의료 이미지 인식, 질의응답 등과 같은 역할을 수행
6 Multimodal Hallucination
Multimodal Hallucination?
→ 어떠한 이미지에 대한 MLLM의 response가 일관되지 않는 현상
6.1 Preliminaries
- 현재로써 Multimodal Hallucination 현상은 3가지의 유형으로 나눌 수 있음
- Existence Hallucination
- 이미지 속에 어떠한 객체의 존재의 여부를 맞추지 못하는 현상
- Attribute Hallucination
- 이미지 속의 특정 객체에 대한 특성을 다르게 묘사하는 현상
- ex) 이미지 속 강아지의 색을 인식 X
→ 주로 Existence Hallucination과 같이 발생
- 이미지 속의 특정 객체에 대한 특성을 다르게 묘사하는 현상
- Relationship Hallucination
- 기본적으로 Existence Hallucination에 기반함
- 이미지 속 객체들의 관계를 틀리는 현상 → 상대적인 위치 or 상호작용 등
- Existence Hallucination
6.2 Evaluation Methods
- CHAIR (Caption Hallucination Assessment with Image Relevance) (주관식 평가)
→ 모델의 Hallucination 정도를 평가하는 측정 지표 → 모델이 생성한 open-ended captions (자유 형식의 캡션)에 대해 평가
- 전체 문장 중에서, 환각(이미지에 없는 물체 언급)이 포함된 문장의 비율을 계산
- POPE (Polling-based Object Probing Evaluation)
→ 모델이 주어진 선택지 중 어떤 선택을 하는지를 기반으로 Hallucination을 평가 (객관식 평가)
- 구체적으로, 특정 객체가 이미지에 존재하는 지에 대한 이진 선택을 포함한 다수의 프롬프트를 구성하여 모델이 어떤 답을 선택하는지에 대해 평가
🌟 이 방식은 모델이 각각의 주어진 객관식 choice에 대해 어떻게 생각하고 답을 도출했는지를 데이터의 통계를 통해 역추적하여 모델의 강건성 (Robustness)까지 평가할 수 있음
- 최종 평가 방식 (Final Evaluation) → 모델의 Open-ended response를 Closed-set(객관식 점수)로 바꾸어 평가
- MME
- POPE와 유사한 방식으로 평가하며, 모델이 이미지에 대한 존재 확인 여부(Existence), count, position, color 등 모델에 대한 포괄적인 평가를 제공
- HaELM
- LLM을 활용하여 MLLM이 생성한 이미지에 대한 캡션과 reference captions (정답 캡션)를 비교하여 평가
- FaithScore
- 모델이 내놓은 캡션을 통째로 보지 않고, 아주 작은 단위의 하위 문장으로 잘게 쪼개어 평가
- AMBER
- 모델의 판별 능력과, 생성 능력을 동시에 평가 (LLM-free)
6.3 Mitigation Methods (Methods for reducing hallucinations)
- 모델의 환각 (Hallucination)을 줄이기 위한 방법은 크게 3가지로 분류됨
- Pre-correction (사전 교정)
- 특수 데이터를 통한 미세 조정 (Fine-tuning)
- 모델이 Hallucination에 빠지지 않도록 하는 specialized 데이터를 학습시에 사용하여 hallucination response를 줄이는 방법
- Specialized Data
- LRV-Instruction
- visual instruction tuning dataset (이미지에 대한 틀린 instruction data)
- LLaVA-RLHF
- human-preference pairs 데이터를 수집하고, 강화학습을 통해 모델을 미세 조정하여 hallucination을 줄임 2. In-process-correction
- LRV-Instruction
- 모델의 아키텍처 or 데이터를 받아들이는 방식 (Representation)을 개선
- feature representation → 데이터를 보고 얼마나 정확하고 풍부하게 특징들을 표현하는지
→ 환각에 대한 이유를 찾아 생성 과정에서 hallucination이 발생하지 않도록 억제하는 방법을 설계
- HallE-Switch
- Existence Hallucination의 근본적인 이유 → 이미지 인코더에서는 물체를 인식하지 못했지만, LLM의 embedded knowledge를 바탕으로 멋대로 추측
- 시각 정보와 언어적 지식 사이의 불균형에서 발생
- 해결책
- Continuous Controlling Factor & Training Scheme
- 모델이 이미지에 있는 것만 말할지 or 자유롭게 추론할지를 조절한 연속적인 변수 도입
- Continuous Controlling Factor & Training Scheme
- Existence Hallucination의 근본적인 이유 → 이미지 인코더에서는 물체를 인식하지 못했지만, LLM의 embedded knowledge를 바탕으로 멋대로 추측
- VCD
- Object Hallucination의 이유
- 학습 말뭉치 (Corpus)의 통계적 편향
- LLM에 내재된 강력한 언어적 사전 지식
→ 이미지에 노이즈가 포함되면, MLLM은 이미지 대신 LLM의 언어적 고정관념에 의존하며 결국 Hallucination으로 이어짐
- 모델의 가중치를 fix하기 보다는, false bias 답변의 확률을 원래 답변 확률에서 차감하여 hallucination 확률 차단
- Object Hallucination의 이유
- HACL (CLIP과 유사한 Contrastive Learning 기반)
- 같은 임베딩 공간에서, 이미지 특징 벡터와 텍스트 특징 벡터 사이의 대조 학습
- 사전에 정의된 hallucinated sample과는 멀리, 그리고 서로 맞는 이미지-텍스트 쌍은 가까이하여 환각을 줄임
- Post-correction (사후 교정)
- 모델이 생성한 출력에 대해 수정하는 방식
- Woodpecker
- Expert Models 활용
- Object Detector 모델을 활용 → 이미지에 진짜 무엇이 있는지? (좌표 + 이름)
- VQA Model (시각 질의응답 모델) → 이미지에 대한 질문을 통해 재확인
- Expert Models의 피드백을 텍스트 정보로 보충하여 최종 답변 수정
- Expert Models 활용
→ 이미지 속 객체의 실제 위치와 연결 가능 & 어떤 근거로 수정했는지 확인 가능
- LURE
- Uncertainty가 높은 단어들을 찾는 Revisor 모델을 학습하여 Hallucination이 의심되는 단어를 Mask
7 Extended Techniques
7.1 Multimodal In-Context Learning
In-Context? → 모델로 하여금 어떤 식으로 출력을 생성할지에 대한 규칙이나 예시
- ICL은 LLM의 능력 중 하나임
- ICL의 장점 2가지
- 유추를 통한 학습
- 몇가지의 예시를 optional instruction과 함께 학습하고, 이를 새로운 질문들에 확장시켜서 더 복잡하고 낯선 문제들을 few-shot 방식으로 해결
- 학습을 하지 않는 training-free 방식으로 구현되며, 추론 단계에서 다양한 프레임워크와 유연하게 결합이 가능함
- 유추를 통한 학습
- MLLM의 관점으로 보았을 때, ICL은 MLLM를 더 다양한 Modalities로 확장시켰다. → M-ICL
M-ICL → 추론 단계에서, 가중치는 건드리지 않고, original sample에 demonstration set을 추가하여 어떤식으로 대답을 생성해야할지에 대한 규칙을 출력에 반영

사진 속 대시라인(—-)을 기준으로 위는 in-context samples (모델이 대답을 최종적으로 추론할때 고려해야할 문맥), 아래는 original sample (모델이 풀어야할 문제)
→ 모델은 demonstrations의 순서에 대체적으로 예민하다
7.1.1 Improvement on ICL capabilities
- 어떻게 더 다양한 문제들을 해결할 수 있고, 더 다양한 상황들에 적응할 수 있는지에 대한 발전과 relevant works를 소개
- MIMIC-IT
- 멀티모달 데이터들을 instrction dataset으로 형성하여 in-context learning과 instruction tuning을 결합
- Emu (Flamingo의 확장편, Flamingo → 그림을 보고 설명글을 작성)
- Emu → 설명글을 작성하는 것 뿐만 아니라 이미지 생성 가능
- extra modalities를 학습 말뭉치에 포함시켰음
- Emu → 설명글을 작성하는 것 뿐만 아니라 이미지 생성 가능
- Stable Diffusion
- 추가적인 시각적 supervision(학습 가이드라인)을 통해 출력 형식에 대한 유연성과 문맥 속 추론이 가능
→ 텍스트로 응답하는 것뿐만 아니라, 이미지 형태로도 응답을 생성
- Link-context learning
- 서로 맞는 이미지-텍스트 쌍과 맞지 않는 image-description 쌍을 형성하여 대조학습방식을 통해 이미지-라벨 사이의 연결을 강화
7.1.2 Applications
- 다양한 출력 형태에 적용하기 위해서, M-ICL은 2가지의 방식으로 사용됨
- solving various visual reasoning tasks
- few task-specific examples를 통해 현재 문제에 대한 파악과 어떠한 방식으로 답을 생성해야하는지에 대한 정보를 얻음
- teaching LLMs to use external tools
- more fine-grained
- 체계적인 단계를 형성하여 fulfill the task
- solving various visual reasoning tasks
7.2 Multimodal Chain of Thought
CoT (Chain of Thought)
- LLM을 prompt하여 최종 답변을 생성하는 것뿐만 아니라, 어떻게 정답을 추론했는지에 대한 추론 과정을 출력하도록함
- LLM의 발전으로 uni-modal CoT에서 Multimodal-CoT로 확장되었음
7.2.1 Learning Paradigms
- Multimodal-CoT (M-CoT)를 위해서는 크게 3가지 방식이 존재
- fine-tuning
- 주로 fine-tuning을 위한 구체화된 데이터셋을 M-CoT learning에 활용
- ScienceQA benchmark → 데이터셋에 답에 대한 설명 데이터(Rationale)가 포함되어 있기 때문에, CoT (Reasoning)을 평가할 수 있음
- training-free few-shot learning
- 사람이 직접 생성한 in-context examples를 활용하여 모델이 단계적으로 더 잘 논리적으로 추론할 수 있도록 도움
- training-free zero-shot learning
- 특별한 외부적인 guidance 없이, embedded 지식과 추론 능력을 사용하도록 모델이 학습
- fine-tuning
| Learning Paradigms for Multimodal-CoT (Chain of Thoughts) | 학습 방식 |
|---|---|
| fine-tuning | fine-tuning을 위한 specific datasets을 활용 |
| training-free few-shot learning | hand-crafted in-context examples를 활용 |
| training-free zero-shot learning | 외부적인 guidance 없이, 내재된 지식과 추론 능력을 활용하도록 모델 학습 |
7.2.2 Chain Configuration
- 어떻게 단계적으로 모델이 생각할 것인가? 그 chain의 형태는 크게 chain의 structure와 length로 나눌 수 있다.
- Structure
- 가장 많이 활용하는 chain의 구조는 단일 chain
→ 하나의 question-rationale chain을 활용하여 단계적으로 생각하여 답을 생성
하지만, 최근에는 tree 모양의 chain을 활용하는 연구도 진행되고 있다.
- Tree-shape chain
- DDCoT → 질문을 여러 개의 꼬마질문(sub-question)으로 세분화하고, 각각의 sub-questions는 LLM이나 vision expert models를 통해 추론 과정(Rationale)을 생성
- 이후 최종 답변을 생성하기 위해 LLM이 각각의 추론과정을 결합한다.
- Length
- adaptive , pre-defined formations로 나뉨.
- adaptive formations의 경우엔, LLM이 chain의 길이를 결정
- pre-defined formations의 경우, 사전에 정의된 길이로 고정
- adaptive , pre-defined formations로 나뉨.
7.2.3 Generation Patterns
- 어떻게 chain이 형성되었는지?
→ infilling-based pattern, predicting-based pattern
| How the chain is constructed? | |
|---|---|
| infilling-based pattern | reasoning step 사이의 logical gaps를 채우는 방식 (reasoning steps 사이를 이어주는 논리적 단계를 생성하도록) |
| predicting-based pattern | 주어진 instruction과 현재까지의 reasoning을 통해 다음 단계를 예측하여 확장해나가는 방식 |
7.3 LLM-Aided Visual Reasoning
7.3.1 Introduction
- tool-augmented LLM에 이어 하나의 거대 모델에 그치지 않고 visual reasoning task를 위해 다른 external tools와 연결하는 것에 대한 연구가 이루어짐
- 전통적인 visual reasoning task와 비교해보았을때, 이 방식은 3가지 장점을 가진다.
- String generalization abilities
- 방대한 데이터를 통해 사전학습된 모델들을 같이 활용하게되면, zero/few shot 성능과 높은 일반화 능력도 얻을 수 있다.
- Emergent Abilities
- 더 복잡한 task들에도 활용될 수 있다. 모델의 확장성
- Better interactivity and control
- 사용자로 하여금 편의성을 제공하기 위해 대화형 인터페이스를 활용
- String generalization abilities
7.3.2 Training Paradigms
- LLM-aided visual resoning system의 학습 방식 → Training-free, fine-tuning
- Training-free
- LLM의 사전학습된 가중치들을 활용하기 위해 freeze하고, LLM을 프롬프트를 통해 사용자의 요구를 충족
- reasoning system은 크게 few-shot models와 zero-shot models로 나눌 수 있음
- few-shot model → hand-crafted in-context samples를 수반하여 LLM에게 guidance를 제공
- zero-shot model → LLM의 언어적/영역적인 능력과 추론 능력을 직접적으로 활용
- Finetuning
Improving Planning Abilities 할때 주로 사용
→ 모델이 어떠한 과정을 통해 문제를 해결할 것인가에 대한 계획을 세우는 능력
7.3.3 Functions
- LLM-Aided Visual Reasoning system에서 LLM은 어떤 role을 수행하는가
| What roles LLMs exactly play in LLM-Aided Visual Resoning System | ||
|---|---|---|
| LLM as a Controller | complex tasks → simple sub tasks/steps → assign tools/modules | 세분화된 문제들에 대해서 어떤 tool을 활용할 것인가? (Task Planning) |
| LLM as a Decision Maker | summarize the current context/history information → decide if the information at the current step is sufficient to answer the question → organize the answer to present | 현재의 맥락과 이전까지의 정보들을 요약 → 현 단계에서의 정보를 활용하여 문제를 해결할 수 있는지 판단 → 정답들을 요약하여 user-friendly way로 present |
| LLM as a Semantic Refiner | integrate information into natural language sentences | 종합된 정보들을 자연어로 변환하여 의미적으로 맞도록 정제 |
8 Challenges and Future Directions
- 현재의 MLLM은 long context (긴 문맥)을 처리하는데 한계가 있음
- MLLM은 더 복잡한 instructions를 따를 수 있도록 발전해야함
- M-ICL이나 M-CoT와 같은 기술들에 있어서 더 발전할 수 있는 부분이 많이 남아있음
- MLLM이 탑재된 물리적인 로봇(신체화된), embodied Agent를 개발
- 안정성 문제 → crafted attacks에 아직 취약함
9 Conclusion
- GPT/Gemini 와 같은 모델들은 end-to-end, 즉 다양한 멀티모달 데이터로 하나의 모델 안에서 모두 처리할 수 있는 엄청..거대한 모델이라면,
- Multimodal Encoder + pre-trained LLM + Multimodal Interface로 구성된 MLLM들은 조립식 구조를 가짐
→ OFA는 MLLM의 이상향에 가깝다.