AI+X 선도인재양성프로젝트 [AI-Plant Management Service]
AI+X 고급 프로젝트
Sep 2, 2025 ~ Dec 13, 2025
프로젝트 개요
AI+X 프로젝트 고급과정은 자율 프로젝트였고, 실제로 서비스로 구현하는 것까지가 목표였다.
AI+X 고급 프로젝트의 주제는 사용자 맞춤형 식물 관리 서비스였다.
프로젝트에서의 역할 : AI모델 개발
- 사람들이 반려 식물을 키우면서 가장 힘들어하는 것이 바로 ‘물주기’이다.
따라서, 우리는 이 ‘물주기’를 사용자가 키우고 있는 반려식물에 맞춰서 조절할 수 있는 서비스를 개발하기로 했다.
기존에 있는 서비스들은 모두 기본적은 일반 관수주기에 대한 정보는 알려주는 정도였다. 하지만, 우리 서비스의 차별점은 바로 이미지를 기반으로 현재 식물의 상태를 진단하고, 이에 맞는 관수 주기를 제공해주는 것이 핵심이었다.

‘식물을 부탁해’의 핵심 기능
- 식물 종 분류
- 식물의 상태 진단
- 식물의 상태에 따른 관수주기 조절
데이터셋
활용할 데이터셋 : 원예식물(화분류) 물주기(수분공급 주기) 생육 데이터 / AIHub
- 사실 데이터셋을 직접 수집할 수 있는 주제를 하고 싶었지만, 여건상 그러진 못했다.
- 정량 제어가 가능한 자동 관수 시스템(양액기)을 통해 수분 공급량을 차등 조절하며 수집한 이미지 및 센서 데이터이다.
- 각 재배환경별로 관수량(AmtIrrigation), 토양습도(HighSoilHumi, LowSoilHumi), 흙 상태(SoilState), 재배환경(Environment) 등의 항목이 메타데이터(JSON)에 기록되어 있으며, 이를 통해 환경별 수분 공급 차이를 학습 데이터로 활용할 수 있었다.
- 데이터셋 내에는 15종의 식물에 대한 정보를 담고 있었으며, 식물의 잎에 대한 Annotations, 식물의 상태 (건조, 일반, 과습), 그리고 성장률, 높이 등 다양한 정보를 가지고 있었다.

- 이렇게 식물의 상태별로 이미지가 존재하였으며, 식물의 상태 진단은 데이터 셋을 구축할 때에, 센서를 통해 해당 식물의 토양습도(HighSoilHumi, LowSoilHumi), 흙 상태(SoilState), 재배환경(Environment) 등의 항목들을 통해 라벨을 부여한 것이다.
AI 모델 개발 과정
- AI 모델 개발 쪽과, 전체적인 프로젝트 진행 관리를 맡았다.
- 우선 처음에 데이터셋에 존재하는 15종의 식물을 분류하도록 하는 다중분류 모델을 학습시켰다.
- 하지만, 첫 번째 문제점이 있었다.
위의 사진처럼, 학습 데이터 속에는 식물 뿐만 아니라 화분, 벽, 서랍 등 다양한 배경 또한 존재하였다. 저 데이터셋으로 식물 15종을 분류하는 것은 과적합의 위험이 높다고 판단했다.
→ 따라서, 우선 주어진 이미지에서 식물만을 타이트하게 Crop할 방법이 필요했다.
💡 YOLO를 통해 식물만을 타이트하고 Crop하고, Crop한 이미지를 통해 식물의 종을 분류하도록 설계하였다.
📌 식물 종 분류 모델 파이프라인
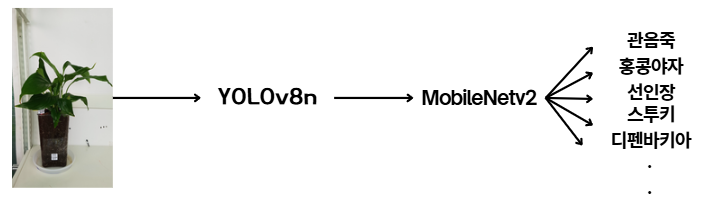
- 우선 YOLO 와 MobileNetv2를 사용하였다.
- 사용자로부터 이미지를 입력받으면 YOLO를 통해 식물 부분을 Crop하고, 그 이미지 데이터를 통해 해당 식물이 15종 식물 중 어떤 식물인지 분류한다.
YOLO 학습
- YOLO에게 ‘plant’라는 새로운 class를 부여하는 전이학습 (Transfer Learning) 방식을 선택하였다.
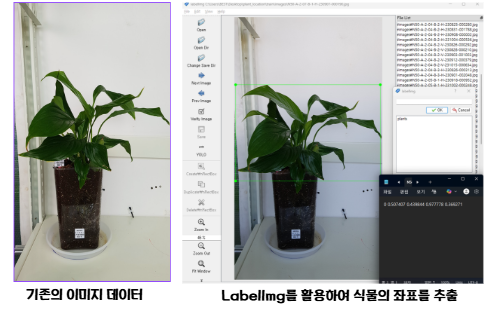
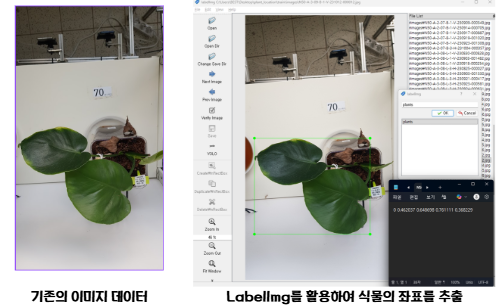
- LabelImg 툴을 활용하여 우리가 가진 이미지 데이터셋에서 YOLO가 학습할 식물 좌표를 수동으로 생성해주었다.
📌 YOLO 전이학습 방식 : 이미지 데이터 + 식물의 좌표
전이학습한 YOLO를 우리가 가진 이미지 데이터셋 전체에 적용하여 조금 더 깨끗한 (분류 모델이 식물 자체에 집중할 수 있도록) 데이터셋을 다시 구축해주었다.

MobileNetv2 학습
- YOLO를 통해 타이트하게 crop한 15종의 식물에 대한 데이터셋을 통해 MobileNet을 학습시켰다.
모델 학습 상세 사항
- 입력 데이터 설정 (Input Configuration)
- 모델 입력 크기 (Input size) : 299x299
- 전처리 방식 (Preprocessing)
- 수치 범위 : -1.0~1.0
- 데이터 증강 (Augmentation)
- 좌우 반전, 회전, 확대/축소, 대비조절
- 모델 아키텍처 (Model Architecture)
- Backbone : MobilenetV2 (weights : “imagenet”)
- 분류기 헤드 (Classifier Head)
- Global Average Pooling : 특징 맵을 1차원 벡터로 변환
- Dense Layer : 128
- Dropout : 0.5
- Output Layer : 15 (15종 분류)
- 학습
- Batch size : 32
- Loss Function : Sparse Categorical Crossentropy
- Optimizer : Adam
임계값 설정 (Threshold)
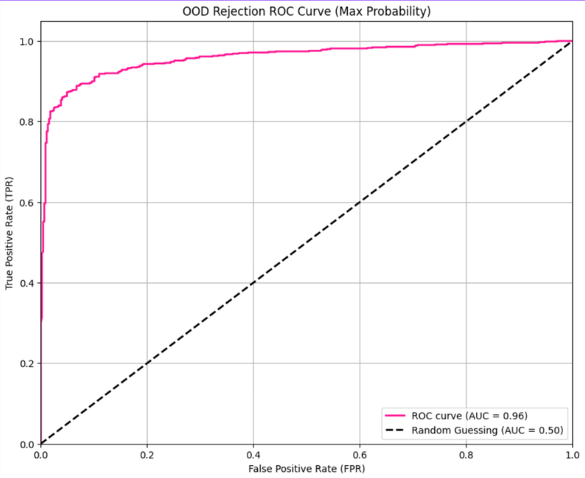
- 학습한 식물이 15종이 아닌 경우엔, ROC 커브를 통해 오분류 비율(FPR)을 3% 미만으로 줄이는 임계값 0.93으로 설정했다.
📌 식물 상태 진단 모델 파이프라인
- 식물 종 분류 모델과 동일하게 YOLO와 MobileNet을 사용하였으며, 이미지 데이터의 메타데이터에 포함되어 있는 식물 잎 Annotations를 활용하여 YOLO를 학습한 후, crop한 식물의 잎을 통해 식물의 상태를 진단하는 모델을 학습하였다.
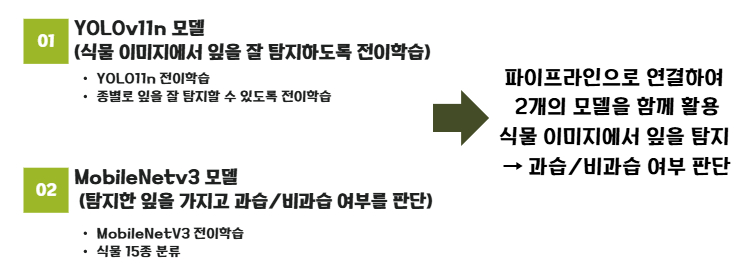
모델 학습 상세 사항 (YOLOv11-Nano)
- 모델 아키텍처 (Model Architecture)
- YOLOv11 Nano
- 핵심 학습 전략
- 해상도를 키워가며 2단계로 학습
| 단계 | 목표 | 해상도 | Epochs/Batchsize |
|---|---|---|---|
| Stage 1 | 구조 학습 | 960px | 15/8 |
| Stage 2 | 디테일 강화 | 1280px | 10/4 |
- 데이터 증강 (Augmentation)
- Mosaic (1.0)
- Mixup (0.15
- Copy-Paste (0.15)
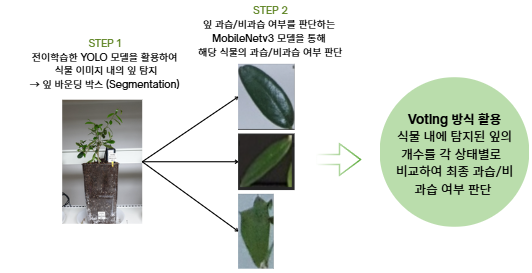
모델 학습 상세 사항 (MobileNetv3)
- 입력 데이터 설정 (Input Configuration)
- 모델 입력 크기 (Input size) : 224x224
- 전처리 방식 (Preprocessing)
- tf.keras.applications.mobilenet_v3.preprocess_input (MobileNetV3 전용 전처리 함수 사용)
- 데이터 증강 (Augmentation)
- 좌우 반전, 회전, 확대/축소, 대비조절
- 모델 아키텍처 (Model Architecture)
- Backbone : MobilenetV3-Large (weights : “imagenet”)
- 상단 분류기 제거 (include_top=False)
- 분류기 헤드 (Classifier Head)
- Global Average Pooling : 특징 맵을 1차원 벡터로 변환
- Dropout : 0.4
- Output Layer : 3
- 학습
- 클래스 가중치 계산
- 데이터가 적은 클래스 → 틀리면 가중치 크게
- 데이터가 많은 클래스 → 가중치를 낮게
- Batch size : 32
- Loss Function : Sparse Categorical Crossentropy
- Optimizer : Adam
- Callbacks : EarlyStopping, ReduceLROnPlateau
- 클래스 가중치 계산
식물 맞춤형 관수 주기 조절
식물 맞춤형 관수 주기 조절은 식물의 특성에 맞는 가중치를 부여하여 조절하도록 하였다.
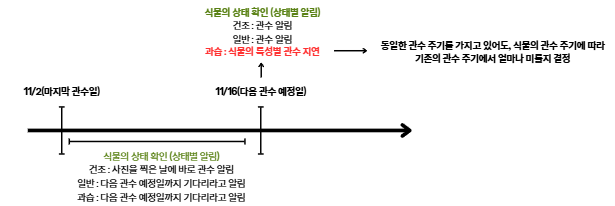
- 만약 사용자가 식물의 사진을 통해 식물의 관수예정일에 상태를 진단받았는데, 과습이 나왔을때가 관수 예정일을 미뤄야할 때라고 판단했다.
- 건생 식물은 상대적으로 과습에 약하며, 습생 식물은 과습에 강하다

- 우리가 가진 데이터셋의 식물 특성 별로 평균 관수 주기를 계산한 후, 식물의 특성별 관수 주기 가중치를 비례식을 통해서 결정해주었다.
📌 얼마나 미룰 것인가? → 기존의 관수 예정일 + 각각의 식물 관수 주기 x 식물 카테고리별 가중치


- 이렇게 식물의 특성에 맞추어서, 관수 예정일을 미루는 방식으로 식물의 상태에 맞는 관수 주기를 유연하게 바꿀 수 있도록 설계했다.
서비스 개발 (모바일 웹 형태)
Front-End
- Figma를 통해 UI설계
- React 활용
Back-End
AWS-S3 저장소 구축 및 전반적인 API 설계 / 관련속성
- 메서드: GET, POST, PATCH, DELETE, PUT
- 서버 검증: 액세스키와 프라이빗 키를 통한 보안 강화.
- 각 API 테스트를 통한 배포전 테스트 빌드 수행.
FAST API / 관련속성
- uvicorn 가상환경 활성화
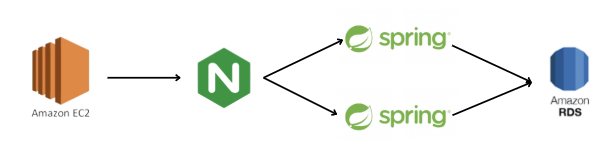
- 모델 배포 환경 구축
- AI모델 서버/Spring 서버 2개 배포
- 스프링 서버에서의 코드베이스 작성
- 각 엔드포인트 및 데이터 요청값 작성
- webclient 라이브러리를 통한 ai 모델 호출
프로젝트 추후 계획 (현재 진행 중 25.12.13 ~ )

- 건생/습생/중생 식물 종별로 1개의 종씩 식물을 구입하여, 우리가 개발한 서비스를 통해 키운 것과, 인터넷에서 제공하는 기본 관수주기를 지켜서 식물을 키웠을 때의 성장률(잎의 크기, 식물의 높이 변화)을 통하여 해당 방식으로 식물을 키우는 것이 적합하다는 것을 직접 확인해보는 과정 중에 있으며, 관련 논문을 작성 예정 중에 있다.
📌느낀점
- 식물의 종을 분류하는 것이 굉장히 간단할 줄 알았는데 정말 어려웠다.
- 식물의 아주 작은 시각적 특징을 잘 인식 못하는 것 같다.
- 사실 AI+X 프로젝트를 진행하면서 직접 데이터 셋을 수집해보고 싶다는 생각이 강했다. 결국 직접 수집한 경험은 하지 못했지만, 직접 라벨을 부여하면서 어떻게 모델에게 양질의 데이터를 줄 수 있을까에 대한 고민을 정말 많이 해본 것 같다.
- 이후 프로젝트 관련 논문을 교수님께서 쓰자고 하셨는데, 논문을 작성해보는 것은 처음이어서 정말 좋은 경험이 될 것 같다.
- 정말 많은 시행착오가 있었다…. 너무 힘들었다.. 힘든만큼 많이 배운 것 같다..