AI+X 선도인재양성프로젝트 [Fine Dust Forecast]
AI+X 중급프로젝트
Apr 17, 2025 ~ Mar 9, 2025
[프로젝트 개요]
중급프로젝트의 첫번째 프로젝트는 [미세먼지 농도 예측 머신러닝 모델링]이었다.
이번 프로젝트의 목표는 새로운 도메인의 학습데이터를 탐색하고 분석에 용이하도록 전처리한 후, 머신러닝 모델을 완성하여 테스트 데이터에 대해 예측하고 평가하는 것이었다.
서울 지역의 미세먼지 데이터와 날씨 데이터를 활용 , 미세먼지 예측에 관련 있는 데이터 항목으로 데이터를 구성 , 전처리 하여 미세먼지 농도를 예측하는 머신러닝 모델 구현
미세먼지란?
- 아주 작은 크기의 모든 오염물질
- 입자의 지름이 10마이크로미터 이하인 먼지 : PM-10
- 입자의 지름이 2.5마이크로미터 이하인 먼지 : PM-2.5
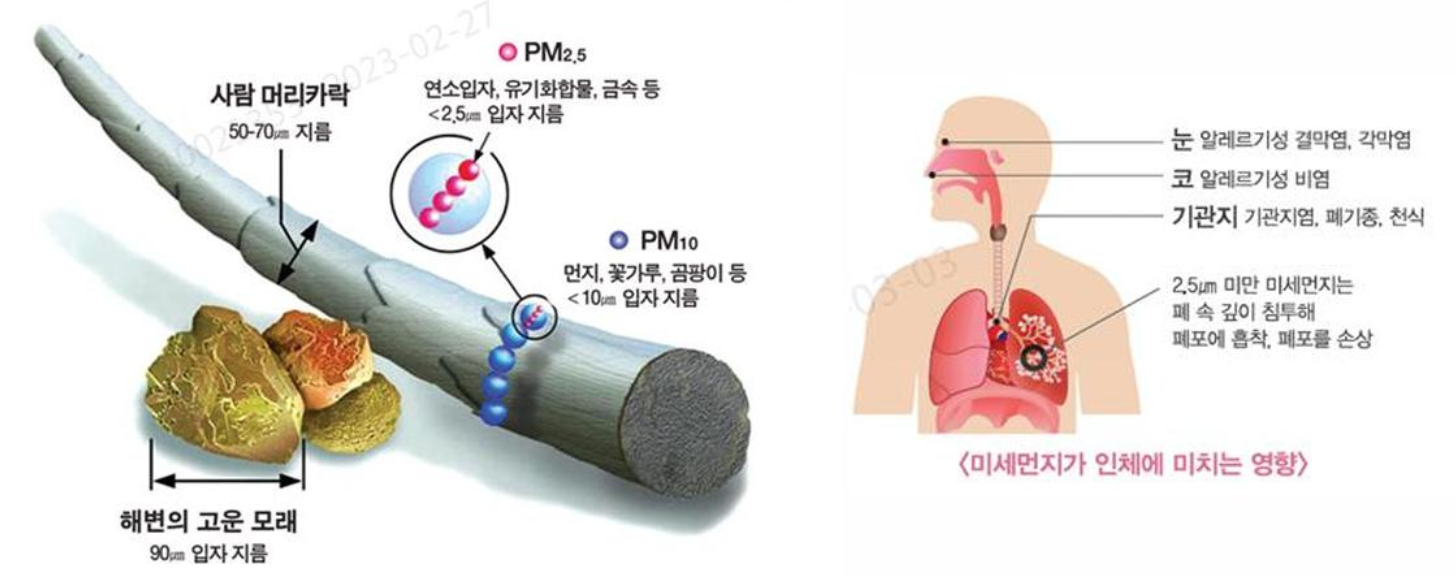
현재 대한민국은 환경부에서 대기오염으로 인한 국민건강 피해를 최소화하기 위해 미세먼지 농도를 하루 4번 예보하고 있으며, 예보 등급을 좋음, 보통, 나쁨, 매우나쁨의 4단계로 구분하고 있다.

- 미세먼지는 후에 사람의 기관지에 큰 문제를 일으킬 수 있으므로, 예보의 정확도가 매우 중요하다!
미세먼지 농도를 예측하려는 이유
- 미세먼지 자체를 없애는 것은 사실상 불가능 하므로 노출 최소화를 위해 미세먼지 농도 예측
- 중국 등 국외 요인보다는 국내의 기상상태에 따른 2차 미세먼지의 생성이 큰 영향을 미침
- 미세먼지 측정소는 특정 지역에 집중되어 있지만, 기상자료 측정소는 전국에 골고루 위치해 있기 때문에, 기상자료를 통하여 미세먼지 농도를 예측할 수 있다면 유용할 것이다.
⇒ 대기오염/미세먼지 자료와 기상자료개방포털의 다양한 기상자료를 수집하여 예측에 있어 중요한 시간 데이터를 변수로 포함시켜 머신러닝 모델을 구현하고자 한다
[데이터 소개]
우리가 활용한 데이터는 다음과 같다.
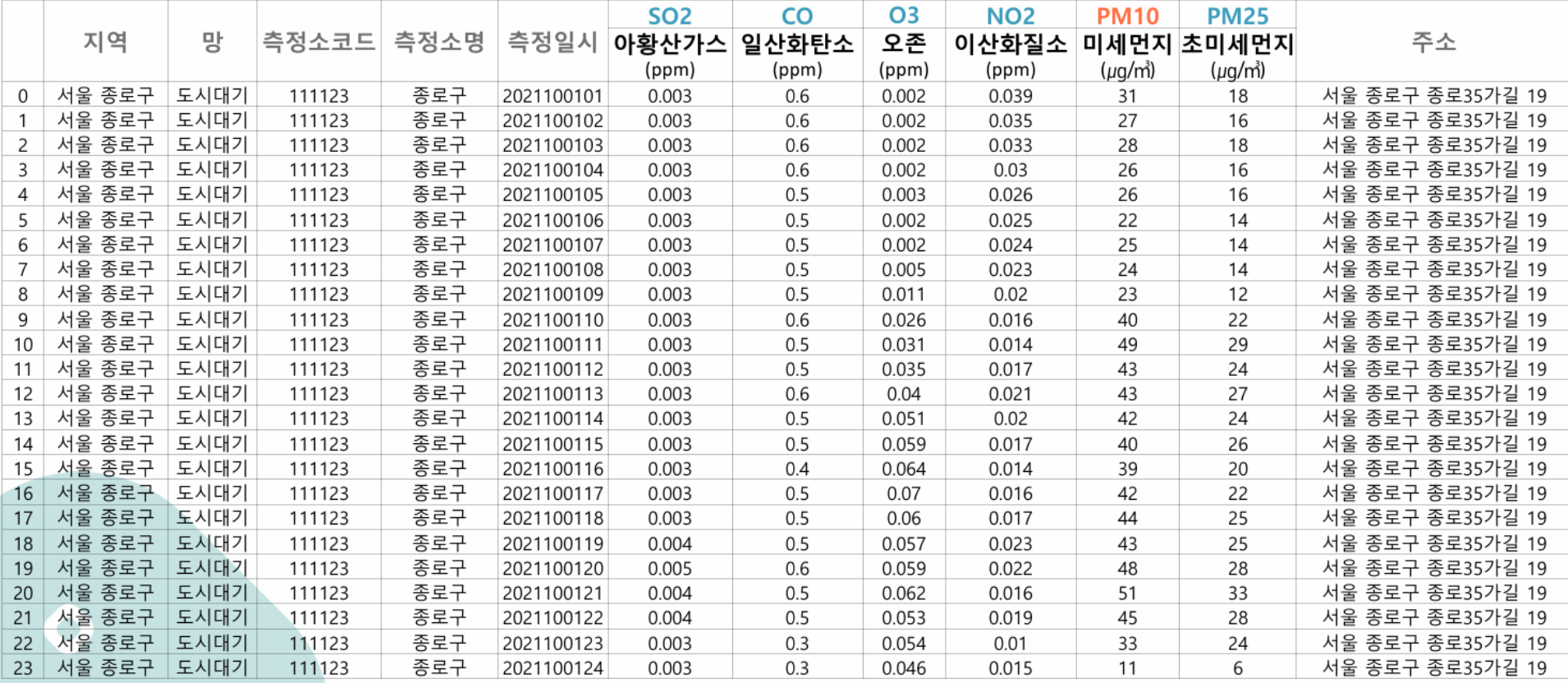
- air_2021/2022.csv
- 먼저 에어코리아의 미세먼지 및 오염물질 정보 데이터를 살펴보면, 종로구 지점에서 측정한 SO2(아황산가스), CO(일산화탄소), O3(오존), NO2(이산화질소), PM10 (미세먼지), PM25(초미세먼지) 와 같은 변수들을 가지고 있다.
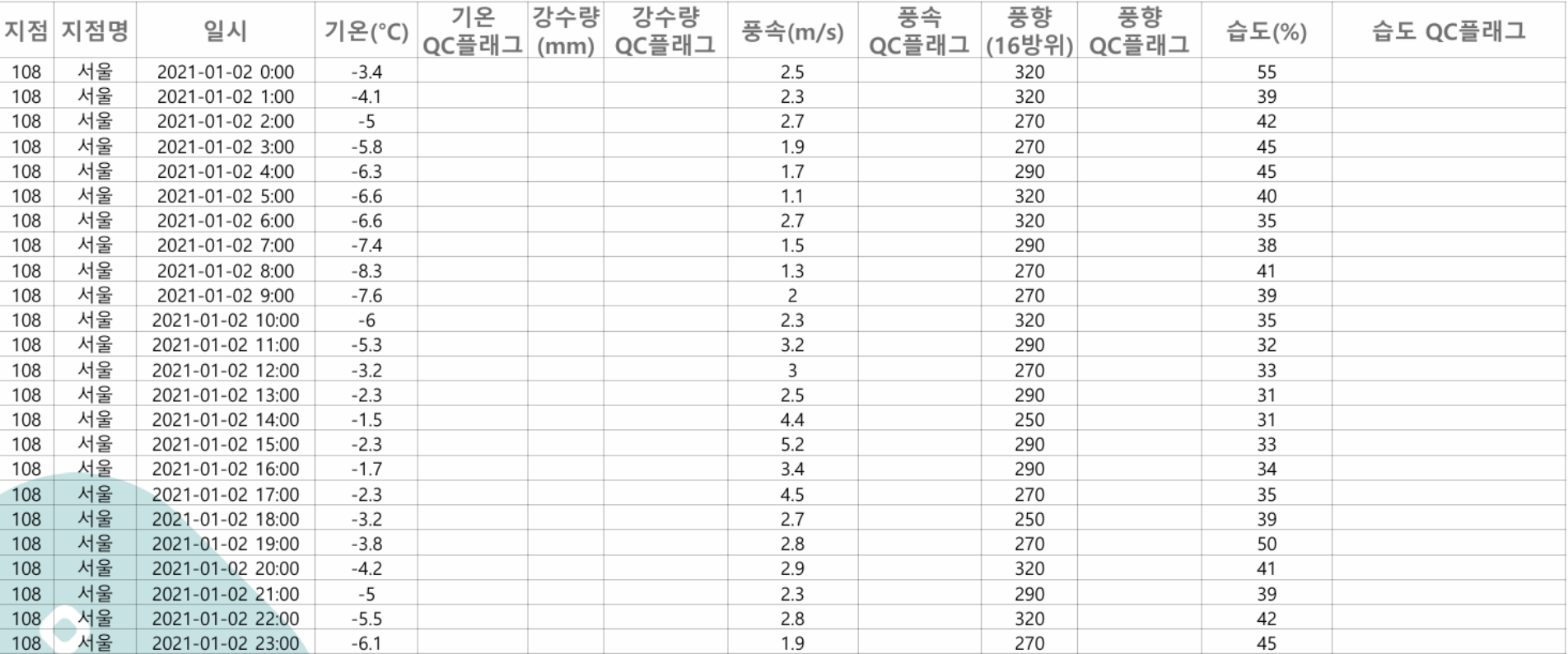
- weather_2021.csv
- 기상청의 날씨정보 데이터는 서울의 기상과 관련된 전반적인 데이터들로 구성되어있으며, columns을 살펴보면 기온, 강수량, 풍속, 풍향, 습도 등 다양한 변수들로 이루어져 있었다.
| 변수명 | 설명 |
|---|---|
| 증기압 | 증기가 고체 또는 액체와 동적 평형 상태에 있을 때 증기의 압력 ( 증기가 되려는 힘 ) |
| 이슬점 온도 | 불포화 상태의 공기가 냉각될 때 , 포화 상태에 도달하여 수증기의 응결이 시작되는 온도 |
| 일조 | 일정한 물체나 땅의 겉면에 태양 광선이 비치는 시간 (1 시간 중 비율) |
| 일사(량) | 태양으로부터 오는 태양 복사 에너지가 지표에 닿는 양 ( 면적당 에너지 량 ) |
| 전운량 | 하늘을 육안으로 관측하여 전부 구름일 때 10, 구름이 덮고 있는 하늘의 비율에 따라 0~10 |
| 중하층운량 | 중층과 하층에 있는 구름의 분포량 ( 중하층 구름이 날씨에 영향 주므로 따로 표기 ) |
| 운형(운형약어) | 구름의 종류. 약어 코드로 기재됨 |
| 최저운고 | 가장 낮은 구름의 높이 |
| 현상번호(국내식) | 비 , 소낙비 , 싸락눈 , 눈보라 등의 기상현상을 나타낸 코드번호 |
| 지면온도 | 지면 0 c m 온도 |
| 지중온도 | 땅 속 온도 |
[데이터 전처리]
우선 데이터들을 살펴보았을때, 불필요한 변수들도 굉장히 많았으며, 결측치 또한 매우 많았다. 프로젝트의 최종 목표는 미세먼지 농도를 예측하는 것이기 때문에, 미세먼지 농도 예측을 위해 불필요한 변수들을 우선 제거하였고, 데이터에 포함된 결측치들을 어떻게 채울 것인지에 대해 먼저 의논하였다.
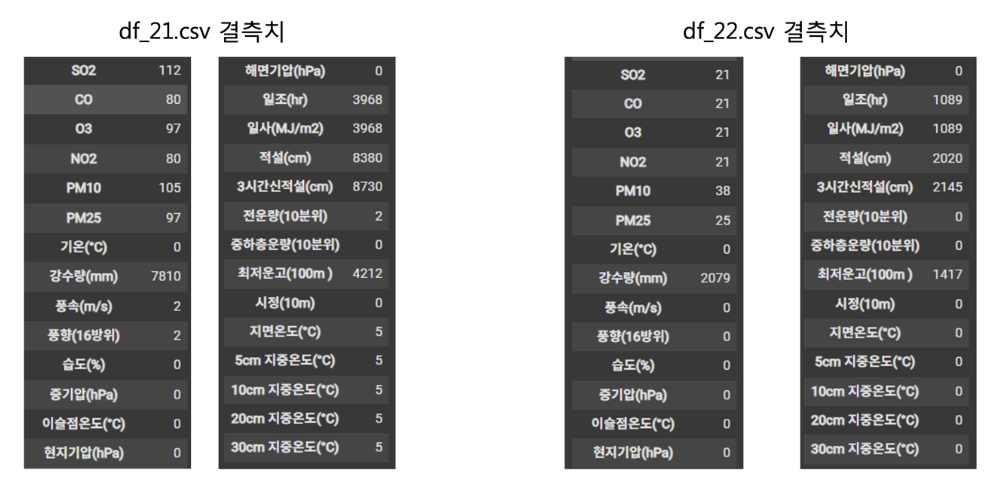
- 보다시피 결측치가 매우 많이 존재했으며, 각 변수의 특성에 맞게 선형보간 혹은 0으로 채워 결측치들을 제거하였다.
| 변수명 | 결측치 처리 방식 | 이유 |
|---|---|---|
| 강수량 | NaN → 0 | 에어코리아에 문의한 결과, 공란은 무강수를 의미함 |
| SO2, CO, O3, NO2, PM10, PM25 | 선형보간 | 해당 결측치는 같은 날짜, 동일한 시간대에 2시간 동안만 존재했으며, 이는 측정기의 점검으로 인해 발생한 결측치임을 에어코리아의 홈페이지를 통해 알 수 있었으며, 대기환경과 관련된 변수들이기에 선형보간으로 채워주었다. |
| 풍속, 풍향 | 선형보간 | 풍향과 풍속이 시간별로 크게 달라지지 않을 것이라고 생각 |
| 일조, 일사 | NaN → 0 | 결측치가 존재하는 시간대가 모두 밤~새벽이기 때문에, 일조와 일사량은 0으로 처리 |
| 전운량 | 선형보간 | 시간에 따라 자연스럽게 변화할 것이라고 생각 |
| 지중온도, 지면온도 | 선형보간 | 온도와 관련된 변수들 또한 시간에 따라 자연스럽게 변화할 것이라고 생각하여 선형보간으로 처리 |
- 위와 같이 결측치들을 제거한 후, 데이터의 분포와 상관관계를 다시 확인해보았다.
- 위의 그래프 말고도 더 다양한 방식으로 확인해보았으며, 분포의 차이는 크게 나지 않는 것을 확인할 수 있었다.
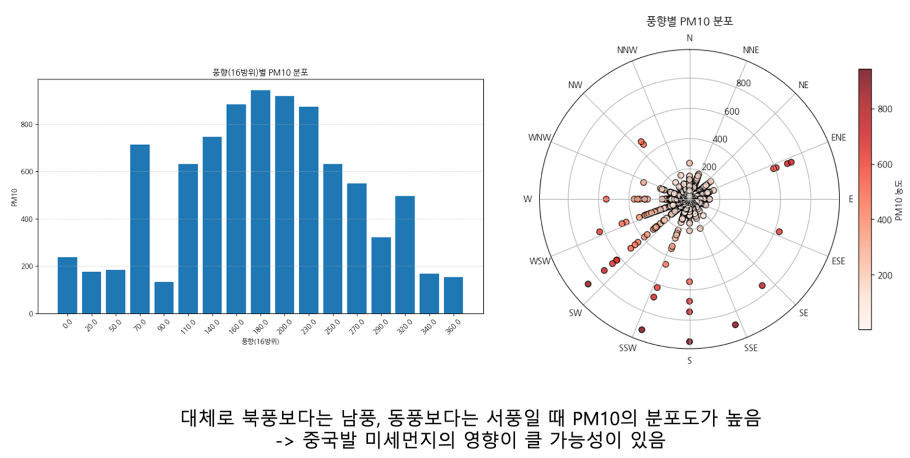
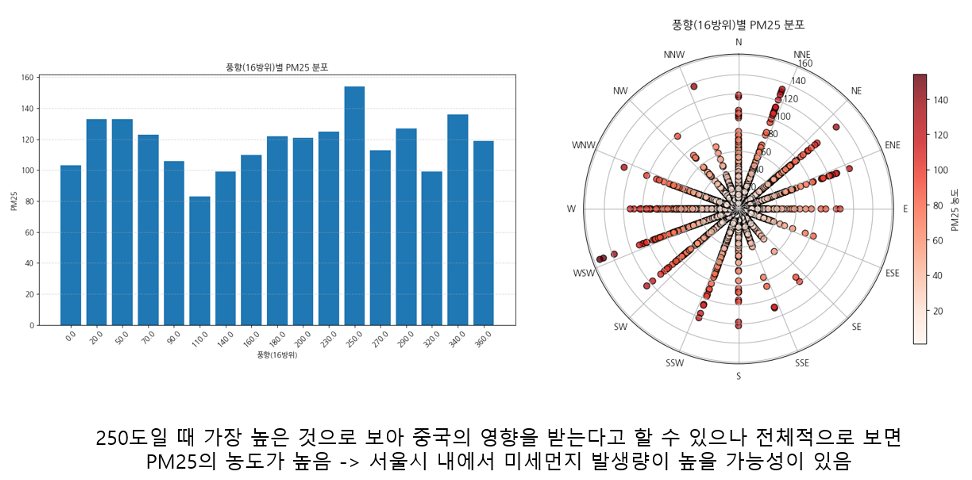
번외로, 풍향 데이터를 활용하여 실제로 미세먼지가 중국의 영향을 받는지 확인해보았다.
PM10 (미세먼지) 는 실제로 북풍, 서풍일때 PM10의 분포가 많았으며, PM25(초미세먼지)는 풍향의 분포를 보았을때, 중국의 영향이 없진 않지만, 서울시 내에서 발생하는 경우가 많은 것을 확인할 수 있었다.
[모델링]
우선 우리의 최종 목표는 미세먼지 농도를 예측하는 것이기 때문에, 결국엔 연속형 데이터를 예측해야한다. 따라서 우리는 연속형 모델인 RandomForest, XGBRegressor, LGBMRegressor 를 사용하였다.
모델을 학습할때에는 데이터에서 학습에 활용할 변수들을 선택하는 것 또한 매우 중요하다고 생각하기 때문에, 우리는 변수들을 다르게 선별하여 학습을 진행해보았다.
[회귀 분석]
- 전체 변수 사용
- PM10을 변수에 포함
- PM10을 변수에 미포함
- 일부 변수 사용 (결측치가 많았던 변수 모두 제외)
- PM10을 변수에 포함
- PM10을 변수에 미포함
- 단계별 선택법
- PM10을 변수에 포함
- PM10을 변수에 미포함
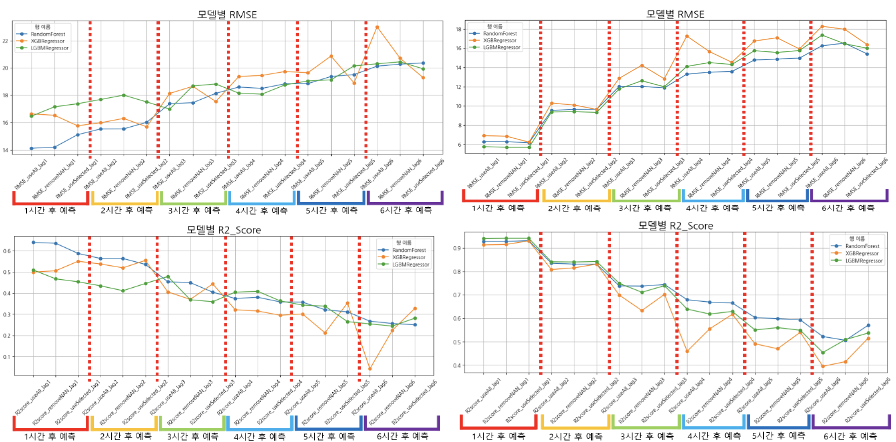
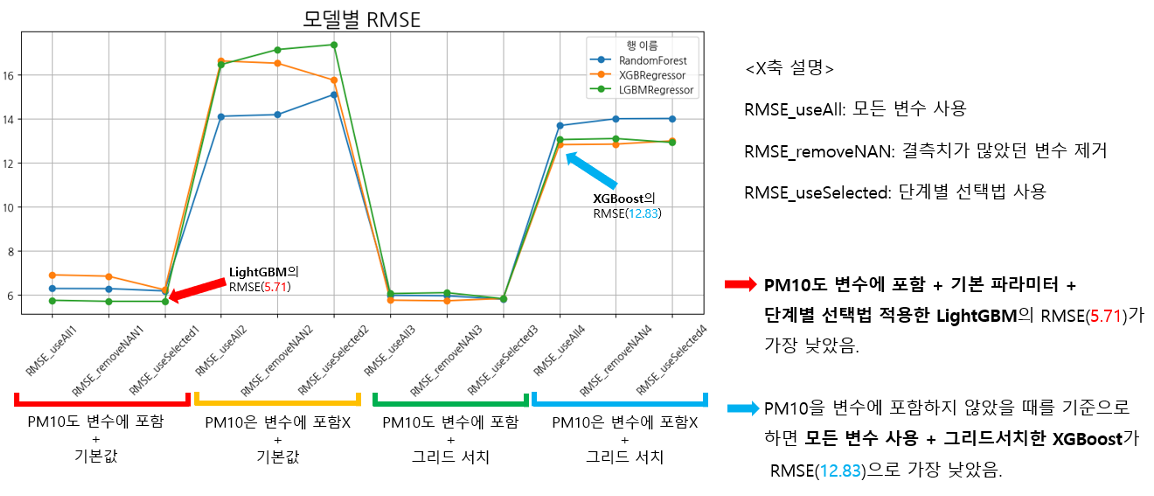
[모델 성능 비교_RMSE]
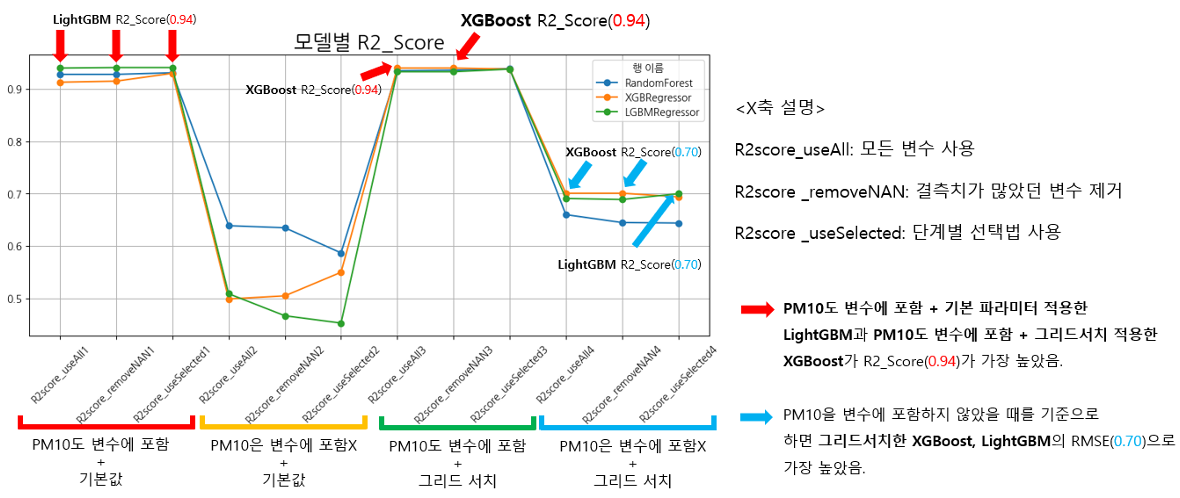
[모델 성능 비교_R2score]
[향후 6시간까지의 예측 성능 평가]
⇒ RMSE는 시간이 지날수록 증가하며, R2_score는 시간이 지날수록 감소하고 있다. 즉, 예측하는 미래의 시점이 멀어질수록 성능이 점점 떨어지는 것을 알 수 있었다.
회귀 분석 Insight
- 회귀 분석에 PM10(미세먼지 농도) 변수, 즉 미세먼지를 직접적으로 나타내는 변수를 포함시킨다면 성능이 매우 높다.
- PM10_1 (1시간 전의 미세먼지 농도)를 변수에 포함시켰을때, 모델의 성능이 매우 좋다.
- 예측하려는 시점이 멀어질수록 성능이 떨어진다.
⇒ PM10은 과거 자신의 영향을 많이 받을 가능성이 크다
⇒ 시계열의 성향이 매우 강하다!
- 현재 시점의 대기 상태를 이용하여 장기 예측을 하는데는 한계가 존재한다.
⇒ PM10 및 대기상태가 1시간 단위로 빈번하게 변할 가능성이 높다
[시계열 분석]
- 시계열 분석으로는 크게 2가지로 진행해보았다.
- 단변량 시계열
- AR, ARIMA
- 다변량 시계열
- ARIMAX, LSTM
- 단변량 시계열
AR (자기회귀)
- 자기 회귀 모델은 수집 데이터의 과거/현재 값으로 미래의 값을 추정한다.
- 이종 데이터의 관계를 이용하는 것이 아닌, 해당 데이터의 time delay를 이용
- 차수 p : p시간 전의 데이터를 활용
어떻게 적절한 차수 (p)를 설정할까?
- 부분 자기 상관 함수를 사용
- 퓨리에 변환을 통해 주기를 추출
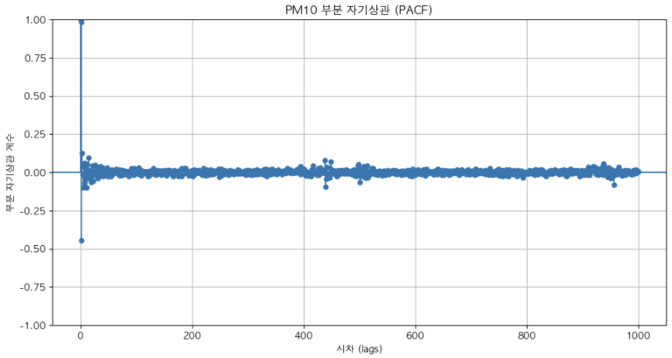
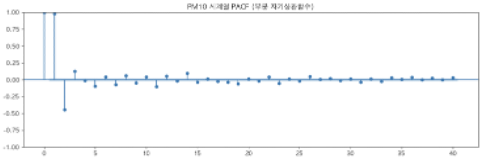
부분 자기 상관 함수
- 과거 자기 자신과 비교하여 상관관계를 계산
⇒ 과거 1시점 전에서 강한 양의 상관관계가 나타남 ( p = 1 로 설정해보자 )
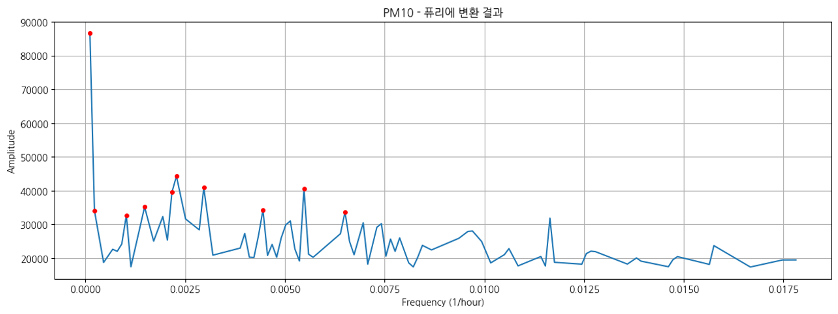
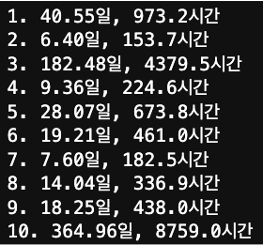
퓨리에 변환
- 진폭이 큰 상위 10개의 주기 추출
- 진폭이 크다?
⇒ 시계열 전체에서 얼마나 강하고, 반복적으로 나타나는지 표현
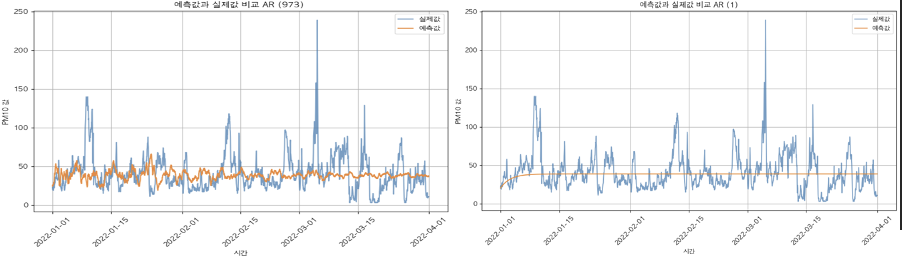
⇒ AR (p=973)로 설정!
[자기회귀 성능]
| p = 973 | p = 1 | |
|---|---|---|
| RMSE (제곱 평균 오차의 제곱근) | 24.3 | 23.5 |
| MAE (절댓값 평균 오차) | 16.7 | 16.5 |
| MAPE (백분율 기준 오차) | 70.5% | 70.5% |
| R² (결정 계수, 예측력이 얼마나 좋은지) | -0.067 | -0.0037 |
⇒ 결정계수가 음수가 나오는 것으로 보아 반 정도도 예측을 못하는 것을 알 수 있다.
ARIMA (Autoregressive Integrated Moving average Model)
- 다음은 자기 회귀 모델에 차분과 이동평균을 더한 모델이다.
| 자기 회귀 AR (p) | 과거 값들을 선형결합하여 현재 예측 |
|---|---|
| 차분 I (d) | 비정상 시계열을 정상화하기 위해 차분 수행 |
| 이동 평균 MA (q) | 과거 오차항을 사용하여 현재 예측 |
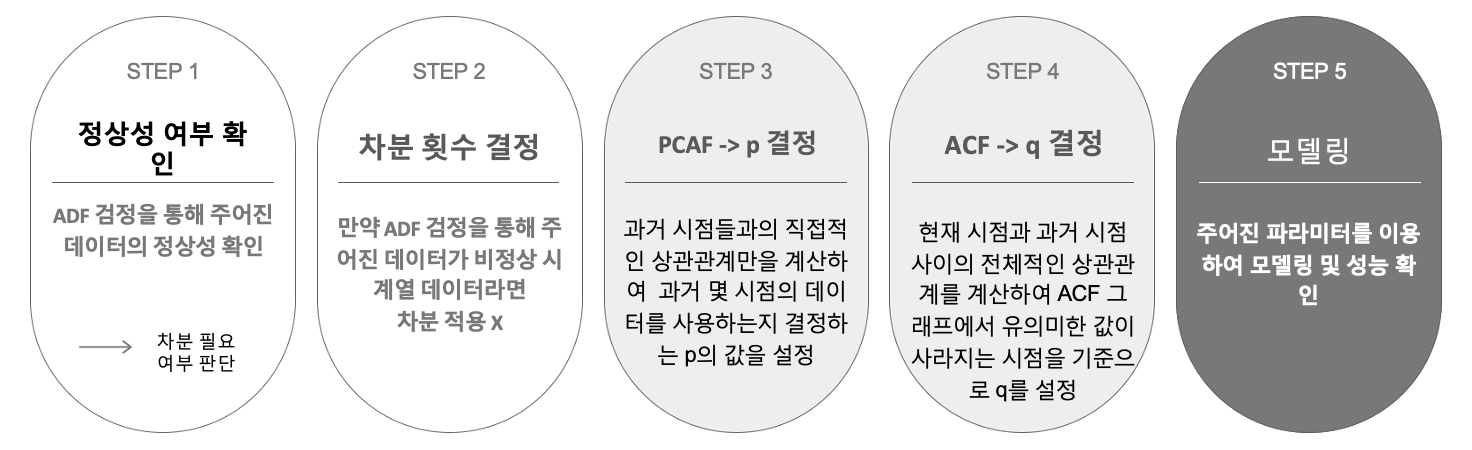
우리는 다음과 같은 과정으로 ARIMA 모델의 파라미터들을 정해주었다.
정상성 여부 확인
p-value 값이 0.05보다 작기 때문에 (단위근 존재 X), 정상 시계열임을 의미한다.
차분횟수 결정
이미 정상 시계열이기 때문에 차분 (d) = 0 으로 설정하였다.
부분 자기 상관 함수를 통하여 p 결정
앞서 자기 회귀와 마찬가지로 p=1로 설정하였다.
자기 상관 함수를 통한 q 결정
자기 상관 정도를 측정하여 오차의 영향을 받는 q 시점 확인 ( q=1 )
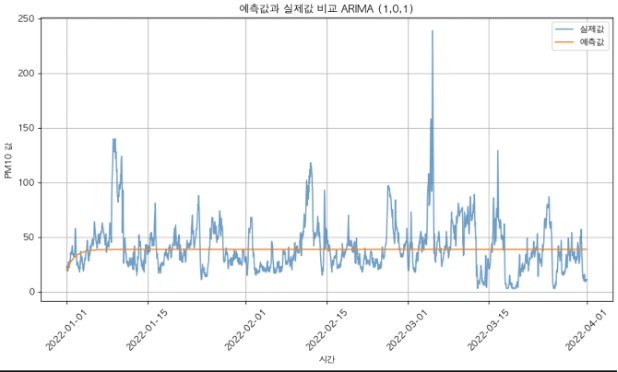
⇒ d=0, p=1, q=1로 설정한 후, ARIMA 모델링을 진행하였다.
[ARIMA 모델 성능]
| RMSE (제곱 평균 오차의 제곱근) | 23.3 |
|---|---|
| MAE (절댓값 평균 오차) | 16.3 |
| MAPE (백분율 기준 오차) | 70.1% |
| R² (결정 계수, 예측력이 얼마나 좋은지) | 0.015 |
📌 AR, ARIMA의 성능이 정말 좋지 않았다.
⇒ 따라서 외생변수를 사용할 수 있는 다변량 시계열 모델로 다시 시도해보았다.
ARIMAX (다변량 시계열)
- 기존의 ARIMA와 같은 시계열 예측 모델은 종속변수만을 사용했다면, ARIMAX는 종속변수 + 설명변수를 추가적으로 사용
| ARIMA | ARIMAX |
|---|---|
| 종속변수만 사용 | 종속변수 + 설명 변수 사용 |
| 단변량 시계열 | 다변량 시계열 |
| 자기 자신만을 기반으로 예측 | 자기 자신 이외에 추가적인 외부 요인의 영향을 반영 |
| 몇시간전의 PM10 -> PM10 값 예측 | 어제 PM10, 기온, 습도, 풍향 등 -> PM10 값 예측 |
| 시도해볼 외생 변수 | ARIMAX |
|---|---|
| PM10_lag1 ~ PM10_lag24 | lag를 민 PM 정보 활용 |
| PM10 정보 이외의 값들 | SO2, CO, O3, 기온, 강수량, 풍속 등 |
💡 단변량 시계열 vs 다변량 시계열 (PM10을 외생변수로 활용)
- 단변량 시계열도 과거의 자기 자신 값을 활용
- 다변량 시계열에서도 외생변수로 자기자신 (PM10)을 부여
⇒ 둘이 같은 것 아닌가?
- 단변량 시계열은 과거 예측 오차도 예측을 할때 사용된다.
- 다변량 시계열은 과거 예측의 오차를 포함하지 않으며, 말 그대로 정답 y값만을 외생변수로 사용한다.
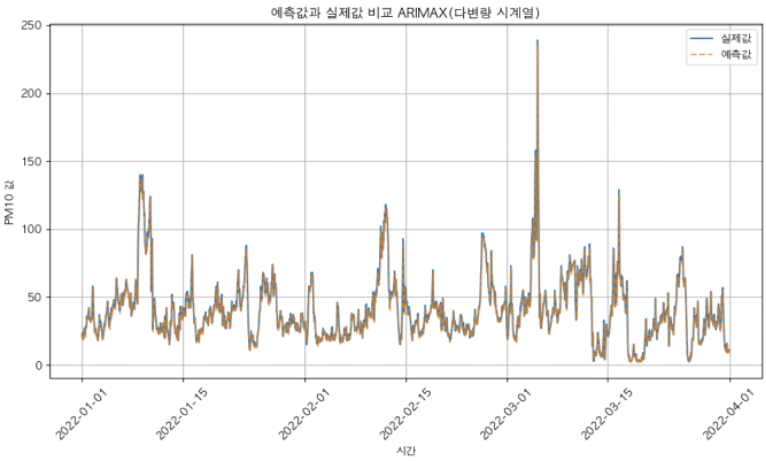
[PM10을 외생변수로 부여했을 때의 성능]
| RMSE (제곱 평균 오차의 제곱근) | 6.04 |
|---|---|
| MAE (절댓값 평균 오차) | 3.81 |
| MAPE (백분율 기준 오차) | 10.93% |
| R² (결정 계수, 예측력이 얼마나 좋은지) | 0.93 |
⇒ 외생변수로 과거의 자기 자신의 값을 부여했을때 성능이 매우 좋은 것을 확인할 수 있었다.
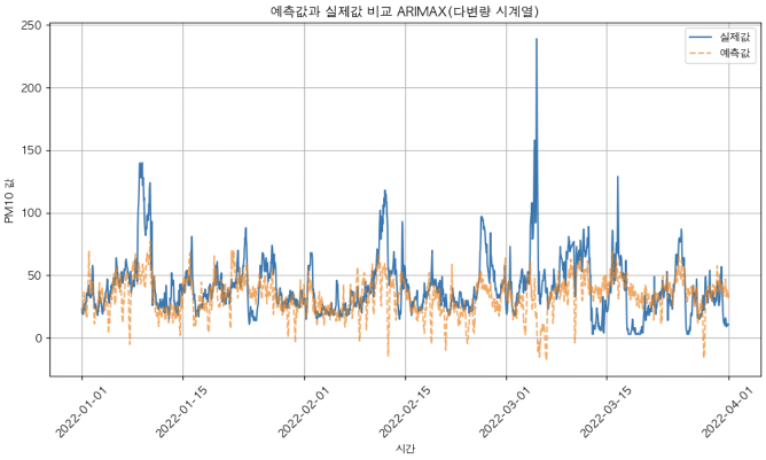
[PM10 정보 이외의 변수 활용]
| RMSE (제곱 평균 오차의 제곱근) | 22.23 |
|---|---|
| MAE (절댓값 평균 오차) | 15.90 |
| MAPE (백분율 기준 오차) | 62.50% |
| R² (결정 계수, 예측력이 얼마나 좋은지) | 0.02 |
성능이 안좋았으므로, 여기서 변수들을 따로 선별해주는 과정을 진행하였다.
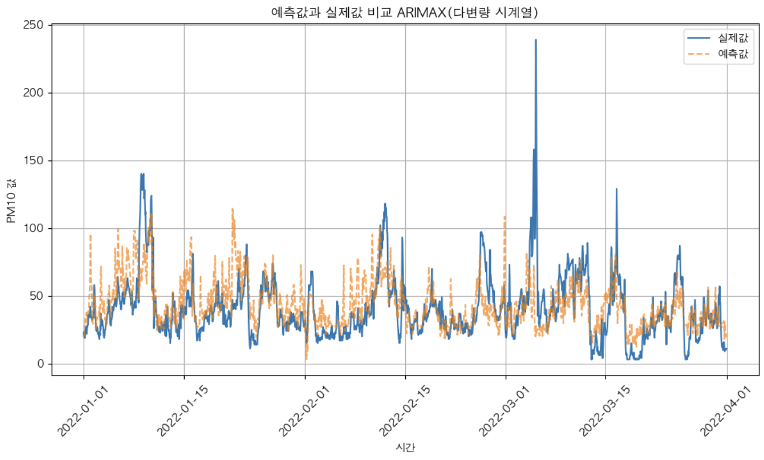
PM10, PM25 관련 변수들을 외생변수로 설정하지 않고, 어떻게 성능을 높일 수 있을까?
⇒ PM10, PM25 관련 변수들을 제외한 나머지 변수들과 PM10_1 (1시간 후의 미세먼지 농도)와의 상관계수 확인
⇒ 상위 10개의 변수들만 선정하여 설명 변수로 부여 후, 성능 확인
⇒ 변수들을 선별한 후의 성능 확인
| 모든 변수 활용 (PM10, PM25 제외) | PM10, PM25와 상관관계가 높은 변수들만 활용 | |
|---|---|---|
| RMSE (제곱 평균 오차의 제곱근) | 22.23 | 20.0 |
| MAE (절댓값 평균 오차) | 15.90 | 13.88 |
| MAPE (백분율 기준 오차) | 62.50% | 49.75% |
| R² (결정 계수, 예측력이 얼마나 좋은지) | 0.02 | 0.28 |
⇒ 성능이 눈에 띄게 좋아지진 않았지만, 그래도 성능이 개선되는 것을 확인할 수 있었다.
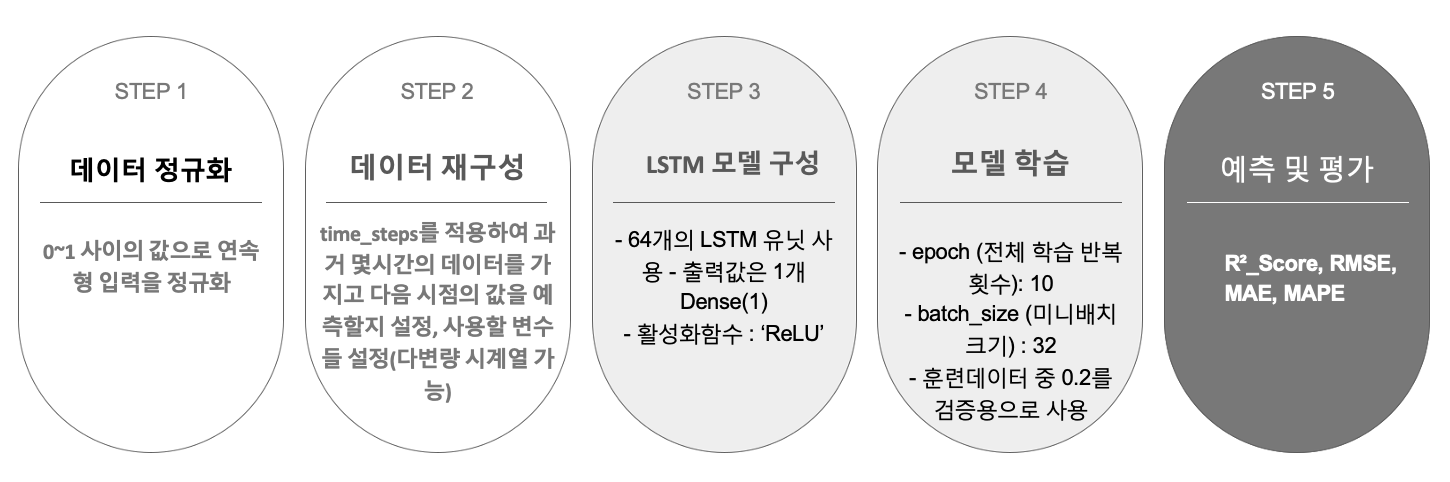
LSTM (Long Short Time Memory)
LSTM을 통한 다변량 시계열 분석은 다음과 같은 과정으로 진행하였다.
LSTM도 ARIMAX와 마찬가지로, PM10을 외생변수로 활용했을때와, PM10, PM25를 외생변수로 활용했을때로 나누어서 진행하였다.
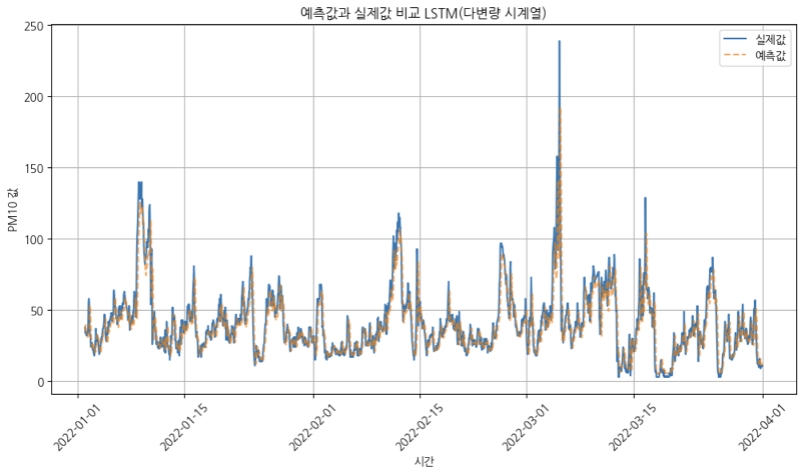
[LSTM _ lag를 민 PM10변수 활용]
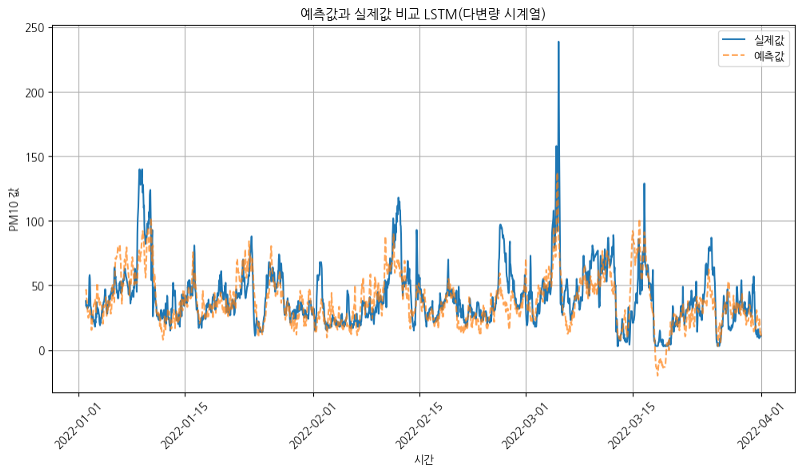
[LSTM _ PM10,PM25이외의 변수 사용]
| LSTM (lag를 민 PM10변수 활용) | LSTM (PM10 이외의 변수 사용) | |
|---|---|---|
| RMSE (제곱 평균 오차의 제곱근) | 9.42 | 17.14 |
| MAE (절댓값 평균 오차) | 7.52 | 12.04 |
| MAPE (백분율 기준 오차) | 23.08% | 38.96% |
| R² (결정 계수, 예측력이 얼마나 좋은지) | 0.84 | 0.47 |
→ LSTM도 ARIMAX와 마찬가지로 외생변수로 자기 자신의 과거 값을 부여했을때가 성능이 더 좋았다.
💡 미세먼지 농도 예측 프로젝트
- 데이터에 대한 이해가 우선적으로 필요하다!
- 데이터에 맞는 시계열 분석 모델을 선택해야한다.
- 미세먼지와 같은 데이터는 변동성이 매우 심하기 때문에, 자기 자신을 활용하는 것이 모델 성능 개선에 가장 효과적이다.
- 시계열 분석은 처음이었는데 단순 분류/회귀 모델보다 고려해야할 것들이 많아서 상대적으로 더 어렵게 느껴졌다.