AI+X 선도인재양성프로젝트 [Click-Bait Article Detection]
AI+X 중급 프로젝트_2
Mar 10, 2025 ~ June 13, 2025
중급프로젝트의 마지막 프로젝트는 팀별로 자유 주제로 프로젝트를 진행하는 것이었다.
[프로젝트 개요]
최근 AI를 통해 글을 쓰는 것이 굉장히 쉬워졌으며, 이를 통하여 확산되는 가짜뉴스와 글의 신뢰성에 대한 중요성을 느끼고 있었다. 가짜뉴스가 확산되는 경로 중 하나인 ‘낚시성 기사’를 판단해주는 AI기반 서비스를 기획하게 되었다.
해당 서비스의 이름은 “찐인가요?” 이다.

[아이디어 컨셉]
낚시성 기사 판별 서비스 ‘찐인가요?’
- 낚시성 기사를 사전에 파악할 수 있는 서비스
- 낚시성 기사로 인해 발생할 수 있는 문제들 방지
- 기사를 보는 독자의 비판적인 시각 증진
[기획 배경]
낚시성 기사란?
- 기사를 읽게 할 목적으로 자극적이고 선정적인 제목을 달아 다른 이를 꾀는 기사
- 낚시성 기사로 인한 문제점
실제 낚시성 기사 사례

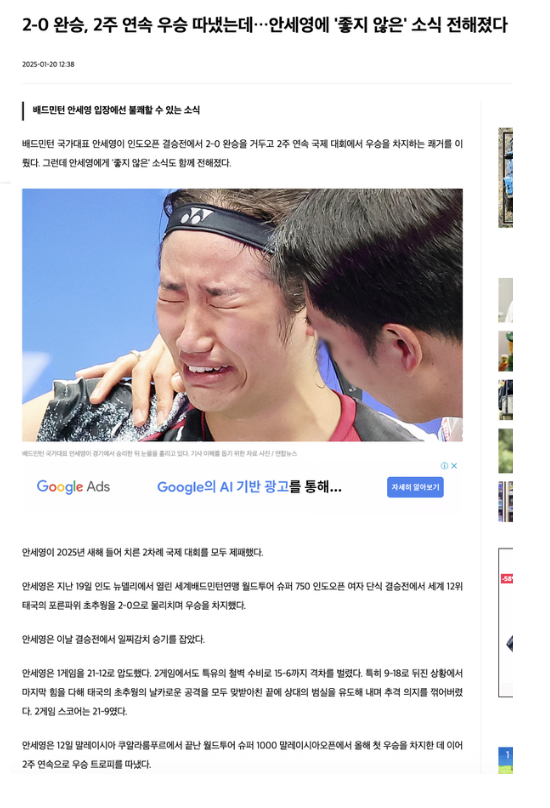
- 2025년 1월, 인도 오픈 결승전에서 대한민국 배드민턴 국가대표 안세영 선수가 승리하며 우승
- 당시 기사들은 모두 결승전의 경기 내용 혹은 안세영 선수의 우승을 축하하는 기사가 대부분
- ‘좋지 않은 소식’ 이라는 제목을 붙인 낚시성 기사가 작성
- 해당 기사의 제목을 보면 안세영 선수가 결승전을 치루는 과정이나 그 이후에 부상과 같은 불행이 닥쳤을 것이라고 생각하기 쉽다.
- 하지만, 본문내용을 읽어보면 안세영 선수에게 닥친 불행에 관한 내용 X
- 2024년 안세영 선수가 작심발언을 했을 당시의 협회장이 배드민턴 협회장 선거에 재출마한다는 내용만을 포함
- 사진 또한 2022년 항저우 아시안 게임의 사진
⇒ 이처럼 기사의 제목을 선정적이고 자극적이게 만들고, 본문 내용은 기사 제목과 다른 낚시성 기사들은 사람들에게 혼란을 유발!
💡 이를 방지하기 위해 뉴스 기사 제목과 본문이 일치하는지 판단하여 낚시성 기사인지 판별하는 서비스 기획

[데이터 활용]
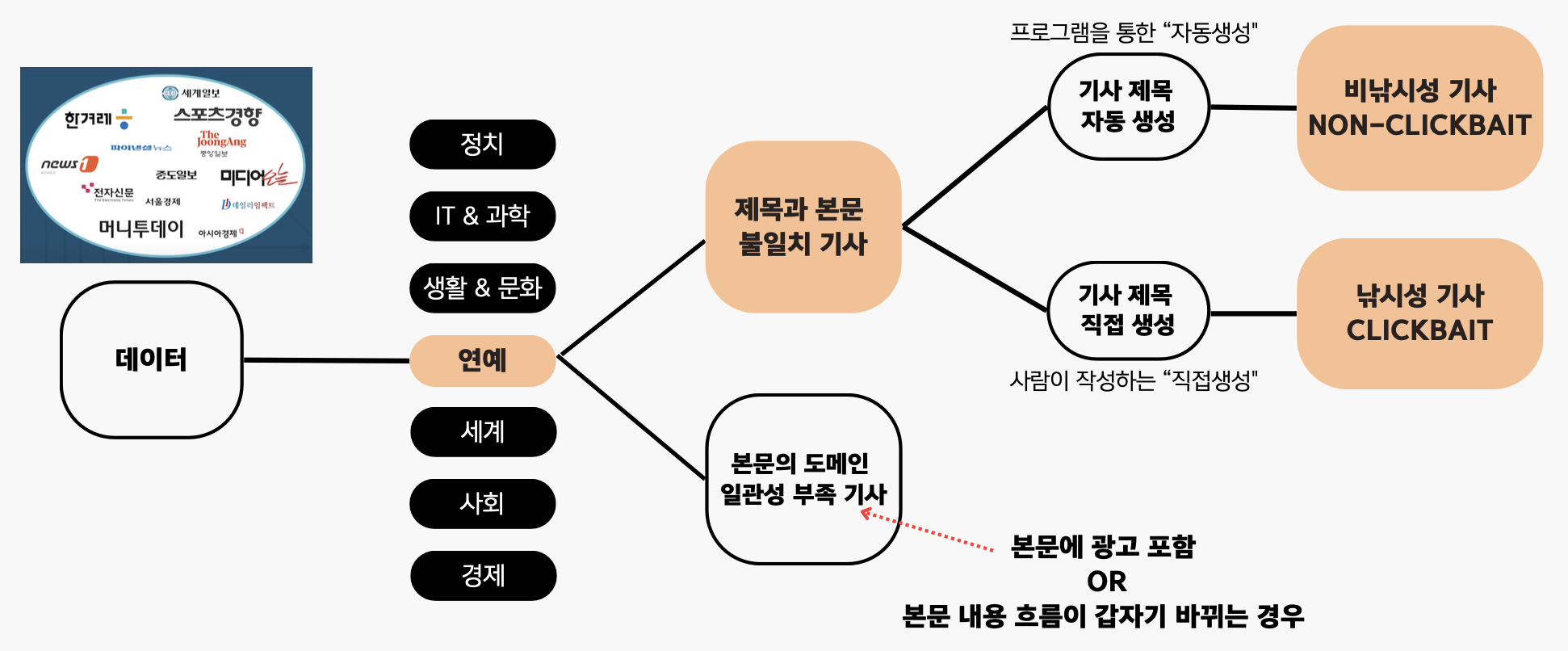
AI_Hub 의 낚시성 기사 탐지 데이터 활용
- 14개의 증권사에서 7개의 카테고리에 맞는 기사들을 모두 구입하여 생성한 데이터셋
- 낚시성 기사의 빈도와 정도가 심한 ‘연예’ 카테고리 선택
제목과 본문 불일치 기사 데이터를 활용
- json 파일로 구성, 기사의 기본 정보와 본문 내용이 문장별로 나누어져있다.
실제 낚시성 기사 데이터의 예시
기사 제목 : 전국민 ‘힐링’시킨 이효리의 진심 어린 조언

본문 내용:
6일 방송된 JTBC ‘효리네 민박’엔 장기 투숙객 삼 남매가 서울로 떠나는 모습이 그려졌다. 삼남매는 정성스레 쓴 손편지를 건네며 떠날 준비를 했다. 가방을 싸던 첫째 경화 씨는 옆에 있던 이효리에게 “30대 여자로서 고민을 얘기하고 싶다”며 “애들을 키우다 보니 제가 어떻게 될지 모르겠다”고 털어놓는다. 이에 이효리는 “너는 이미 애들을 키우면서 하루하루 힘든 시간을 견뎠다”면서 “넌 이미 충분히 네가 생각하는 것보다 강하니 항상 가슴 펴고 긍정적인 마인드로 살라”고 조언했다. 이어 “웃으면 복이 온다”는 말과 “어디에 사느냐 어떻게 사느냐가 중요한 게 아니라 내가 있는 자리에서 만족하며 사는 게 가장 좋다”고 덧붙였다. 진심 어린 이효리의 모습에 시청자들은 “이효리가 인생 선배로서 필요한 조언을 잘해준 것 같다” “이효리의 내면이 정말 아름다운 것 같다” “따뜻한 마음이 여기까지 느껴진다” 등 이효리로 인해 ‘힐링’됐다는 반응을 보였다.
⇒ 본문에서 일부 시청자들의 힐링됐다는 반응을 일반화하여 전국민이 힐링되었다고 언급
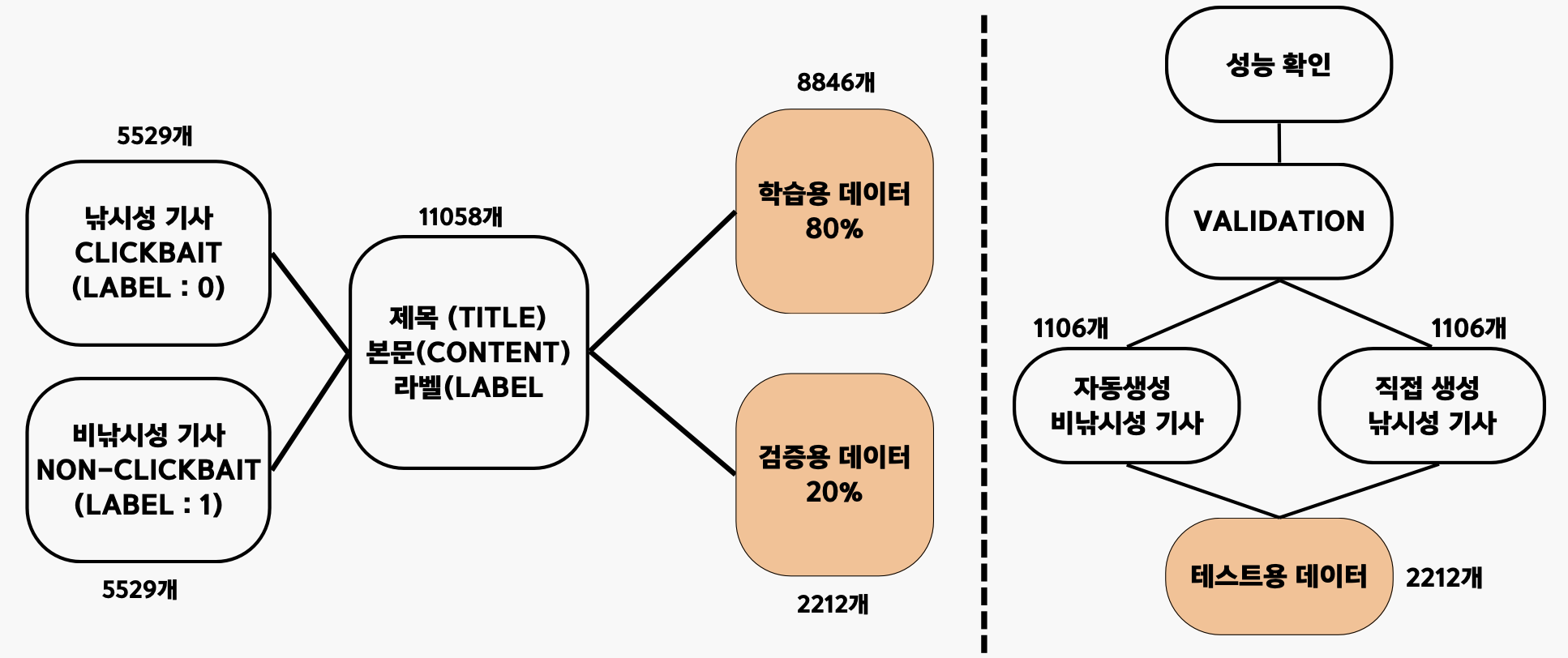
- 비낚시성 기사가 원래는 13000개로 훨씬 많았지만, 데이터 개수의 차이가 커서 모델이 편향될 가능성이 있다고 판단하여 낚시성 기사의 개수와 맞춰주었으며, 그 중 학습용 데이터와 검증용 데이터를 8:2로 나누었다.
[모델링 과정]
NLP (자연어처리)가 처음이라 어떤 모델을 활용할지 막막했다.
찾아보니 BERT라는 모델이 존재하였고, 그것의 한국어 버전인 KoBERT 모델이 있다는 것을 알게되어 활용하게 되었다.

- KoBERT 또한 BERT기반의 모델이기 때문에 우선 BERT에 대한 전반적인 이해가 필요하였다.
BERT (Bidirectional Encoder Representations from Transformers)
- 문장을 벡터로 변환하여 처리
- 양방향 트랜스포머(Transformer) 인코더 구조 사용 (단어의 앞과 뒤 단어들을 모두 고려)
- 문장을 왼쪽 → 오른쪽, 오른쪽→왼쪽 양 방향으로 동시에 이해하는 구조
- 입력 형식 : [CLS] 문장 1 [SEP] 문장 2
- CLS : 문장의 시작 (Classification token)
- SEP : 문장 경계 구분, 문장 사이 혹은 문장 끝에 사용 (Separator Token)
⚠️ 하지만, BERT는 영어 기반 모델이기 때문에 한국어에 최적화 되어 있지 않다.
BERT vs KoBERT
- BERT
- WordPiece Tokenizer 사용
- 영어 문장을 공백과 알파벳 중심으로 처리
- WordPiece Tokenizer 사용
- KoBERT
- 쉽게 말해 BERT의 한국어 버전이다!
- WordPiece Tokenizer 사용 X
- 한국어 특성상 중요한 형태소, 조사, 어미 분리를 잘 처리하지 못한다.
⇒ SentencePiece Tokenizer 사용
- 공백 없이도 문장을 subword로 나눌 수 있는 통계 기반 토크나이저
- 특히 한국어처럼 복잡한 언어에 적합 (형태소 수준의 의미 유지 가능)
- ex) “먹었다” ⇒ [”_먹”, “었다”] (_는 공백을 의미하는 기호)
| BERT | KoBERT |
|---|---|
| WordPiece Tokenizer 사용 | SentencePiece Tokenizer 사용 |
[데이터 전처리]
- 제목과 본문을 [SEP] 토큰으로 이어 붙여서 입력해야한다 ⇒ [제목]+[SEP]+[본문]
- KoBERT는 최대 512토큰까지 처리 가능
- 각 데이터 저장시 label(정답)도 함께 저장해야한다.
- 입력 (제목+본문)을 보고 정답(label)을 예측할 수 있도록하는 지도학습 방식으로 훈련하기 때문이다.
- Non-Clickbait (비낚시성) : 1
- Clickbait (낚시성) : 0
KoBERT는 데이터를 어떻게 나누는가?
- 입력단위 : Sentence Piece 토크나이저를 사용한 subword 단위
한국어의 언어적 특성과 문법 구조에 맞는 subword 분절 방식 사용

전체적인 과정
- 데이터를 토큰화
- 숫자 (ID) 로 변환
- 어텐션 마스크를 생성 (문장의 끝을 알려주기 위함, 짧다면 padding 추가, 길다면 자른다.)
- 모델의 입력으로 사용 (input_ids, attention_mask)
[KoBERT 학습]
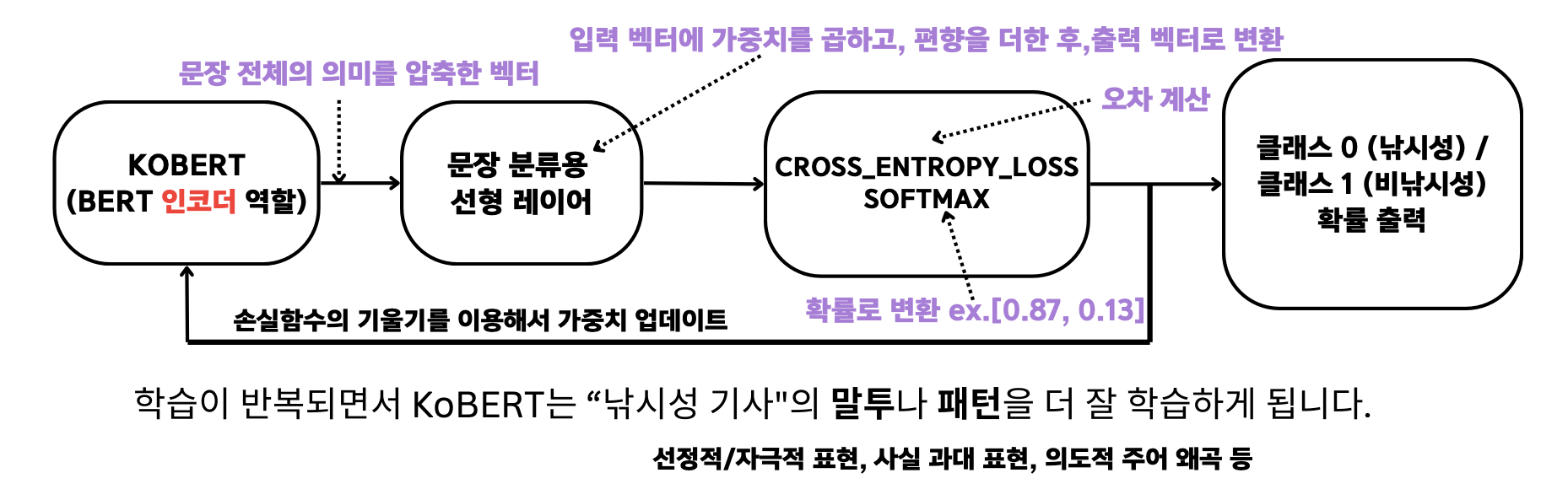
BertForSequenceClassification 모델 사용 (KoBERT 본체 + 문장 분류용 선형 레이어 포함)
- 입력 : 숫자 ID 로 인코딩된 input_ids, attention_mask
- 출력 : 클래스( 0 or 1 )에 대한 확률
정답과 비교하여 loss 계산, 이를 줄이도록 가중치 학습 (Back Propagation)
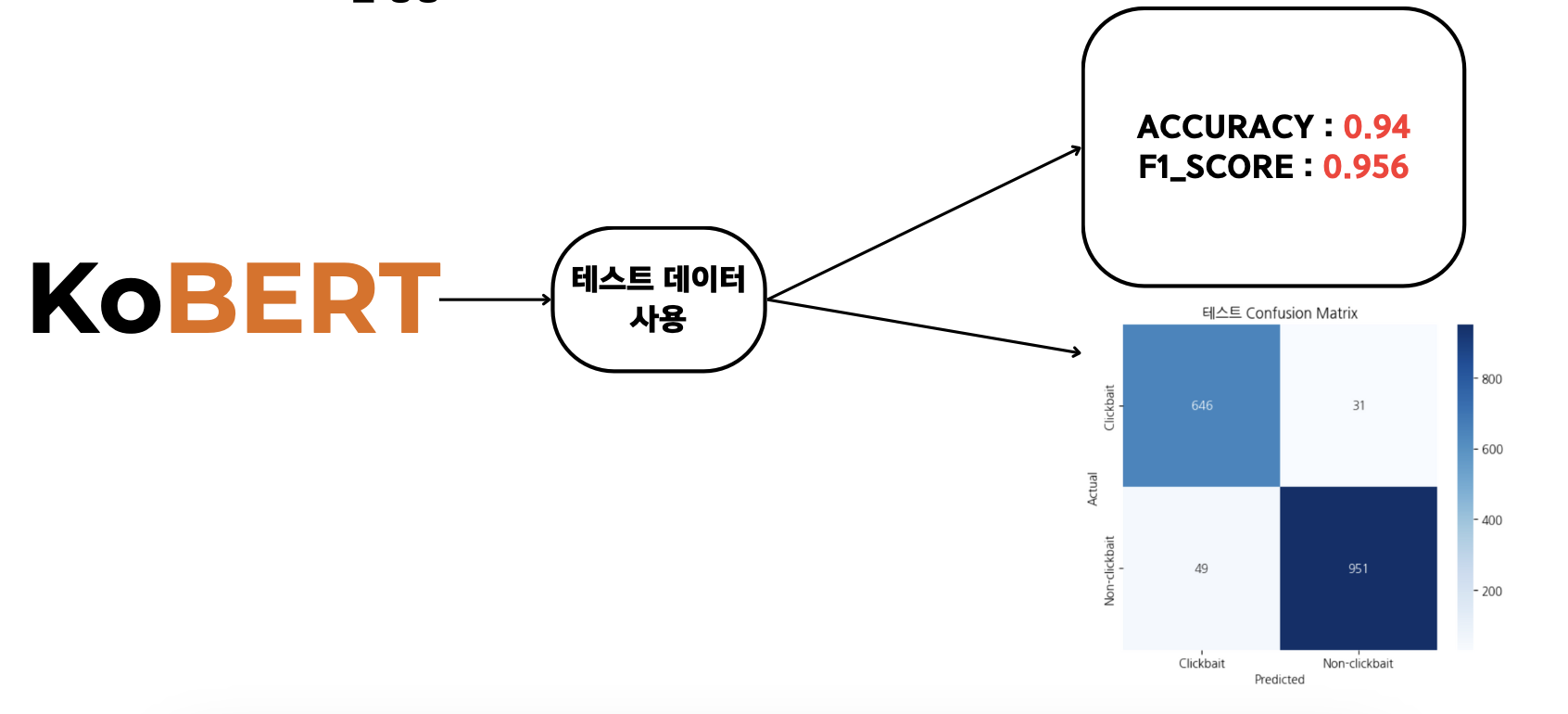
[KoBERT 모델의 성능]
💡 해당 모델을 사용자들이 어떻게 활용할 수 있을까?
- 기사 제목만 보고 해당 기사가 낚시성 기사인지 사용자에게 알려준다.
- 기사 제목과 본문 내용을 전달하면 판단해준다.
- 확장 프로그램을 사용하여 해당 기사에 마우스를 올려두면 낚시성 기사인지 작은 아이콘을 통해 알려준다.
⇒ 우리는 시간관계상 2번 방식을 선택하였고, 학습시킨 KoBERT모델을 활용한 간단한 웹서비스를 만들었다.
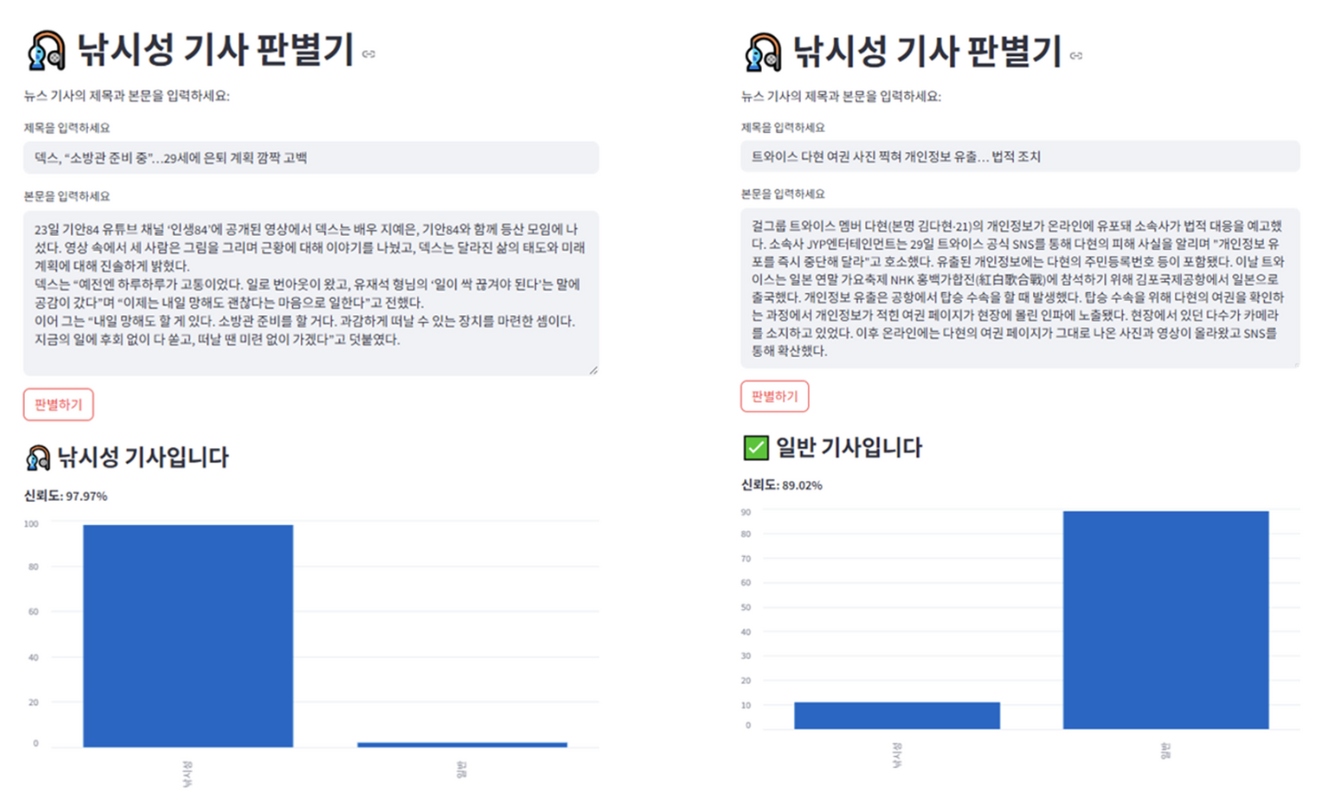
- 이 프로젝트를 주제선정, 데이터 활용, 모델 학습, 웹 구현까지 한달 정도의 시간밖에 없었기 때문에 UI/UX도 엉망이지만, 그래도 구현한 것에 의의를 두었다.
- 해당 웹에 기사의 제목과 본문 내용을 기입하면 제목과 본문 내용을 비교하여 해당 기사가 낚시성 기사인지 판별해주며, 그에 따른 확률도 출력해준다.
[왜 낚시성으로 분류하는지?]
- KoBERT 모델은 딥러닝 기반의 모델이며 수많은 파라미터들과 비선형 함수로 구성되었기 때문에 구체적으로 해당 데이터를 왜 낚시/비낚시성 기사로 판단하는지 출력하는 건 불가능
- XAI (Explainable AI) 기법을 활용하여 KoBERT 모델이 데이터를 받았을 때 어떤 토큰에 Attention을 많이 부여하는지 확인함으로써 간접적으로나마 모델이 어떤 단어에 집중하는지 알 수 있었다.
앞서 소개한 안세영 선수와 관련된 낚시성 기사를 활용하였으며, KoBERT 모델을 활용하여 512개의 토큰으로 나누고, 어떤 토큰에 Attention이 많이 부여되는지 확인해보았다.
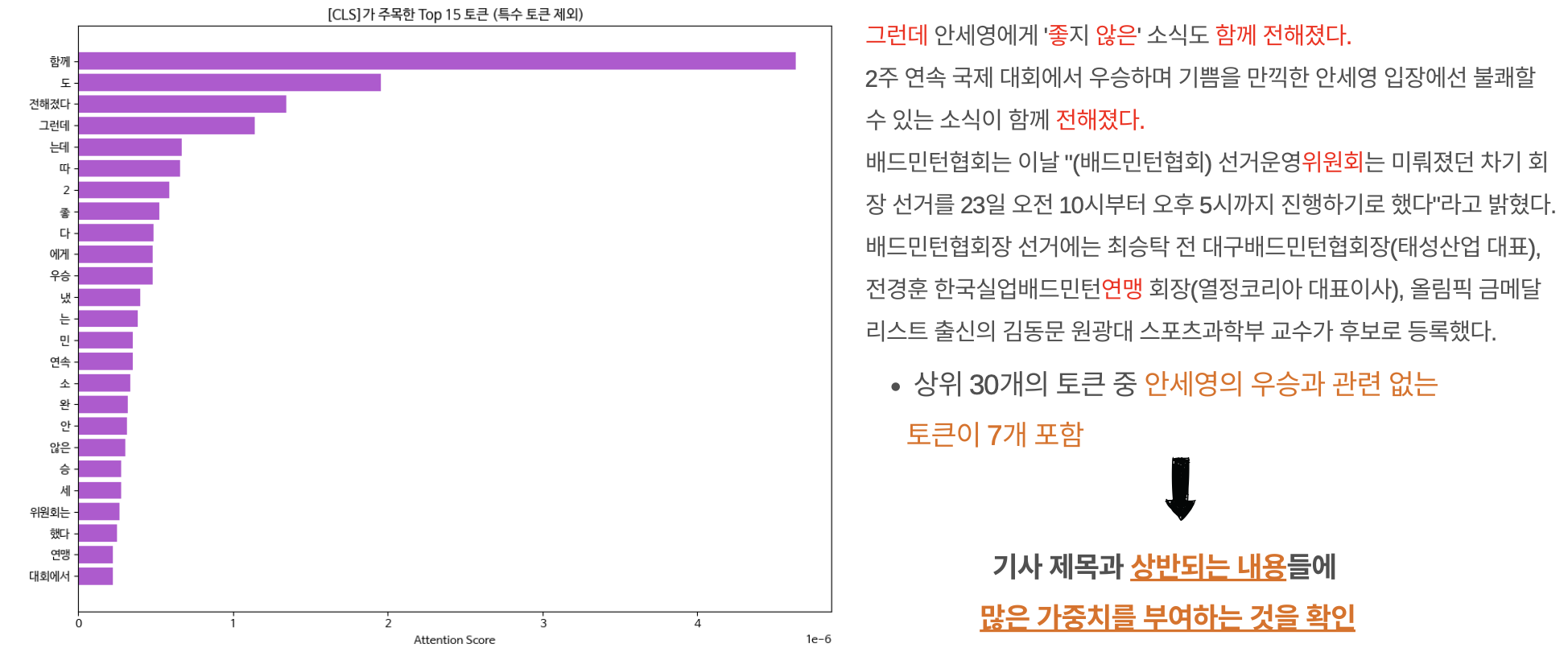
- 기사의 제목과 상반되는 내용들에 꽤 많은 가중치를 부여하는 것을 확인할 수 있었다.
- ‘그런데’, ‘좋-’ , ‘않은’, ‘위원회’, ‘연맹’ 등 기사의 본문 내용에서 안세영 선수의 우승과 관련없는 내용들에 적지 않은 Attention을 부여하고 있다.
⇒ 기사의 제목과상반된 내용에 모델이 집중하고 있다는 것을 알 수 있었다.
📌 느낀점
자연어처리에 도전한 것은 처음인데, 사실 사람들이 사용하는 언어와 한국어 특유의 언어적 특성을 모델이 잘 이해할 수 있을까? 라는 의문이 들었었는데, 모델의 성능이 좋아서 놀랐었다. 아쉬운 점은, 데이터를 직접 수집하는 과정도 경험해보고 싶었는데, 시간이 매우 촉박하여 정제된 데이터를 사용했다는 점이 아쉬웠다. 다음엔 [주제선정, 이에 맞는 데이터 수집, 데이터 전처리, 모델링, 웹/앱 구현] 이 일련의 과정을 직접 구체적으로 경험해보고 싶다.