fastai & PyTorch (4) 딥러닝
Chapter 4, Fastai Application
영상 처리 분야
- 파라미터의 가중치를 자동으로 갱신하는 확률적 경사 하강법 (SGD)
- 손실함수(Lost function)
- 미니배치 (Minibatch)
4장에서는 손으로 쓴 숫자 이미지로 구성된 MNIST 데이터를 활용
- MNIST 데이터는 학습과 검증(테스트) 데이터셋을 별도의 폴더로 분리해서 보관하는 일반적인 머신러닝 데이터셋의 구조를 따른다.
1
2
3
path=untar_data(URLs.MNIST_SAMPLE)
path.ls()
(path/'train').ls() # 학습 데이터셋의 폴더 내용확인
(#2) [Path('/Users/seungwookim/.fastai/data/mnist_sample/train/7'),Path('/Users/seungwookim/.fastai/data/mnist_sample/train/3')]학습 데이터셋의 폴더 내용을 확인해보니 3과 7인 폴더가 있는 것을 확인할 수 있었다. 여기서 ‘3’과 ‘7’은 데이터셋의 레이블이라는 용어로 표현한다.
1
2
threes=(path/'train'/'3').ls().sorted()
sevens=(path/'train'/'7').ls().sorted()
- 다음과 같이 각각의 레이블된 폴더를 확인할 수 있었다. 폴더는 수많은 이미지 파일로 가득 차 있었다.
- 수많은 이미지 파일들 중 하나를 확인해보겠다.
1
2
3
im3_path=threes[1]
im3=Image.open(im3_path)
im3
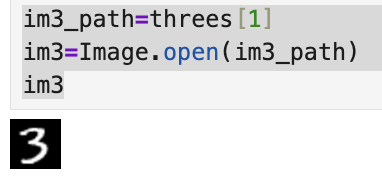
- 파이썬(Jupyter Notebook)에서는 영상 처리 라이브러리 (PIL)이 존재하기 때문에 다음과 같이 이미지를 화면에 즉시 출력할 수 있다.
컴퓨터가 이미지를 처리하는 방식
- 컴퓨터는 모든 것을 숫자로 표현한다. 이미지를 구성하는 숫자를 확인하려면 이미지를 넘파이 배열 또는 파이토치 텐서로 변환해야한다.
- PyTorch Tensor → GPU 가속이 가능한 다차원 배열 (자동 미분 지원)
1
2
3
4
# 위에서 가져온 이미지 파일을 배열로 표현
array(im3)[4:10,4:10]
# tensor로 표현
tensor(im3)[4:10,4:10]
- 위의 코드에서 [4:10,4:10]은 4부터 9까지의 요소들을 가져오는 것이며, 일반적인 행렬을 계산할땐 array, 딥러닝,GPU 연산, 자동미분을 사용하려면 PyTorch Tensor를 사용하는 것이 일반적이다.
- 4부터 9까지의 요소들을 가져오는 것이기 때문에 전체적인 이미지 파일의 좌측 상단의 모서리를 가져오는 것!
1
2
3
im3_t=tensor(im3)
df=pd.DataFrame(im3_t[4:15,4:22])
df.style.set_properties(**{'font-size':'6pt'}).background_gradient('Greys')
- 다음은 숫자의 값에 따라 색상을 그라데이션 형태로 입히는 방법을 보여주며, Pandas의 DataFrame으로 바꾸는 이유는 Tensor에서는 .style을 지원하지 않기 때문이다.
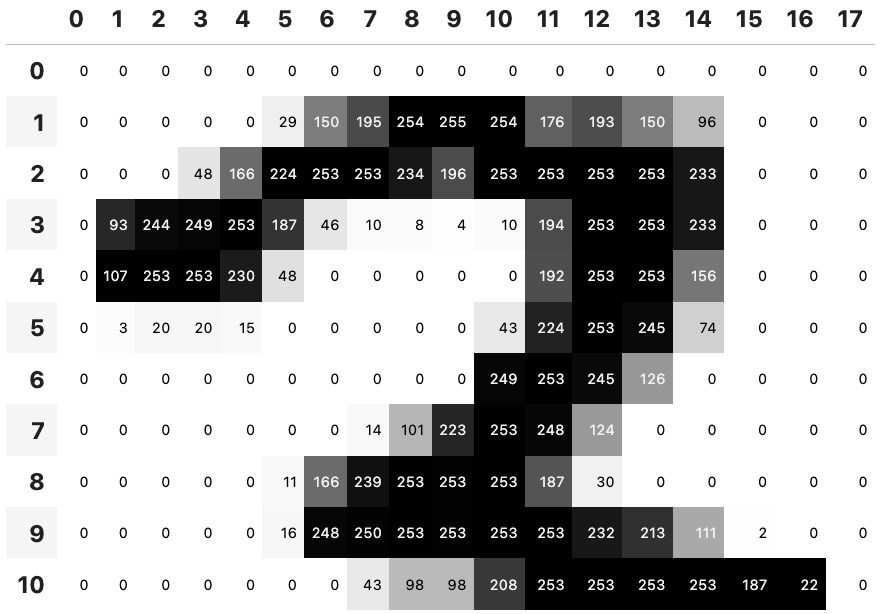
- 이렇게 컴퓨터가 이미지를 어떻게 바라보는지 알 수 있다.
그렇다면 컴퓨터가 3과 7을 구분할 수 있는 방법에는 어떤 것이 있을까?
픽셀 유사성
숫자 3과 7 각각에 대한 모든 이미지의 평균 픽셀값을 구한다.
→ 각각 ‘이상적인’ 3과 7로 정의가능(기준선,Baseline)
새로운 이미지의 픽셀값과 비교하여 어느 쪽에 더 가까운지 계산하여 분류
** Baseline (기준선) : 비교의 기준이 되는 척도, 새로운 방법이 얼마나 효과적인지 비교하는 기준
1
2
3
- 구현이 쉬운 간단 모델을 생각해보는 방법
- 유사한 문제를 해결한 다른 사람의 해결책을 찾아서 나의 데이터셋에 적용해보는 방법
모든 숫자 ‘3’ 이미지를 쌓아 올린 텐서를 만든다.
- 다음 코드는 리스트 컴프리헨션을 사용하여 각 이미지에 대한 텐서 목록으로 구성된 리스트를 생성하는 과정
1
2
3
4
# 리스트 컴프리헨션을 통해 리스트에 기대한 개수만큼의 아이템이 들어있는지 확인
three_tensors=[tensor(Image.open(o)) for o in threes]
seven_tensors=[tensor(Image.open(o)) for o in sevens]
len(three_tensors),len(seven_tensors)
** 리스트 컴프리헨션 (List Comprehension) [표현식 for 요소 in 반복가능객체 if 조건식]
→ 기존 리스트에 조건을 적용하거나 변형하여 새로운 리스트를 간결하게 만드는 문법
이미지 중 하나를 검사하여 리스트가 제대로 만들어졌는지 확인
** PIL 패키지의 Image가 아니라 Tensor 형식으로 담긴 이미지를 출력하려면 fastai가 제공하는 show_image 함수를 사용한다.
1
show_image(three_tensors[6000]);

우리의 목표는 모든 이미지를 대상으로 각 픽셀 위치의 평균을 계산하여 각 픽셀의 강도를 구하는 것.
- 리스트 내의 모든 이미지를 3차원 (rank-3)텐서 하나로 결합해야한다. (각 픽셀 위치별 평균을 빠르게 계산 가능)
- 보통의 이미지는 2차원이지만, 모든 이미지(다수의 이미지)를 결합해야 각각의 이미지들의 같은 위치에 있는 픽셀 값들에 대한 평균을 구하기 쉽다.
- 만약 원래 2차원 이미지가 28x28 픽셀 크기이고, 이미지가 100장이 있다면 3차원 텐서로 100x28x28로 표현할 수 있다.
** 평균 계산 등 파이토치가 제공하는 일부 연산은 정수 대신 부동소수형 데이터만을 지원하기 때문에 앞서 본 픽셀값들을 0~1 범위의 값으로 변환해주어야한다.
1
2
3
4
# torch.stack()을 사용하여 3차원 텐서로 결합, 형변환
stacked_threes=torch.stack(three_tensors).float()/255
stacked_sevens=torch.stack(seven_tensors).float()/255
stacked_threes.shape
3차원 배열을 만들고, 픽셀값들을 부동소수형으로 형변환을 시켜준다.
텐서는 shape이 중요하다. 각 축의 길이를 알아야한다.

다음과 같이 28x28 픽셀 크기의 이미지가 6131장의 텐서인 것을 확인할 수 있다. (개수,높이,폭)
1
2
3
# shape의 길이를 구하면 랭크가 나온다(차원) (축의 개수를 뜻하기도 한다)
len(stacked_threes.shape)
>> 3
쌓아 올린 랭크3 텐서에서 0번째 차원의 평균을 구해서 모든 이미지 텐서의 평균을 얻을 수 있다.
- 0번째 차원은 이미지를 색인하는 차원이다.
즉, 이 계산은 각 픽셀 위치에 대한 모든 이미지의 평균을 구하고 평균 픽셀값으로 구성된 이미지 한 장을 만든다.
- 기준선으로 삼을 수 있다.
1
2
3
4
5
6
# 3이미지의 평균 픽셀 값
mean3=stacked_threes.mean(0)
show_image(mean3)
# 7이미지의 평균 픽셀 값
mean7=stacked_sevens.mean(0)
show_image(mean7)


이렇게 평균값을 가진 이미지를 구해놓고, 우리가 가지고 있는 이미지들중 하나를 골라 구분하도록 해본다.
그렇다면 어떻게 평균값을 가진 이미지와 무작위의 숫자 이미지 간의 유사성을 정의할 수 있을까?
- L1 노름 / 평균절대차 (mean absolute)
- 차이의 절댓값에 대한 평균을 구하는 방법
- L2 노름 / 평균제곱근오차 (root mean squared error)
- 차이의 제곱에 대한 평균의 제곱근 (차이를 제곱한 후, 평균을 구해서 루트를 씌운다)
** 양수와 음수가 있을 수 있다. 그러면 양수와 음수가 상쇄되어 그 의미를 잃어버린다.
1
2
3
4
5
6
7
8
9
10
11
12
#a_3는 '3' 이미지 리스트 중 무작위 이미지 1개
a_3=stacked_threes[15]
dist_3_abs=(a_3-mean3).abs().mean() #L1 평균절대차r
dist_3_sqr=((a_3-mean3)**2).mean().sqrt() #L2 평균제곱근오차
dist_3_abs,dist_3_sqr
>>> (tensor(0.1146), tensor(0.2075))
# 모델의 예측을 비교해보기 위해 위에서 가져온 무작위 '3'이미지를 사용
dist_7_abs=(a_3-mean7).abs().mean() #L1 평균절대차
dist_7_sqr=((a_3-mean7)**2).mean().sqrt() #L2 평균제곱근오차
dist_7_abs,dist_7_sqr
>>> (tensor(0.1336), tensor(0.2611))
| 같은 무작위의 ‘3’ 이미지를 구분하도록 설정 | ‘3’ 평균 픽셀 이미지와 비교 | ‘7’ 평균 픽셀 이미지와 비교 |
|---|---|---|
| L1 평균절대차 | 0.1146 | 0.1336 |
| L2 평균제곱근오차 | 0.2075 | 0.2611 |
숫자 ‘3’에 더 가깝도록 모델의 예측이 나왔다. 예측을 올바르게 수행하는 것 같다.
** PyTorch에는 이 2가지의 방법에 대한 손실 함수를 제공하기도 한다. 각 손실 함수는
torch.nn.fuctional 에서 찾을 수 있다.
1
2
3
# 손실함수 l1 (절대평균값), MSE (평균제곱오차)
F.l1_loss(a_3.float(),mean7),F.mse_loss(a_3,mean7).sqrt()
>>> (tensor(0.1336), tensor(0.2611))
위의 코드를 통해 2가지의 손실함수 (l1,mse)를 통해서 모델의 예측이 어느 정도 빗나갔는지 알 수 있다.
| 손실 함수 | 의미 | 특징 |
|---|---|---|
| L1 Loss(MAE) | 평균 절대 오차 | 이상치(outlier)에 덜 민감함 |
| RMSE(√MSE) | 평균 제곱 오차의 제곱근 | 이상치(outlier)에 더 민감함 |
평가지표 - 데이터셋에 표기된 올바른 레이블과 모델이 도출한 예측을 비교해서 모델이 얼마나 좋은지를 평가하는 단일 숫자
주로 평가지표는 정확도 (accuracy) 를 사용
평가지표는 검증용 데이터 (Validation set)을 사용해서 계산 → 과적합을 피하기 위해
검증용 데이터가 있는 디렉토리 ‘valid’에서 3과 7에 대한 평가지표를 계산하는데 사용할 텐서 생성
1
2
3
4
5
6
7
8
9
10
11
12
# 검증용 데이터로 3과 7에 대한 텐서를 만든다.
valid_3_tens=torch.stack([tensor(Image.open(o))
for o in (path/'valid'/'3').ls()])
valid_3_tens=valid_3_tens.float()/255
valid_7_tens=torch.stack([tensor(Image.open(o))
for o in (path/'valid'/'7').ls()])
valid_7_tens=valid_7_tens.float()/255
valid_3_tens.shape,valid_7_tens.shape
>>>. (torch.Size([1010, 28, 28]), torch.Size([1028, 28, 28]))
이렇게 각각 숫자 ‘3’에 대한 검증용 이미지, 숫자 ‘7’에 대한 검증용 이미지가 생성되었다.
우리가 임의의 입력한 이미지를 3 또는 7인지 판단하는 is_3 함수를 만들기 위해서는 두 이미지 사이의 거리를 계산해야한다.
1
2
3
4
5
# 평균절대오차를 계산하는 간단한 함수
def mnist_distance(a,b): return (a-b).abs().mean((-1,-2))
mnist_distance(a_3,mean3)
>>> tensor(0.1146)
이 코드는 많은 이미지 중 1개의 이미지에 대한 거리이고, 전체 이미지에 대한 평가지표를 계산하려면 검증용 데이터 내 모든 이미지와 이상적인 숫자 3 이미지의 거리를 계산해야하만 한다.
- 위에서 살펴본 vaid_3_tens의 shape은 (1010,28,28) 즉, 28x28 픽셀의 이미지가 1010개가 있다. 그렇다면 이 데이터에 반복 접근하여 한 번에 개별 이미지 텐서 하나씩 접근할 수 있다.
- 검증용 데이터셋을 mnist_distance 함수에 넣는다.
1
2
3
4
valid_3_dist=mnist_distance(valid_3_tens,mean3)
valid_3_dist,valid_3_dist.shape
>>> (tensor([0.1634, 0.1145, 0.1363, ..., 0.1105, 0.1111, 0.1640]),
torch.Size([1010]))
** mnist_distance 함수에 검증용 데이터셋을 넣어주면 길이가 1010이고, 모든 이미지에 대해 측정한 거리를 담은 벡터를 반환한다.
❓ 어떻게 가능할까 ❓
PyTorch를 통해 랭크(축의 개수)가 서로 다른 두 텐서 간의 뺄셈을 수행할 때 발생하는 ✅ 브로드캐스팅 때문
🔍 브로드캐스팅
- 더 낮은 랭크의 텐서를 더 높은 랭크의 텐서와 같은 크기로 자동 확장
- 서로 다른 두 텐서 간의 연산 (+ - / * ) 가능
mean 3 ⇒ 랭크 2 이미지 (28x28) 🛠
→ 복사본 이미지가 1010개가 있다고 취급하여 (1010x28x28) 을 만들어서 연산 진행
valid_3_tens → 랭크 3 이미지 (1010x28x28)
1
2
3
# 브로드캐스팅으로 서로 다른 랭크 사이의 연산
(valid_3_tens-mean3).shape
>>> torch.Size([1010, 28, 28])
📌 mnist_distance 함수를 통해 임의의 이미지와 이상적인 이미지 (3,7)사이의 거리를 계산하여 더 짧은 거리를 가진 이미지로 판단하는 로직에 활용하면 숫자를 구분할 수 있다.
1
2
3
4
5
def is_3(x): return mnist_distance(x,mean3) < mnist_distance(x,mean7)
is_3(a_3),is_3(a_3).float() # 이미지 3 구분
>>> (tensor(True), tensor(1.))
is_3(valid_7_tens) # 숫자 '7' 검증용 데이터셋을 주었을 때는 모두 False로 잘 구분
>>> tensor([False, False, False, ..., False, False, False])
✅ 정확도 (평가지표) 를 통해 모델 평가
1
2
3
4
accuracy_3s=is_3(valid_3_tens).float().mean()
accuracy_7s=is_7(valid_7_tens).float().mean()
accuracy_3s,accuracy_7s,(accuracy_3s+accuracy_7s)/2
>>> (tensor(0.9168), tensor(0.9854), tensor(0.9511))
4.4 확률적 경사 하강법
- 성능을 최대화하는 방향으로 할당된 가중치를 수정해나가는 매커니즘 → 컴퓨터가 경험으로부터 ‘학습’하며 프로그래밍되는 것을 지켜보기만 하면 된다.
- 위에서 만든 픽셀 유사도 방식은 이런 학습의 과정을 전혀 수행하지 않는다. 가중치 할당, 할당돈 가중치의 유효성 판단에 기반해 성능을 향상하는 방식을 제공하지 않는다.
💡 개별 픽셀마다 가중치를 설정하고 숫자를 표현하는 검은색 픽셀의 가중치를 높이는 방법
그레이디언트 (gradient) 계산
- 모델이 나아지려면 갱신해야할 가중치의 정도
그레이디언트 → y 변화량 / x 변화량
- 미분을 통해 값 자체를 계산하지 않고 값의 변화 정도를 계산할 수 있다.
- 함수가 변화하는 방식을 알면 무엇을 해야 변화가 작아지는지도 알 수 있다. (미분)
- 미분을 계산할 때도 하나가 아니라 모든 가중치에 대한 그레이디언트를 계산해야한다.
1
2
3
4
5
6
7
8
xt=tensor(3.).requires_grad_() # 3. 이라는 값을 가진 텐서를 생성 후, 미분가능상태로 설정
yt=f(xt) # 함수 f()에 xt를 전달, 보통 f()는 x**2임. 따라서 xt**2이 된다.
yt
>>> tensor(9., grad_fn=<PowBackward0>) # 3. -> 9. 이 된것을 통해 f()는 x**2임을 확인
yt.backward() # yt를 미분 (yt => xt**2) 미분값은 xt.grad에 저장된다.
xt.grad # 미분값 확인
>>> tensor(6.)
함수에 단일 숫자가 아닌 벡터를 입력해서 그레이디언트 값을 구해보았다.
1
2
3
4
5
6
7
8
arr=tensor([3.,4.,10.]).requires_grad_()
arry=f(arr)
arry
>>> tensor([ 9., 16., 100.], grad_fn=<PowBackward0>)
arry.backward()
arr.grad
>>> RuntimeError: grad can be implicitly created only for scalar outputs
1
2
3
4
5
6
7
8
def f(x): return (x**2).sum() # sum()을 통해서 벡터를 스칼라값으로 변환
arr=tensor([3.,4.,10.]).requires_grad_()
arry=f(arr)
arry
>>> tensor(125., grad_fn=<SumBackward0>)
arry.backward() # 미분하려는 스칼라값은 125이지만, 값들을 합친 스칼라값을 미분하기 때문에
arr.grad # 기울기는 각 원소별로 계산돠어 출력
>>> tensor([ 6., 8., 20.]) # 출력은 다시 벡터 형태로
- 그레이디언트는 함수의 기울기만 알려준다.
- 파라미터를 얼마나 조정해야 하는지는 알려주지 않는다.
- 경사가 매우 가파르면 조정을 더 많이, 경사가 덜 가파르면 최적의 값에 가깝다는 사실을 알 수 있다.
학습률
- 그레이디언트 (기울기)로 파라미터의 조절 방식을 결정
- 학습률 (Learning Rate)라는 작은 값을 기울기에 곱하는 가장 기본적인 아이디어에서 시작. 보통 0.1~0.001
학습률이 너무 커도 안되고 너무 작아도 안된다.
SGD를 활용해보기 (확률적 경사 하강법)
- 시간에 따른 속력의 변화 정도를 예측하는 모델
1
2
3
4
time=torch.arange(0,20).float()
time
>>> tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 9., 10., 11., 12., 13.,
14., 15., 16., 17., 18., 19.])
20초 동안 매초에 속력을 측정해서 다음의 형태를 띤 그래프를 얻었다고 가정
1
2
speed=torch.randn(20)*3 + 0.75*(time-9.5)**2+1
plt.scatter(time,speed)
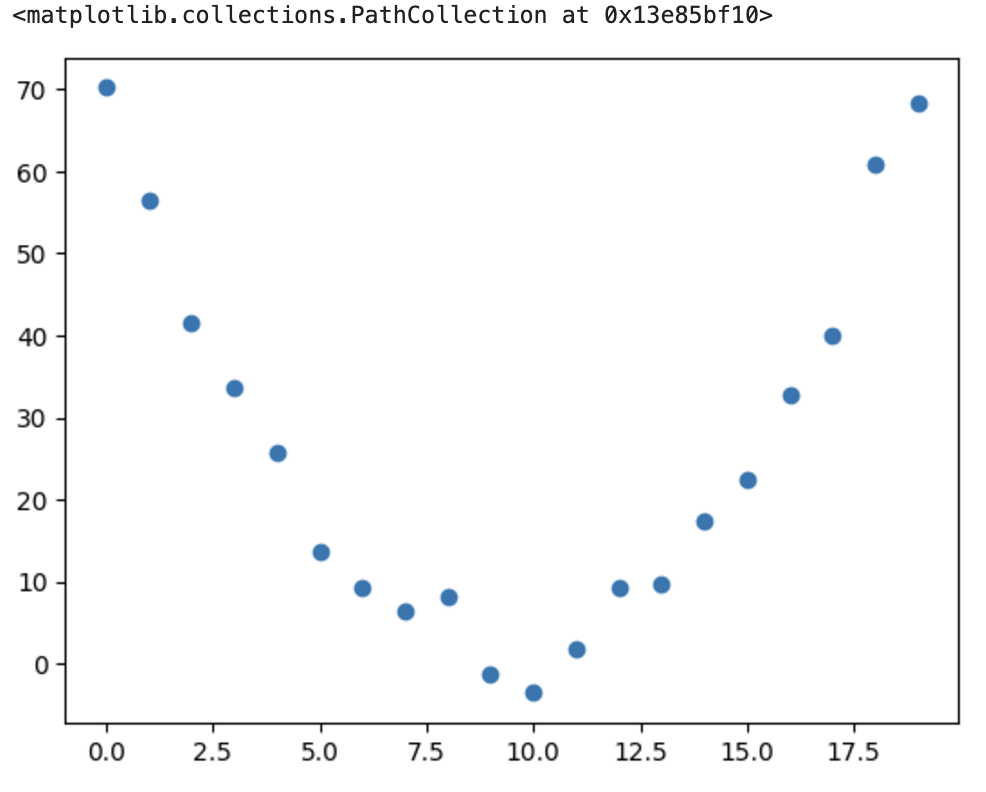
이러한 데이터에 가장 잘 맞는 함수 (모델)을 SGD를 통해서 찾아낼 수 있다.
함수의 입력 → t (속도를 측정한 시간)
파라미터 → 그 외의 모든 파라미터 params
1
2
3
def f(t,params):
a,b,c=params
return a*(t**2)+(b*t)+c
t 와 나머지 파라미터가 있는 함수를 다음과 같이 정의하면 a,b,c 만 찾는다면 데이터에 가장 적합한 2차 함수를 찾을 수 있다.
지금 현재 시간에 따른 속도 예측 모델이기 때문에 연속적인 값을 예측하는 문제에서의 손실함수인 평균제곱오차 함수를 손실함수로 사용
1
2
# 손실함수 정의
def mse(preds,targets): return ((preds-targets)**2).mean().sqrt()
1단계 : 파라미터 초기화
파라미터를 임의의 값으로 초기화하고 requires_grad_() 메서드를 통해 파이토치가 파라미터의 기울기를 추적하도록 설정
1
params=torch.randn(3).requires_grad_()
2단계 : 예측 계산
1
2
3
4
5
6
7
preds=f(time,params) #예측 함수에 입력값과 파라미터 전달하여 예측계산
def show_preds(preds, ax=None):
if ax is None : ax=plt.subplots()[1]
ax.scatter(time,speed)
ax.scatter(time,to_np(preds),color='red')#예측은 tensor일 가능성이 있기때문에 numpy로 변환
ax.set_ylim(-300,100)
show_preds(preds) # 예측과 실제 타깃의 유사도를 그래프로
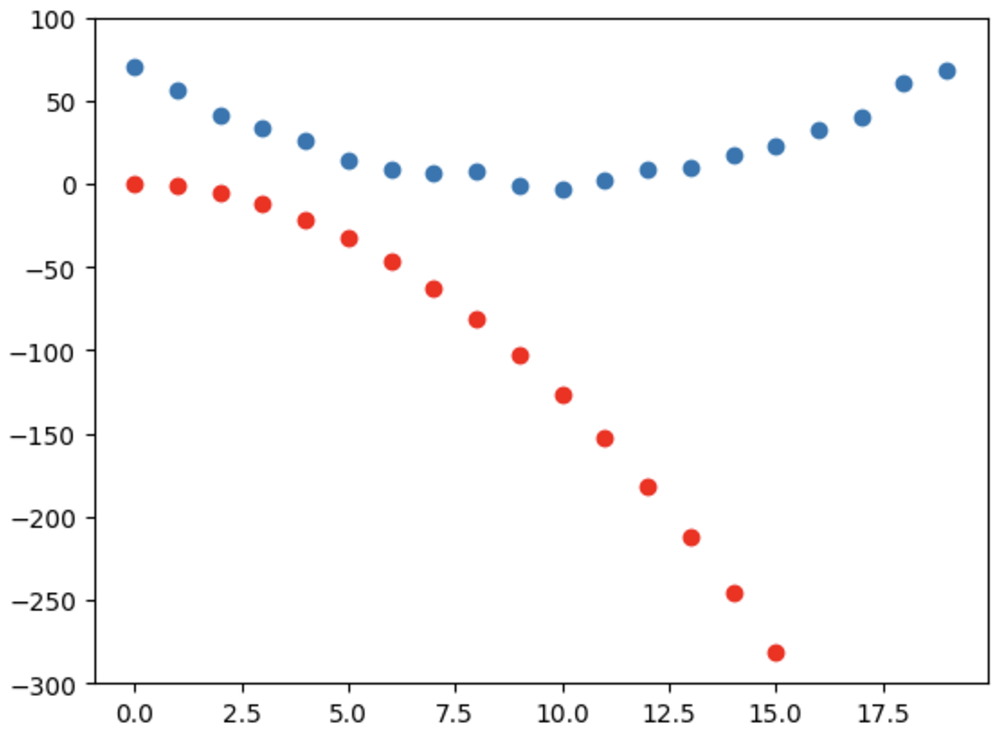
- 지금 그래프에서 빨간색 산점도가 예측, 파란색 산점도가 실제 타깃을 나타내고 있다.
- x축이 시간, y축이 속도이기 때문에, 지금 현재 임의의 파라미터를 부여한 함수의 예측 속도가 음수로 나오는 것을 확인할 수 있다.
3단계 : 손실 계산
- 손실을 앞서 설정해놓은 손실함수를 통해 계산해본다. (연속적인 값을 예측하는 회귀문제이기 때문에 MSE)
1
2
3
loss=mse(preds,speed)
loss
>>> tensor(178.7359, grad_fn=<SqrtBackward0>)
지금 현재 손실값은 187.7359이다. 이를 줄여서 성능을 높이는 것이 목표이다.
4단계 : 기울기 계산
- 파라미터값이 바뀌어야하는 정도를 추정하는 그레이디언트를 계산
1
2
3
4
5
loss.backward()
params.grad
>>> tensor([-165.9894, -10.6550, -0.7822])
params.grad * 1e-5
>>> tensor([-1.6599e-03, -1.0655e-04, -7.8224e-06])
학습률 : 1e-5
5단계 : 가중치를 한 단계 갱신하기
계산된 기울기에 기반하여 파라미터값을 갱신
1
2
3
4
5
6
7
lr = 1e-5 #학습률
params.data-=lr*params.grad.data
params.grad=None
preds=f(time,params)
mse(preds,speed)
show_preds(preds)
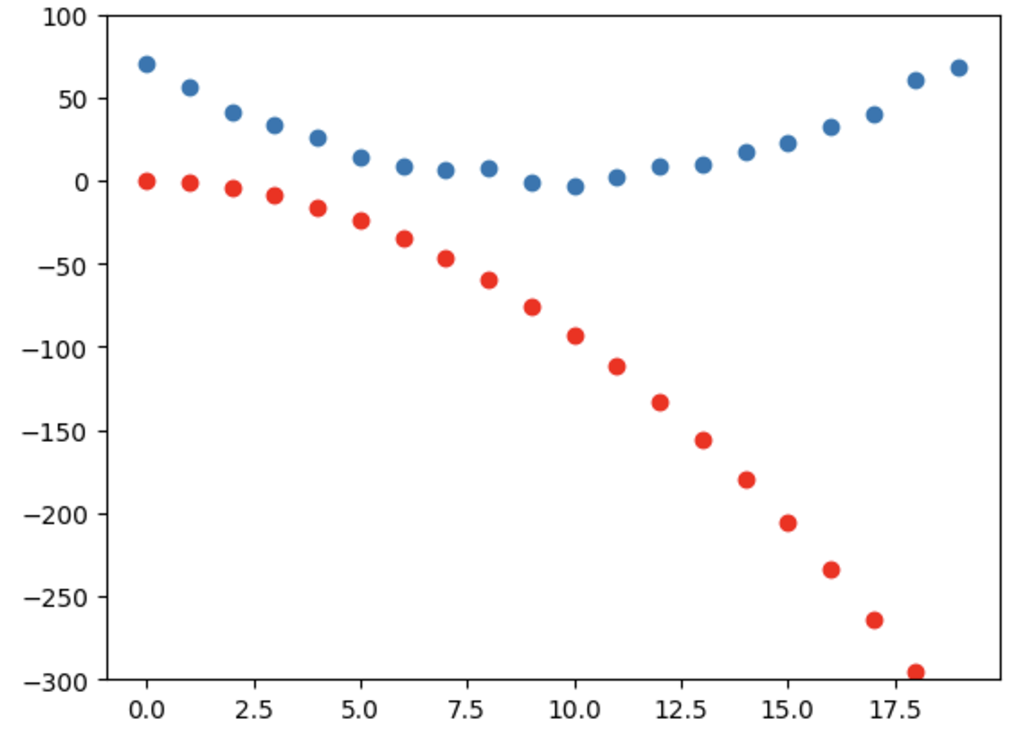
- 지금까지의 과정을 수차례 반복해야하므로 이 과정을 담을 수 있는 함수를 만든다.
1
2
3
4
5
6
7
8
def apply_step(params,prn=True):
preds=f(time,params)
loss=mse(preds,speed)
loss.backward()
params.data-=lr*params.grad.data
params.grad=None
if prn: print(loss.item())
return preds
6단계 : 과정 반복하기 (2~5단계)
1
2
3
4
5
6
7
8
9
10
11
for i in range(10): apply_step(params)
>>> 175.69366455078125
175.41722106933594
175.14077758789062
174.8643341064453
174.5879364013672
174.3115997314453
174.0352325439453
173.75888061523438
173.48255920410156
173.20626831054688
- 손실이 점점 낮아지긴 하지만 그 폭이 적다.
- 이 과정을 1번 더 진행했지만, 손실이 거의 그대로인 수준이었다.
1
2
3
4
5
6
7
params.grad * 1e-3
lr = 1e-3
params.data-=lr*params.grad.data
params.grad=None
preds=f(time,params)
mse(preds,speed)
>>> tensor(113.0670, grad_fn=<SqrtBackward0>)
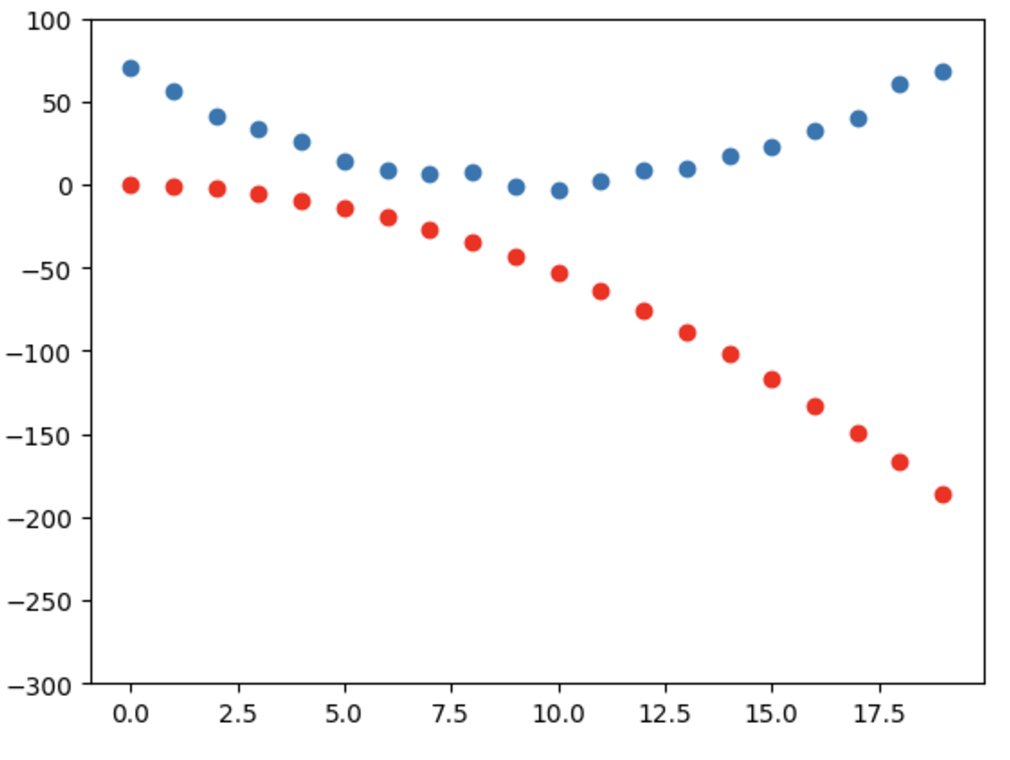
1
2
3
4
5
6
7
8
9
10
11
12
for i in range(10): apply_step(params)
>>> 113.06702423095703
86.50030517578125
61.265663146972656
39.4705810546875
27.055009841918945
25.680496215820312
25.677629470825195
25.677465438842773
25.677330017089844
25.67719268798828
- 이렇게 학습률을 조정하여 성능을 높일 수 있었다.
- 성능을 더 높이고 싶어서 학습률을 더 낮춰봤지만 데이터가 튀는 현상을 확인했다.
7단계 : 학습 종료
손실 : 약 25.7
✅ 경사 하강법 요약
- 시작 단계에서는 모델의 가중치를 임의의 값으로 설정(밑바닥부터 학습)하거나 사전에 학습된 모델로부터 설정(전이학습)할 수 있다.
- 손실함수로 모델의 출력과 목표 타깃값 비교 → 손실함수는 가중치를 개선해서 낮춰야만 하는 손실값을 반환
- 미분으로 기울기 계산, 학습률을 곱해서 한 번에 움직여야 하는 양을 알 수 있다.
- 목표 달성까지 반복
MNIST 손실함수
- 앞서 살펴본 MNIST (손글씨 이미지)를 가지고 똑같이 진행해보겠다.
- 이미지를 담은 독립변수 X는 모두 준비가 되어있다.
- 머신러닝/딥러닝 모델들은 주로 입력데이터로 벡터를 받는다. 우리가 가진 이미지는 (28x28) 행렬 형태로 존재하기 때문에 지금 위에서 살펴본 ‘3’과 ‘7’에 대한 이미지를 단일 텐서로 합친 후, 벡터의 목록으로 만들어주는 전처리 과정을 거친다. ( view() , cat() )
- 각 이미지에 레이블이 필요하기 때문에 숫자 ‘3’과 숫자 ‘7’에는 각각 1과 0을 사용한다.
1
2
3
4
5
6
7
8
# '3'과 '7'에 대한 이미지를 1개의 단일 텐서로 묶은 후 모델 입력 형태에 맞게 변환(벡터의 목록)
train_x=torch.cat([stacked_threes,stacked_sevens]).view(-1,28*28)
#각 이미지에 레이블이 필요하기 때문에 '3'에 대한 이미지를 1, '7'에 대한 이미지를 0으로 레이블 하기 위해
#각 이미지의 개수만큼 1과 0을 가진 텐서를 만든 후,
#unsqueeze(1)을 통해 형태를 맞춰줌 (벡터의 목록과 같은 형태)
train_y=tensor([1]*len(threes)+[0]*len(sevens)).unsqueeze(1)
train_x.shape,train_y.shape
>>> (torch.Size([12396, 784]), torch.Size([12396, 1]))
- PyTorch의 Dataset과 일치시키기 위해서 튜플을 생성
1
2
3
4
dset=list(zip(train_x,train_y))
x,y=dset[0]
x.shape,y
>>> (torch.Size([784]), tensor([1]))
- 지금 현재 각 튜플은 숫자에 관한 벡터 (784 크기)와 그게 맞는 레이블로 구성
- 검증용 데이터 또한 같은 전처리 과정 수행
1
2
3
4
# 검증용 데이터 전처리 과정
valid_x=torch.cat([valid_3_tens,valid_7_tens]).view(-1,28*28)
valid_y=tensor([1]*len(valid_3_tens)+[0]*len(valid_7_tens)).unsqueeze(1)
valid_dset=list(zip(valid_x,valid_y))
1 단계 : 초기화 단계
- 각 픽셀에 임의로 초기화된 가중치 부여
1
2
3
4
5
6
# 가중치 초기화 과정
# 각 픽셀마다 가중치를 부여할 것이기 때문에 각 이미지의 픽셀의 크기인 28*28로 가중치 개수를 설정하고
# 표준편차는 1.0으로 설정, 후에 모델을 학습할때에 기울기가 필요하기 때문에 미분 가능으로 설정해준다.
def init_params(size, std=1.0): return (torch.randn(size)*std).requires_grad_()
weights=init_params((28*28,1))
bias= init_params(1)
💡 왜 가중치는 각 픽셀마다 부여하지만, 편향 (bias)는 한개 일까?
- 모든 입력에 대해 동일한 편향을 부여하는 것이 더 효율적이며, 일반화가 더 잘된다.
만약 각 가중치에 대한 편향이 모두 다르다면, 모델의 파라미터 수가 엄청나게 증가하게 되고, 이는
과적합 (Overfitting)의 위험도 증가시킨다.
2단계 : 예측 계산
1
2
(train_x[0]*weights.T).sum()+bias
>>> tensor([4.5404], grad_fn=<AddBackward0>)
여기서 현재 weights는 (784,1)이고, train_x[0]은 784 크기이다. 그렇기 때문에 weights.T를 사용하여
전치를 해준다.
- 각 이미지의 예측 계산에 Python의 for 반복문을 사용할 수도 있지만 속도가 느리다.
- ‘행렬 곱셈’을 사용한다. @ 이라는 연산자를 사용해서 행렬곱셈을 수행한다. 즉 xb와 weights의 내적을 계산
1
2
3
4
5
6
7
8
9
10
def linear1(xb): return xb@weights+bias
preds=linear1(train_x)
preds
>>> tensor([[ 4.5404],
[10.7467],
[ 7.0952],
...,
[-7.0947],
[ 2.0583],
[ 8.8412]], grad_fn=<AddBackward0>)
- 지금 현재 예측이 숫자 3 또는 7 인지를 판단하는 것이기 때문에 출력값이 0.5보다 큰지를 검사해야한다.
1
2
3
4
5
6
7
8
9
10
11
12
corrects=(preds>0.5).float()==train_y
corrects
>>> tensor([[ True],
[ True],
[ True],
...,
[ True],
[False],
[False]])
corrects.float().mean().item()
>>> 0.5441271662712097
- 예측값이 0.5보다 크면 ‘3’으로 분류한것으로 검사를 해보면 지금 현재 정확도는 약 0.54 정도 되는 것을 확인할 수 있다.
- 가중치 하나를 약간 바꿔보고 정확도가 어떻게 바뀌는지 확인해보자.
1
2
3
4
5
weights = weights.clone() # 텐서 복사본을 만들어서 수정
weights[0] = weights[0] * 1.0001 # 수정
preds=linear1(train_x)
((preds>0.5).float()==train_y).float().mean().item()
>>> 0.5441271662712097
정확도에는 변함이 없다.
- SGD로 정확도를 향상 시키기 위해서는 기울기가 필요하다.
- 그리고 기울기 계산에는 현재의 모델의 성능을 알 수 있는 손실함수가 필요하다
해결방법
- 정확도 대신 약간 더 나은 예측을 도출한 가중치에 따라 약간 더 나은 손실을 계산하는 손실 함수가 필요
- ‘약간 더 나은 예측?’ → 올바른 정답이 3일 때 점수가 약간 더 높고, 7일때 점수가 약간 더 낮다는 의미
손실함수
- 이미지 자체가 아니라 모델의 예측을 입력받는다.
- prds라는 인자에 이미지가 3인지에 대한 예측으로 0~1사이의 값을 가지게 설정
- 0 또는 1의 값을 가지는 trgts라는 인자를 정의
예를 들어 실제 정답이 3,7,3인 이미지 3장에 대해 0.9의 신뢰도로 3이라고 예측, 0.4의 신뢰도로 7로 예측,
마지막으로 낮은 신뢰도 0.2로 예측에 실패했다고 가정하면 trgts 와 prds는 다음과 같이 설정할 수 있다.
1
2
3
ex)
trgts=tensor([1,0,1])
prds=tensor([0.9,0.4,0.2])
- 그리고 predictions 와 targets 사이의 거리를 측정하는 손실함수를 생성한다.
1
2
3
4
5
6
# 정답이 1일때 예측이 1과 떨어진 정도, 정답이 0일때 예측이 0과 떨어진 정도를 측정하고
# 이렇게 구한 모든 거리의 평균을 구한다.
# targets==1이 true면 1-predictions 반환
# false 면 predictions 반환
def mnist_loss(predictions, targets):
return torch.where(targets==1,1-predictions, predictions).mean()
- 위의 예시에 새로 만든 손실 함수를 적용해보았다.
1
2
3
4
5
6
7
8
torch.where(trgts==1,1-prds,prds)
>>> tensor([0.1000, 0.4000, 0.8000])
mnist_loss(prds,trgts)
>>> tensor(0.4333)
# '거짓' 타깃에 대한 예측을 0.2에서 0.8로 바꾸면 손실이 줄어들어
# 더 나은 예측을 나타낸다.
mnist_loss(tensor([0.9,0.4,0.8]),trgts)
>>> tensor(0.2333)
정답에 가까워질수록 손실이 줄어드는 것을 확인할 수 있었다.
→ 이렇게 문제를 해결할 수 있다.
| 📌 📌 📌 📌 📌 📌 | 정확도 기반 손실함수 | MNIST 손실함수 | | — | — | — | | 계산 방식 | 예측값이 0.5보다 큰지 여부만 확인 → 0.5보다 큰지 작은지 여부만 확인하기 때문에 0.5를 넘지 않는한, 기울기는 0이다. | 예측값과 실제값 사이의 거리 측정 (정답이 1이면 1과 떨어진 거리, 정답이 0이면 0과 떨어진 거리) → 이를 기반으로 손실을 계산하기 때문에 연속적인 기울기를 알 수 있다. | | 출력 범위 | 0 또는 1 (이진값) | 0~1 사이의 연속값 | | 기울기 특성 | 대부분의 경우 기울기가 0이 됨 | 연속적인 기울기 제공 | | 학습 효과 | 가중치 업데이트가 거의 발생하지 않음 | 점진적인 모델 개선 가능 | | 장단점 | 직관적이나 학습에 부적합 | 학습에 효과적이나 계산이 복잡 |
시그모이드
항상 0과 1사이의 숫자를 출력하는 시그모이드 ( sigmoid ) 함수 정의
1
2
3
#시그모이드 함수
def sigmoid(x): return 1/(1+torch.exp(-x))
plot_function(torch.sigmoid, title='Sigmoid', min=-4, max=4)
- 입력값은 음수부터 양수까지 제한이 없지만, 출력값은 0과 1 사이이다.
- SGD가 의미있는 기울기를 더 쉽게 찾도록 해준다.
- 입력된 값(예측값)을 시그모이드 함수에 적용
1
2
3
4
#시그모이드 함수가 적용되도록 갱신
def mnist_loss(predictions, targets):
predictions=predictions.sigmoid()
return torch.where(targets==1,1-predictions, predictions).mean()
미니배치
- 최적화 단계
- 적절한 손실 함수를 갖추었다면, 기울기에 기반하여 가중치를 갱신하는 과정
- 미니배치 → 전체 데이터 셋을 나누어 학습하여 메모리를 절약하고 과적합을 방지
- 한 번에 일정 개수의 데이터에 대한 손실의 평균 계산
- 미니 배치에 포함된 데이터 개수 → 배치 크기
- 배치 크기 ⬆️ , 기울기 정확성 ⬆️, 시간 ⬆️
- 적당한 크기로 나눈 모든 미니배치로 학습이 완료되면 에포크 +1
적당한 배치 크기 구하는 방법
- 일반적인 방법 : 매 에포크에 순차적으로 데이터셋을 소비하는 단순한 방식 대신 미니배치가 생성되기 전에 임의로 데이터셋을 뒤섞는 방식
1
2
3
4
5
6
coll=range(15) # 0~14의 숫자 (데이터셋이라고 생각)
dl=DataLoader(coll,batch_size=5,shuffle=True) # 위에서 만든 데이터셋으로 5개의 미니배치 생성
list(dl) # 배치 생성 전 무작위로 섞기 (shuffle)
>>> [tensor([ 3, 14, 2, 5, 7]),
tensor([13, 11, 10, 12, 4]),
tensor([8, 6, 0, 1, 9])]
전체적인 흐름 정리
1
2
3
4
5
for x,y in dl:
pred=model(x) # 모델의 예측값
loss=loss_func(pred,y) # 손실함수
loss.backward() # 기울기 (미분)
parameters-=parameters.grad*lr # 가중치 갱신
- 파라미터 초기화
1
2
weights=init_params((28*28,1))
bias=init_params(1)
- 미니배치 생성 (학습을 위한)
1
2
3
4
5
6
7
8
9
10
11
12
13
# 학습용 데이터
# [1,784]크기의 텐서 256개, 데이터 레이블 256개 왜? -> 배치 크기 = 256
dl=DataLoader(dset,batch_size=256)
xb,yb=first(dl)
xb.shape,yb.shape
>>> (torch.Size([256, 784]), torch.Size([256, 1]))
# 검증용 데이터
valid_dl=DataLoader(valid_dset,batch_size=256)
# 배치크기 : 4 (간단한 검사)
batch=train_x[:4]
batch.shape
>>> torch.Size([4, 784])
- 예측 계산
1
2
3
4
5
6
preds=linear1(batch)
preds
>>> tensor([[ 2.9989],
[ 5.3665],
[ 0.3126],
[-0.9745]], grad_fn=<AddBackward0>)
- 손실 계산
1
2
3
loss=mnist_loss(preds,train_y[:4])
loss
>> tensor(0.3002, grad_fn=<MeanBackward0>)
- 기울기 계산
1
2
3
4
5
loss.backward()
weights.grad.shape, weights.grad.mean(), bias.grad
>>> (torch.Size([784, 1]) # 픽셀 28*28 각각에 대한 가중치니까 [784,1]
tensor(-0.0193), # 가중치 기울기 평균값
tensor([-0.1232])) # 편향 기울기
5-1. 기울기 계산 (함수로 정의)
1
2
3
4
5
6
7
8
9
10
11
12
def calc_grad(xb,yb,model):
preds=model(xb)
loss=mnist_loss(preds,yb)
loss.backward()
calc_grad(batch,train_y[:4],linear1)
weights.grad.mean(),bias.grad
>>> (tensor(-0.0385), tensor([-0.2464]))
# 한번더 호출하면 기울기가 변한다. (loss.backward()는 앞서 계산된 기울기에 더하기 때문)
calc_grad(batch,train_y[:4],linear1)
weights.grad.mean(),bias.grad
>>> (tensor(-0.0578), tensor([-0.3696]))
1
2
3
# 파라미터의 기울기를 0으로 초기화 (기울기 누적 피하기)
weights.grad.zero_()
bias.grad.zero_();
1
2
3
4
5
6
7
# 매 에포크 마다 수행되는 학습 루프
def train_epoch(model,lr,params):
for xb,yb, in dl:
calc_grad(xb,yb,model)
for p in params:
p.data-=p.grad*lr # 기울기 업데이트 p.data = 파라미터 실제값
p.grad.zero_()
– 점검 —
학습용 데이터셋으로 정확도 확인
1
2
3
4
5
(preds>0.5).float()==train_y[:4]
>>> tensor([[ True],
[ True],
[False],
[False]])
- 정확도 확인
1
2
3
4
5
6
7
def batch_accuracy(xb,yb):
preds=xb.sigmoid()
correct=(preds>0.5)==yb
return correct.float().mean()
batch_accuracy(linear1(batch),train_y[:4])
>>> tensor(0.7500)
- 검증용 데이터셋의 모든 배치에 위의 함수를 적용하여 얻은 결과들의 평균을 구해보자
1
2
3
4
5
def validate_epoch(model):
accs=[batch_accuracy(model(xb),yb) for xb,yb in valid_dl]
return round(torch.stack(accs).mean().item(),4)
validate_epoch(linear1)
>>> 0.4606
→ 첫 정확도 : 0.4606
- 한 에포크 동안 모델을 학습시킨 다음 정확도가 개선되는지 확인
1
2
3
4
5
lr=1.
params=weights,bias
train_epoch(linear1,lr,params)
validate_epoch(linear1)
>>> 0.6331
- 개선되는 것을 확인할 수 있었고, 이제 에포크를 여러 번 반복해보겠다.
1
2
3
4
5
6
7
for i in range(20):
train_epoch(linear1,lr,params)
print(validate_epoch(linear1),end=' ')
>>> 0.7714 0.8851 0.9218 0.9383 0.9452 0.953 0.9564 0.9593
0.9618 0.9627 0.9622 0.9618 0.9618 0.9637 0.9657 0.9666
0.9666 0.9671 0.9681 0.9681
✅ 정확도가 계속해서 오르는 것을 확인할 수 있었다. → 모델이 개선되고 있다!
Optimizer 만들기
- Optimizer
- 위에서 진행한 SGD(확률적 경사하강법) 단계를 포장하여 객체로서 다룰 수 있도록하는 객체
- 위에서 만든 linear1 함수를 PyTorch의 nn.Linear 모듈로 대체
- init_params 파라미터 초기 설정과정 또한 같이 이루어진다.
- 위에서 진행한 SGD(확률적 경사하강법) 단계를 포장하여 객체로서 다룰 수 있도록하는 객체
1
2
3
4
linear_model=nn.Linear(28*28,1)
w,b=linear_model.parameters()
w.shape,b.shape
>>> (torch.Size([1, 784]), torch.Size([1]))
- 파라미터 정보는 옵티마이저를 정의하는 데 활용가능
1
2
3
4
5
6
7
8
class BasicOptim:
def __init__(self,params,lr): # 생성자
self.params=list(params)
self.lr=lr
def step(self,*args,**kwargs): # 가중치 갱신
for p in self.params: p.data -= p.grad.data * self.lr
def zero_grad(self,*args,**kwargs): # 기울기 0으로 초기화
for p in self.params : p.grad= None
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
opt=BasicOptim(linear_model.parameters(),lr)
def train_epoch(model): # 학습루프 간소화
for xb,yb in dl:
calc_grad(xb,yb,model)
opt.step()
opt.zero_grad()
def train_model(model,epochs): # train_model 함수 안에 학습 루프 및 정확도 출력
for i in range(epochs):
train_epoch(model)
print(validate_epoch(model),end=' ')
train_model(linear_model,20)
>>> 0.4932 0.8813 0.8149 0.9087 0.9316 0.9472 0.9555 0.9619 0.9658
0.9678 0.9697 0.9726 0.9736 0.9746 0.9761 0.9765 0.9775 0.978
0.9785 0.9785
- BasicOptim 클래스를 만들어 앞서 시도한 과정들을 간소화시킬 수 있다.
fastai 에서는 SGD클래스를 제공하고 앞서 만든 BasicOptim과 같은 방식으로 작동한다.
1
2
3
4
5
linear_model=nn.Linear(28*28,1)
opt=SGD(linear_model.parameters(),lr)
train_model(linear_model,20)
>>> 0.4932 0.8872 0.8183 0.9067 0.9331 0.9458 0.9541 0.9619 0.9653 0.9668
0.9697 0.9721 0.9736 0.9751 0.9756 0.9765 0.9775 0.978 0.9785 0.9785
fastai는 train_model 함수 대신 사용할 수 있는 Learner.fit 제공
DataLoaders 생성 → Learner 생성 → Learner.fit 사용가능
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
dl=DataLoaders(dl,valid_dl) # DataLoader 생성 (데이터를 배치단위로 나누어 공급)
#Learner-> 모델,데이터,손실함수,옵티마이저를 하나로 묶어 학습을 자동화
learn=Learner(dl,nn.Linear(28*28,1),opt_func=SGD, #Learner 생성
loss_func=mnist_loss,metrics=batch_accuracy)
learn.fit(10,10) # leaner.fit 사용
>>> epoch train_loss valid_loss batch_accuracy time
0 0.638337 0.504416 0.495584 00:00
1 0.633717 0.504416 0.495584 00:00
2 0.632580 0.504416 0.495584 00:00
3 0.632209 0.504416 0.495584 00:00
4 0.632077 0.504416 0.495584 00:00
5 0.632029 0.504416 0.495584 00:00
6 0.632011 0.504416 0.495584 00:00
7 0.632005 0.504416 0.495584 00:00
8 0.632002 0.504416 0.495584 00:00
9 0.632001 0.504416 0.495584 00:00
비선형성 추가
- 선형 분류 모델이 할 수 있는 일에는 한계가 존재한다.
- 복잡한 문제를 다루기 위해서는 분류 모델을 더 복잡하게 바꿔줘야한다.
- 두 선형 분류 모델 사이에 비선형을 추가 (은닉층)
- 은닉층이란? → 데이터 입력층과 출력층 사이에 존재하는 층, 데이터에 변환을 주어 비선형성 추가
- 비선형성을 추가하는 역할 → 활성화함수 (RELU, sigmoid 등등)
- 입력데이터를 변환하여 비선형성 추가
- 은닉층을 여러개 쌓으면 깊은 신경망이 된다.
1
2
3
4
5
def simple_net(xb):
res=xb@w1 + b1 #선형 모델 wx+b 형태
res=res.max(tensor(0.0)) # 은닉층 활성화 (RELU,sigmoid 등등) 활성화(여기선 RELU)
res=res@w2+b2 # 비선형성이 추가된 파라미터
return res
1
2
3
4
w1=init_params((28*28,30)) # 지금 각 픽셀마다 가중치를 부여하고, 은닉층으로 들어가는 입력이된다.
b1=init_params(30) # 784x30에 관한 편향 30개
w2=init_params((30,1)) # 30x1의 출력으로 이어진다.
b2=init_params(1) # 편향 1개
- 위의 코드는 파라미터 설정 코드이다.
- w1은 은닉층으로 들어가는 입력이라고 생각하자. 784*30 크기의 가중치 행렬이 생성된다.
- 여기서 30은 뉴런의 개수이며, 각각의 픽셀 하나당 30개의 가중치가 설정된다.
- 가중치가 30개이기 때문에 이에 맞는 편향 또한 30개가 된다.
다음 코드는 여러 계층을 표현한 코드이다. 첫 번째와 세 번째는 선형 계층, 두 번째는 비선형성 또는 활성화 함수이다.
1
2
3
4
5
simple_net=nn.Sequential(
nn.Linear(28*28,30), # 선형계층
nn.ReLU(), # 비선형성, 활성화함수
nn.Linear(30,1) # 선형계층
)
📌 nn.ReLU는 F.relu 함수와 정확히 같은 일을 한다. 보통 F를 nn으로 바꾸고 일부 문자를 대문자로 바꾸면
대응 모듈을 쉽게 찾을 수 있다.
1
2
3
learn=Learner(dl,simple_net,opt_func=SGD,loss_func=mnist_loss,
metrics=batch_accuracy)
learn.fit(40,0.1) # epoch:40, lr(학습률):0.1
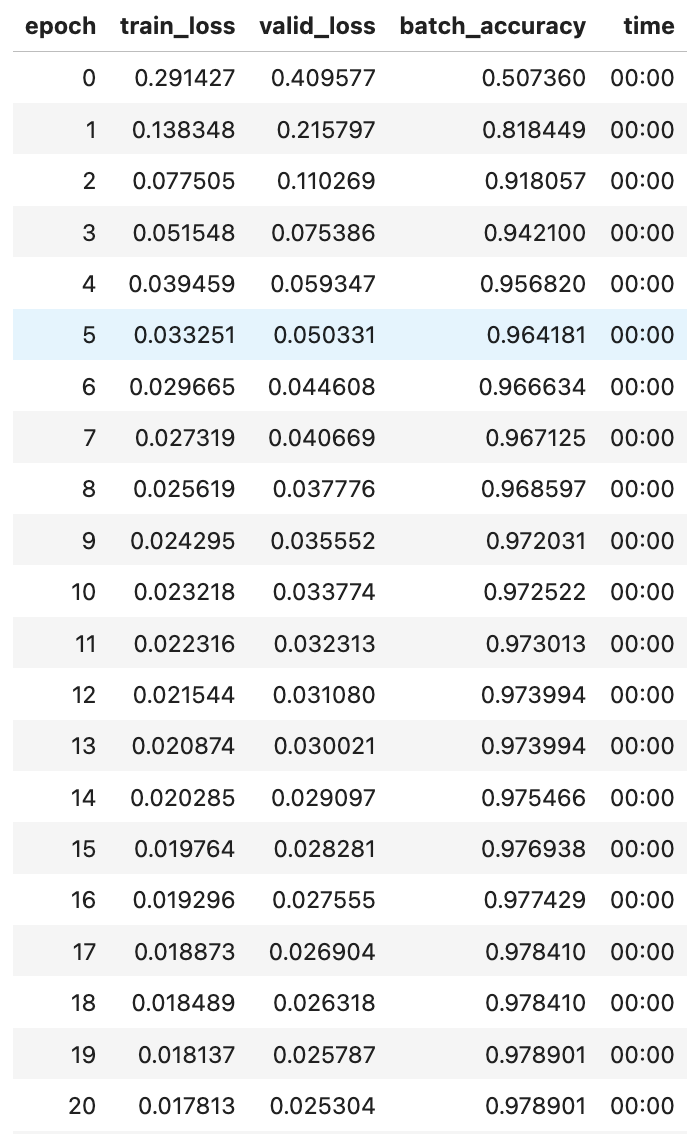
1
2
3
4
# 학습과정은 learn.recorder에 기록된다.
plt.plot(L(learn.recorder.values).itemgot(2)); # 그래프 출력
learn.recorder.values[-1][2] # 마지막에 기록된 정확도 출력
>>> 0.982826292514801
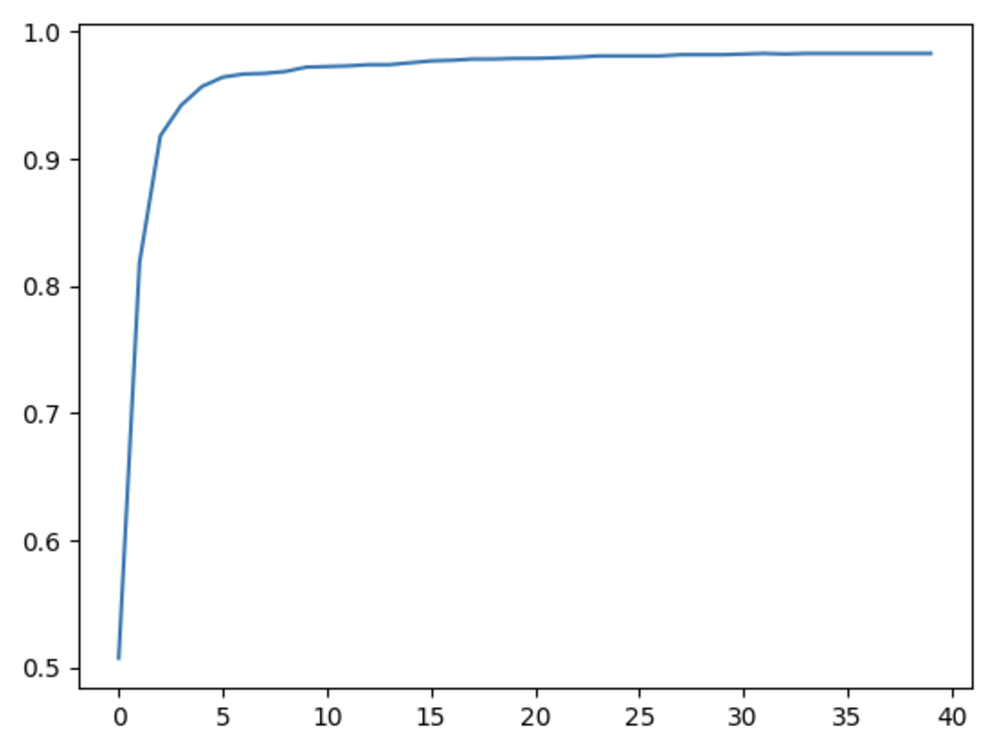
✅ 이 시점에서 얻은 결과
- 올바른 파라미터 집합이 주어지면 모든 문제를 원하는 정확도로 풀어낼 수 있는 함수 (신경망)
- 모든 함수에 대한 최적의 파라미터 집합을 찾아내는 방법 (SGD)
더 깊은 모델이 필요한 이유
- 성능
- 더 많은 계층이 있는 작은 행렬을 사용하면 적은 계층의 큰 행렬보다 더 좋은 결과를 얻을 수 있다.
18개 계층으로 구성된 모델을 학습시키는 코드
1
2
3
4
5
6
7
dls=ImageDataLoaders.from_folder(path)
learn=cnn_learner(dls,resnet18,pretrained=False,
loss_func=F.cross_entropy,metrics=accuracy)
learn.fit_one_cycle(1,0.1)
>>> epoch train_loss valid_loss accuracy time
0 0.137227 0.035000 0.995093 00:38
✅ 거의 100%에 가까운 정확도를 얻을 수 있었다.
- 앞서 만든 단순한 신경망 대비 큰 차이를 계층의 수를 늘리니 만들 수 있었다.
개념 / 흐름 정리
- 활성
- 선형 및 비선형 계층에서 계산된 수
- 파라미터
- 임의로 초기화되고 최적화된 수 (모델을 정의하는 수)
- 활성과 파라미터 모두 텐서로 저장된다.
- 텐서의 차원(축)의 개수 → 텐서의 랭크
- 랭크 0 : 스칼라
- 랭크 1 : 벡터
- 랭크 2 : 행렬
- 텐서의 차원(축)의 개수 → 텐서의 랭크
- 신경망 → 여러 계층으로 이루어진다. (선형 비선형 번갈아 사용)
- 선형 계층
- 비선형 계층 (비선형성을 활성화함수라고 표현하기도 한다.)
| 용어 | 의미 |
|---|---|
| ReLU | 양수의 입력은 그대로 출력, 음수의 입력은 0으로 반환 |
| 미니배치 | 입력과 타깃의 작은 그룹(데이터를 소분화한 것이라고 생각) |
| 경사하강 단계는 한 에포크 전체에 대해 수행되지 않고 미니배치 단위로 수행 | |
| 순전파 | 입력을 모델에 적용하여 예측을 수행하는 과정 |
| 손실 | 모델의 성능 표현 |
| 그레이디언트(기울기) | 모델의 일부 파라미터(가중치,편향)에 대한 손실을 미분한 값 |
| 역전파(BackPropagation) | 모델의 모든 파라미터에 대한 손실의 기울기를 계산하는 과정 |
| 경사하강 | {모델의 성능(파라미터 갱신)을 높이기/손실을 최소화 하기} 위해 기울기의 반대방향(기울기가 음수)으로 나아가는 단계 |
| 학습률 | SGD(확률적 경사하강)을 적용하여 모델의 파라미터가 갱신되어야 하는 크기 |
📌4장을 정리하며
- 확률적 경사하강법으로 파마리터(가중치)를 갱신해주며 모델의 개선
- (MNIST의 ‘3’과 ‘7’이미지를 구분하는 모델)
- 손실함수 선택 ( 정확도 기반 손실함수 vs MNIST 손실함수 )
- 단지 0.5를 넘냐 안넘냐를 기준으로 삼는것이 아니라, 예측값과 결과값의 거리를 계산
- 미니배치 → 데이터를 나누어 학습하여 효율적인 모델학습, 과적합 방지, 메모리 효율성
- 손실함수 선택 ( 정확도 기반 손실함수 vs MNIST 손실함수 )
- (MNIST의 ‘3’과 ‘7’이미지를 구분하는 모델)
- 만든 (경사하강법)단계의 Optimizer 생성
- 위에서 진행한 경사하강법 단계를 객체로 생성
- Learner.fit 사용해보기
- 복잡한 문제를 해결하기 위해 선형 모델에 비선형성 추가
- 은닉층 (활성화함수)
- 데이터 변환을 통해 비선형성 추가 (활성화함수 ex. ReLU, sigmoid ..)
- 은닉층을 여러개 쌓으면 신경망이 된다.
- 데이터 행렬이 작아도 층을 여러개 쌓으면 (깊은 모델) 성능이 더 좋다.
- 은닉층 (활성화함수)