LangChain & RAG [RAG Basic]
LangChain & RAG [RAG Basic]
RAG (Retrieval-Augmented Generation)
What is a RAG (Retrieval-Augmented Generation)?
- models → 많은 데이터를 통해 학습
- 하지만, private한 데이터엔 접근하지 못함 (개인 DB, Documents 등)
RAG → 우리가 질문을 하면, 2개의 event가 발생함
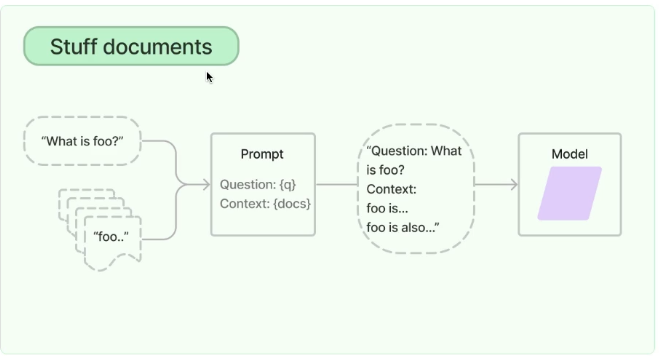
- 질문을 prompt에 전달 & 관련된 문서를 준비
- 하지만, 만약 모델이 질문에 대한 학습을 하지 않았다면 → 질문과 관련된 문서들을 탐색을 통해 가져옴 (질문의 내용 유무 or 의미론적인 비교를 통해)
- prompt (question , context (docs) )를 LLM에 보내게됨
→ Model은 기존에 학습한 방대한 데이터 + 사용자의 질문과 관련된 DATA 모두 갖게됨.
→ We can extend LLM
- 우리의 specific task를 specific data와 함께 prompt에서 합침
정리해보면,,,
- Pre-Trained된 모델이 specific task를 해결하기 위해 그것과 관련된 데이터를 prompt를 통해 부여해줌으로써, specific task를 해결할 수 있게 함
- 모델의 가중치(Weights)는 Freeze
- 검색 엔진(Retriever)이 증강된 데이터(외부 DB)(Augmentation)를 참고하여 답변을 Generate
- 프롬프트를 검색된 외부 Data로 augment
→ In-Context Learning
1 Data Loaders & Splitters
Retriever
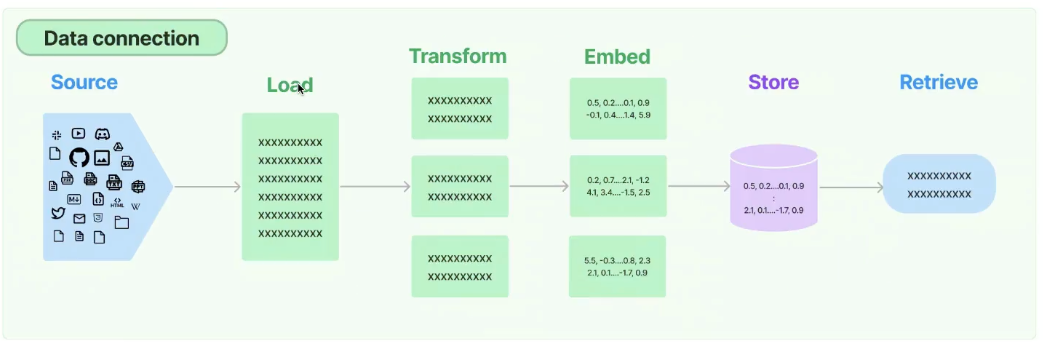
- Data Load → Transform(Split) → Embed → Store
Loader
- extract data from source and bring it to LangChain
- PowerPoint, Github, Figma ..
1
2
3
4
5
from langchain.document_loaders import UnstructuredFileLoader
from langchain.document_loaders import TextLoader
from langchain.document_loaders import PyPDFLoader
- UnstructredFileLoader → 다른 다양한 파일의 형식도 열 수 있음 (그것을 위해 필요한 패키지도 자동 download)
1
2
3
4
5
6
7
8
9
10
11
12
13
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import UnstructuredFileLoader
loader=UnstructuredFileLoader("../files/chapter_one.txt")
loader.load()
>>>[Document(page_content="Part 1, Chapter 1\n\nPart One\n\n1 It was a
bright cold day in April, and the clocks were striking thirteen.
Winston Smith, his chin nuzzled into his breast in an effort to
escape the vile wind, slipped quickly through the glass doors of
Victory Mansions, though not quickly enough to prevent a swirl of
gritty dust from entering along with him.\n\nThe hallway smelt of boiled
cabbage and old rag mats. At one end of ....
- 문서의 크기가 너무 크기 때문에, Split해야함
- 임베드하거나, Store, LLM에게 전달하려면, 문서의 일부분만 필요할 수 있음
Split
1
2
3
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter=RecursiveCharacterTextSplitter()
- RecursiveCharacterTextSplitter → 문장 끝이나 문단의 끝부분마다 끊어줌 (문장의 중간을 끊지 않음)
1
2
3
4
5
6
splitter=RecursiveCharacterTextSplitter()
loader=UnstructuredFileLoader("../files/chapter_one.txt")
docs=loader.load()
splitter.split_documents(docs) ##1
loader.load_and_split(text_splitter=splitter) ##2
- 이렇게 2가지 방식으로 활용가능
1
2
3
4
5
6
7
splitter=RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=True,
)
loader=UnstructuredFileLoader("../files/chapter_one.txt")
docs=loader.load()
loader.load_and_split(text_splitter=splitter)
- chunk_size : split할 chunk의 크기 (분해 덩어리 글자수)
- chunk_overlap : 이전 문단의 끝을 다음 문단의 시작에 조금 겹치게 생성
1
2
3
4
5
6
7
8
9
10
11
from langchain.text_splitter import CharacterTextSplitter
splitter=CharacterTextSplitter(
separator="\n",
chunk_size=600,
chunk_overlap=100,
length_function=len,
)
loader=UnstructuredFileLoader("../files/chapter_one.txt")
docs=loader.load()
loader.load_and_split(text_splitter=splitter)
- CharacterTextSplitter()
- separator = 특정 문자열을 찾은 다음, 그 문자열을 기준으로 split
- length_function=len (텍스트가 얼마나 많은 텍스트를 가지고 있는지)
Token
- 하나의 문자가 하나의 토큰을 의미하는 것은 아니다.
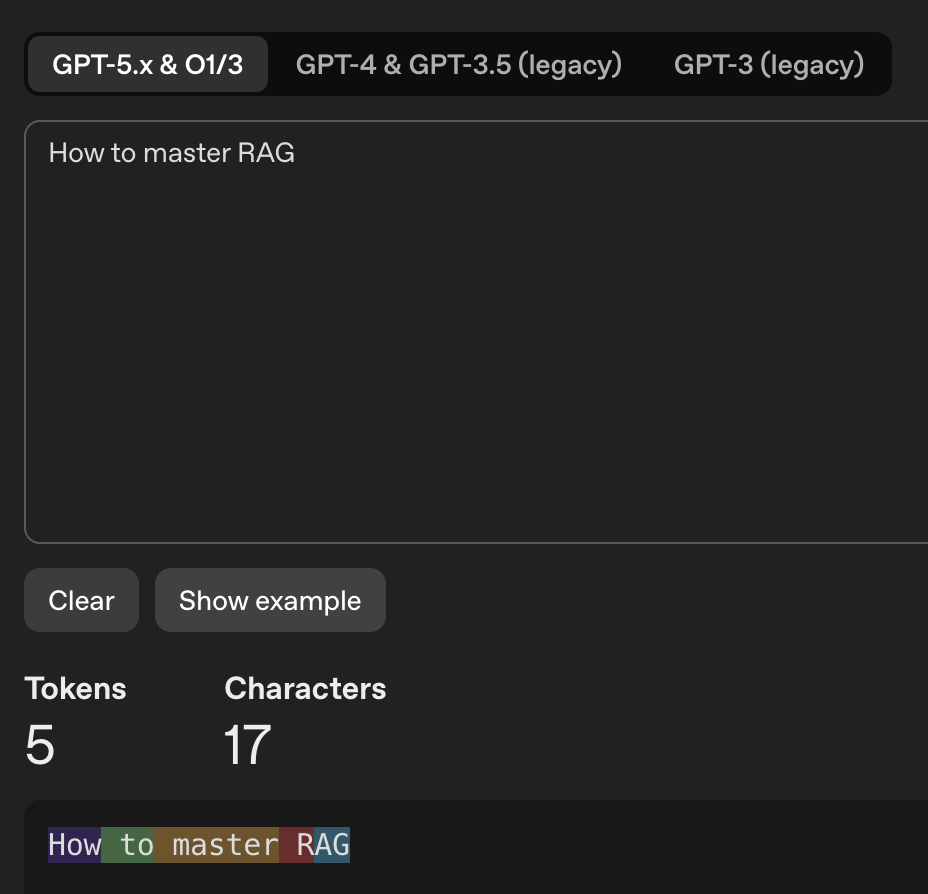
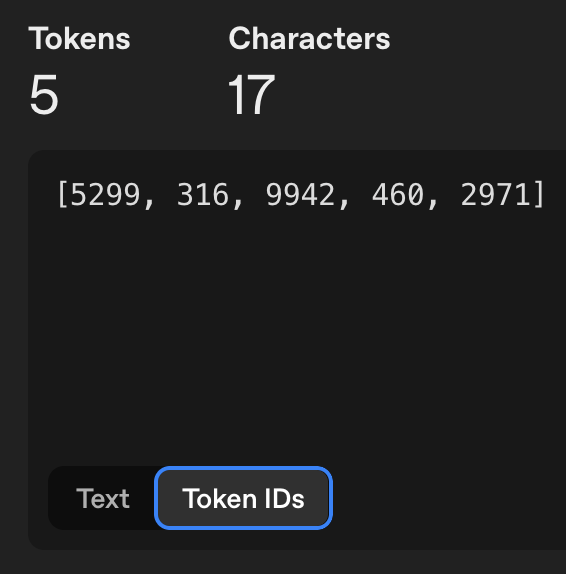
- 모델들은 token간의 통계적인 관계를 이해하도록 학습
1
2
3
4
5
splitter=CharacterTextSplitter.from_tiktoken_encoder(
separator="\n",
chunk_size=600,
chunk_overlap=100,
)
- 모델은 Limit이 있기 때문에, 텍스트의 길이를 계산할 때, model과 같은 방법으로 계산하는 것이 좋다. (As Token)
Embedding
- 사람이 읽는 텍스트를 컴퓨터가 이해할 수 있는 숫자로 변환
- 텍스트를 벡터로 변환
Vecorization
- 벡터로 변환하기 위해서는 차원을 먼저 정의해주어야한다.
- 각 단어가 해당 특성(차원을 구성하는)을 얼마나 반영하는지 평가
How could RAG use Embedding?
→ 텍스트들을 벡터로 변환하고, 벡터를 통해 비슷한 문서들을 검색할 수 있음
1
2
3
4
5
6
7
8
from langchain.embeddings import OpenAIEmbeddings
embedder=OpenAIEmbeddings()
vectorembedder.embed_query("hi")
len(vector)
>>>
1536
1
2
3
4
5
6
7
8
from langchain.embeddings import OpenAIEmbeddings
embedder=OpenAIEmbeddings()
vector=embedder.embed_documents(["hi","how","are","you"])
len(vector)
>>>
4
1
2
3
4
5
6
7
8
from langchain.embeddings import OpenAIEmbeddings
embedder=OpenAIEmbeddings()
vector=embedder.embed_documents(["hi","how","are","you"])
print(len(vector),len(vector[0]))
>>>
1536
- 실행할때마다 embedding을 생성하지 않고, 저장해뒀다가 사용한다.
VectorStore
→ 벡터로 변환한 문서를 저장해두는 곳. (Retriever가 질문과 관련된 정보들을 가져감)
Chroma/FAISS
Chroma
→ 분할된 (splitted) 문서와 OpenAI Embeddings Model을 전달
→ 숫자를 벡터로 변환하여 저장 (Vector Store)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from langchain.embeddings import OpenAIEmbeddings,CacheBackedEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import UnstructuredFileLoader
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.storage import LocalFileStore
cache_dir=LocalFileStore("../.cache/")
splitter=CharacterTextSplitter.from_tiktoken_encoder(
separator="\n",
chunk_size=600,
chunk_overlap=100,
)
loader=UnstructuredFileLoader("../files/chapter_one.txt")
docs=loader.load_and_split(text_splitter=splitter)
embeddings=OpenAIEmbeddings()
cached_embeddings=CacheBackedEmbeddings.from_bytes_store(
embeddings,cache_dir
)
vectorstore=Chroma.from_documents(docs,cached_embeddings)
- CharacterTextSplitter.from_tiktoken_encoder
- 모델과 동일하게 token을 기준으로 문서를 split
- UnstructuredFileLoader()
- 다양한 형태의 데이터를 로드
- OpenAIEmbeddings()
- OpenAI의 임베딩 모델 사용
- Chroma.from_documents(docs,embeddings)
- CacheBackedEmbeddings.from_bytes_store(embeddings, cache_dir)
- 임베딩한 벡터를 캐시에 저장해두었다가 활용
- 실행할때마다 임베딩을 생성할 필요 없음
LangSmith
LangSmith의 API Key를 통해 현재 진행 중인 프로젝트의 LangChain 진행 상황을 시각적으로 확인할 수 있음
LangSmith API Key를 env 파일에 저장
1
2
3
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT="[https://api.smith.langchain.com](https://api.smith.langchain.com/)"
LANGCHAIN_API_KEY="<사용자_API_KEY>"
RAG Chain의 종류 (off-the-shelf chain)
Stuff Chain
- 모든 문서를 한 번에 LLM에 입력하여 답변을 생성, 짧은 텍스트 요약에 적합하며, 성능이 빠르지만 너무 긴 문서를 처리할 수 없음
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
from langchain.embeddings import OpenAIEmbeddings,CacheBackedEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import UnstructuredFileLoader
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain.storage import LocalFileStore
from langchain.chains import RetrievalQA
llm=ChatOpenAI()
cache_dir=LocalFileStore("../.cache/")
splitter=CharacterTextSplitter.from_tiktoken_encoder(
separator="\n",
chunk_size=600,
chunk_overlap=100,
)
loader=UnstructuredFileLoader("../files/chapter_one.txt")
docs=loader.load_and_split(text_splitter=splitter)
embeddings=OpenAIEmbeddings()
cached_embeddings=CacheBackedEmbeddings.from_bytes_store(
embeddings,cache_dir
)
vectorstore=Chroma.from_documents(docs,cached_embeddings)
chain=RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff',
retriever=vectorstore.as_retriever(),
)
chain.run("Where does Winston live?")
>>>
'Winston lives in Victory Mansions on the seventh floor, which is a run-down apartment building.'
VectorStore에 저장된 Documents 속에서 정답을 찾아서 반환해줌
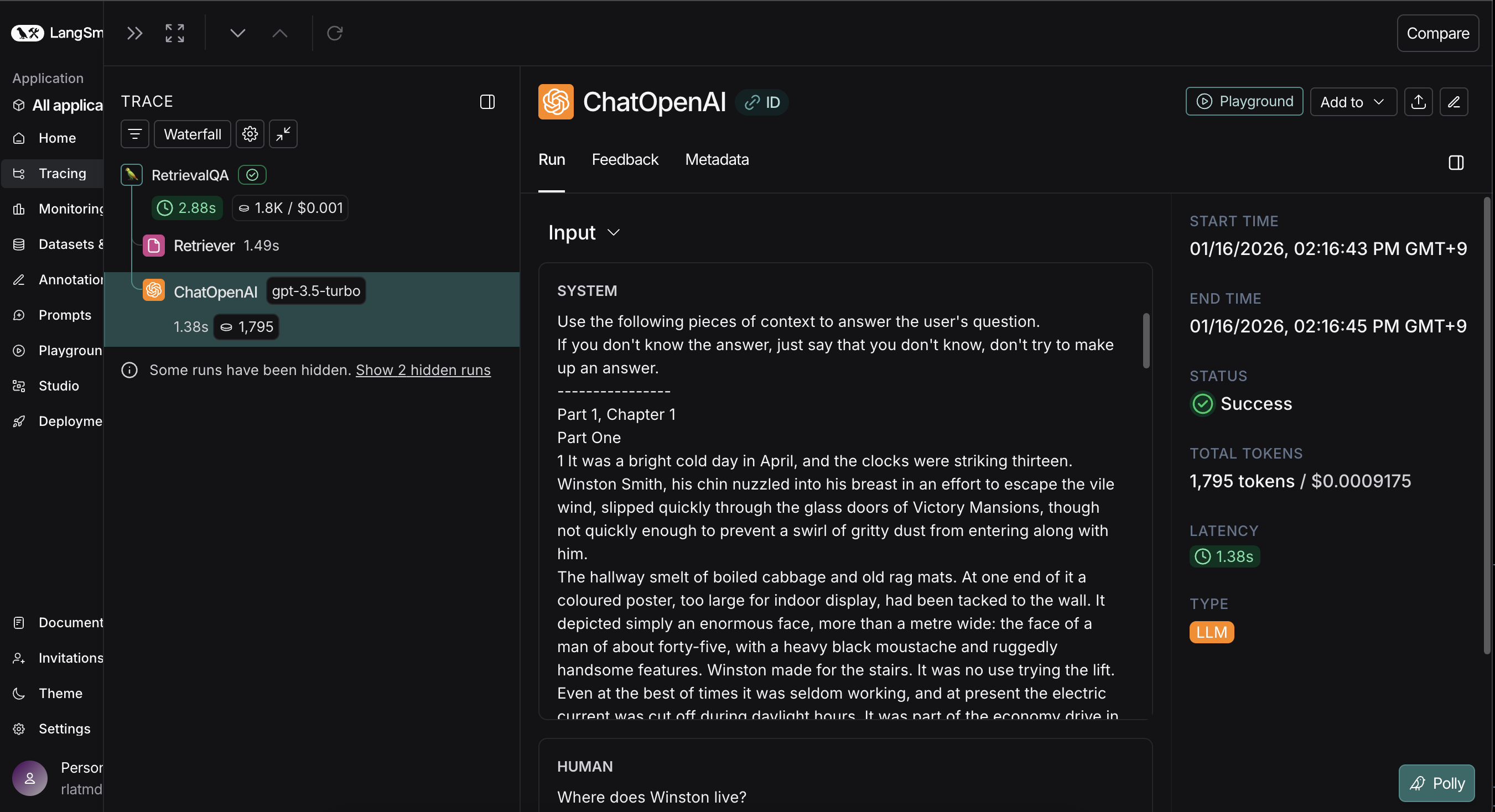
이전에 생성한 답변들은 LangSmith에서 찾아볼 수 있다.
What is a Retriever?
→ Document를 선별하여 가져올 수 있음 (Class의 interface)
- DB에서, Vector Store, Cloud 등등에서 가져올 수 있음
RetrievalQA
1
2
3
4
5
6
7
from langchain.chains import RetrievalQA
chain=RetrievalQA.from_chain_type(
llm=llm,
chain_type='stuff', ## refine, mapreduce 등
retriever=vectorstore.as_retriever(),
)
- RetirevalQA는 대표적인 off-the-shelf chain으로, LLm 모델과 chain_type, retriever만 부여해주면 RAG를 주어진 조건에 맞게 자동화
- chain_type을 쉽게 바꿀 수 있음
Refine Chain
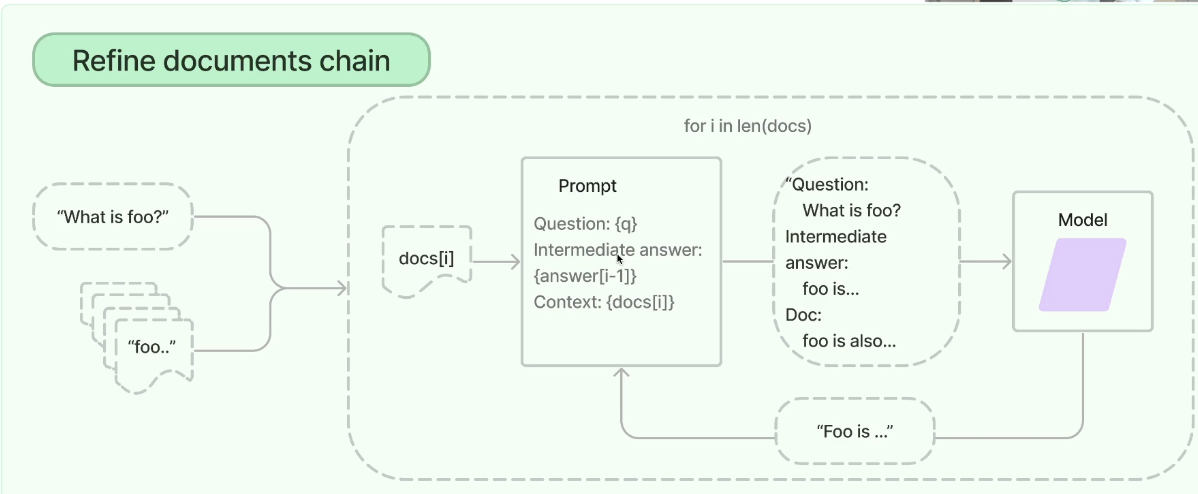
- 질문에 대한 문서를 얻고, Document를 읽으면서, 질문에 대한 답변 생성을 시도
- 문서를 하나하나씩 읽어가면서, 답변을 개선해나가는 과정을 거침
- 첫 번째 문서에서부터 질문과 관련된 문서들을 확인해나가면서 답변을 업데이트
- 문서들을 확인한다? → 문서 속 정보들을 수집한다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from langchain.embeddings import OpenAIEmbeddings,CacheBackedEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import UnstructuredFileLoader
from langchain.vectorstores import FAISS
from langchain.text_splitter import CharacterTextSplitter
from langchain.storage import LocalFileStore
from langchain.chains import RetrievalQA
llm=ChatOpenAI()
cache_dir=LocalFileStore("../.cache/")
splitter=CharacterTextSplitter.from_tiktoken_encoder(
separator="\n",
chunk_size=600,
chunk_overlap=100,
)
loader=UnstructuredFileLoader("../files/chapter_one.txt")
docs=loader.load_and_split(text_splitter=splitter)
embeddings=OpenAIEmbeddings()
cached_embeddings=CacheBackedEmbeddings.from_bytes_store(
embeddings,cache_dir
)
vectorstore=FAISS.from_documents(docs,cached_embeddings)
chain=RetrievalQA.from_chain_type(
llm=llm,
chain_type='refine',
retriever=vectorstore.as_retriever(),
)
chain.run("Where does Winston live?")
Map Reduce Chain
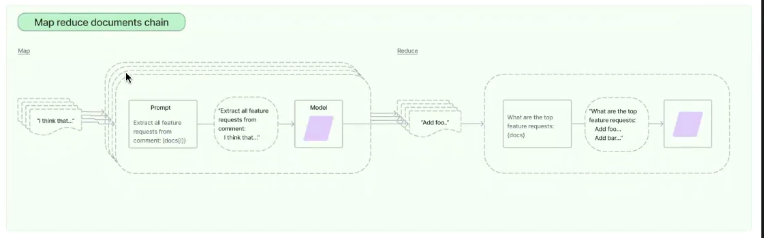
- Documents들을 입력으로받고, 각각의 Documents를 요약(Summarize)함
- 각각의 문서들의 요약본을 LLM에게 전달하게 됨
Map re-rank Chain
- 질문과 관련된 Documents를 찾고, 각 Documents를 기반으로 질문에 대한 답변을 생성
→ 이후 생성된 각 답변에 점수를 부여
- 최종적으로 가장 높은 점수를 획득한 답변과 그 점수를 반환
Recap
- How to load files?
- unstructuredloadfile() 을 통해 다양한 형식의 파일들을 load할 수 있음
- How can we split?
Why do we split Documents?
→ Document를 작게 분할하면, 작업이 쉬워지고 응답도 빨라지며, LLM 사용 비용 또한 저렴해짐
CharacterTextSplitter.from_tiktoken_encdoer()
- separator, chunk_size, chunk_overlap
- 모델이 텍스트를 보는 방식과 동일한 형식으로 문서를 split (token)
- Embeddings
- OpenAI Embedding Models를 활용하여 텍스트를 숫자로 벡터화
- caching을 통해 Embedding을 생성하는 방식을 저렴하게 사용
- CacheBackedEmbeddings.from_bytes_store
- Store (Vector Store)
- FAISS, Chroma (VectorStore 종류)
- FAISS.from_documents(docs, cached_embeddings)를 통해 캐싱해둔 벡터들을 공간상에 저장함 (유사도를 기반으로 정렬)
→ Retriever가 질문과 관련된 문서를 찾을 수 있도록
- Retriever
- RetrivalQA.from_chain_type()
- off-the-shelf chain으로, llm, chain_type, retriever만 지정해주면, RAG를 구현할 수 있음
- chain_type
- stuff, refine, map reduce, map re-rank
- RetrivalQA.from_chain_type()
This post is licensed under CC BY 4.0 by the author.