PR [YOLO (You Only Look Once)]
YOLO “A COMPREHENSIVE REVIEW OF YOLO ARCHITECTURES IN
COMPUTER VISION: FROM YOLOV1 TO YOLOV8 AND YOLO-NAS” 논문 리뷰
YOLO에 대한 전반적인 이해를 하기 위해 “A COMPREHENSIVE REVIEW OF YOLO ARCHITECTURES IN COMPUTER VISION: FROM YOLOV1 TO YOLOV8 AND YOLO-NAS” 이라는 논문을 읽어보았으며, 내가 이해한 내용들을 간단하게 정리해보았다.
📘 “A COMPREHENSIVE REVIEW OF YOLO ARCHITECTURES IN COMPUTER VISION: FROM YOLOV1 TO YOLOV8 AND YOLO-NAS” 2024
- YOLO는 객체 탐지 분야에서 큰 변화를 가져온 모델로서, 처음으로 객체 탐지를 실시간으로 처리 가능하게 만든 모델이다. 한 번의 네트워크 추론으로 객체의 위치와 클래스를 동시에 예측하는 구조를 사용함으로서, 복잡했던 two-stage 방식보다 훨씬 빠르고, 실용적이며, 모바일까지 확장 가능하다.
YOLO는 YOLOv1 부터 YOLOv8까지 여러 세대를 거쳐 발전해왔으며, 각 버전마다 기존의 한계를 보완하고 성능을 향상시켜왔다.
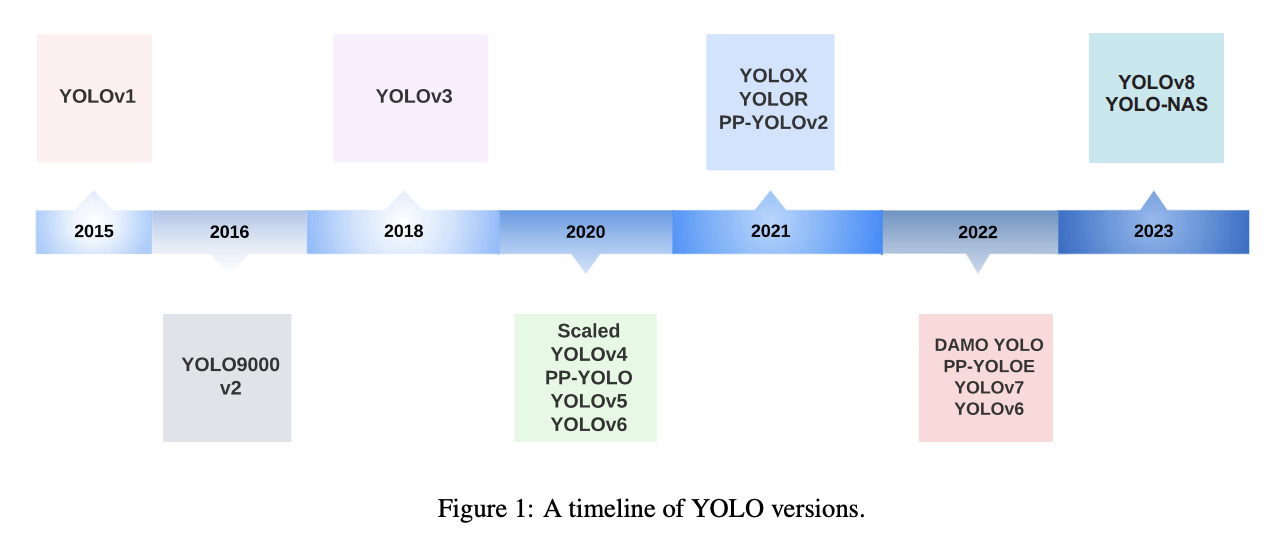
- YOLO의 프레임 워크는 높은 속도와 정확도의 균형을 가지고 있다.
- YOLO이외의 다양한 객체 탐지 기법
- R-CNN 계열
- SSD (Single Shot MultiBox Detector)
- Mask R-CNN
- RetinaNet, EfficientDet
YOLO Applications Across Diverse Fields
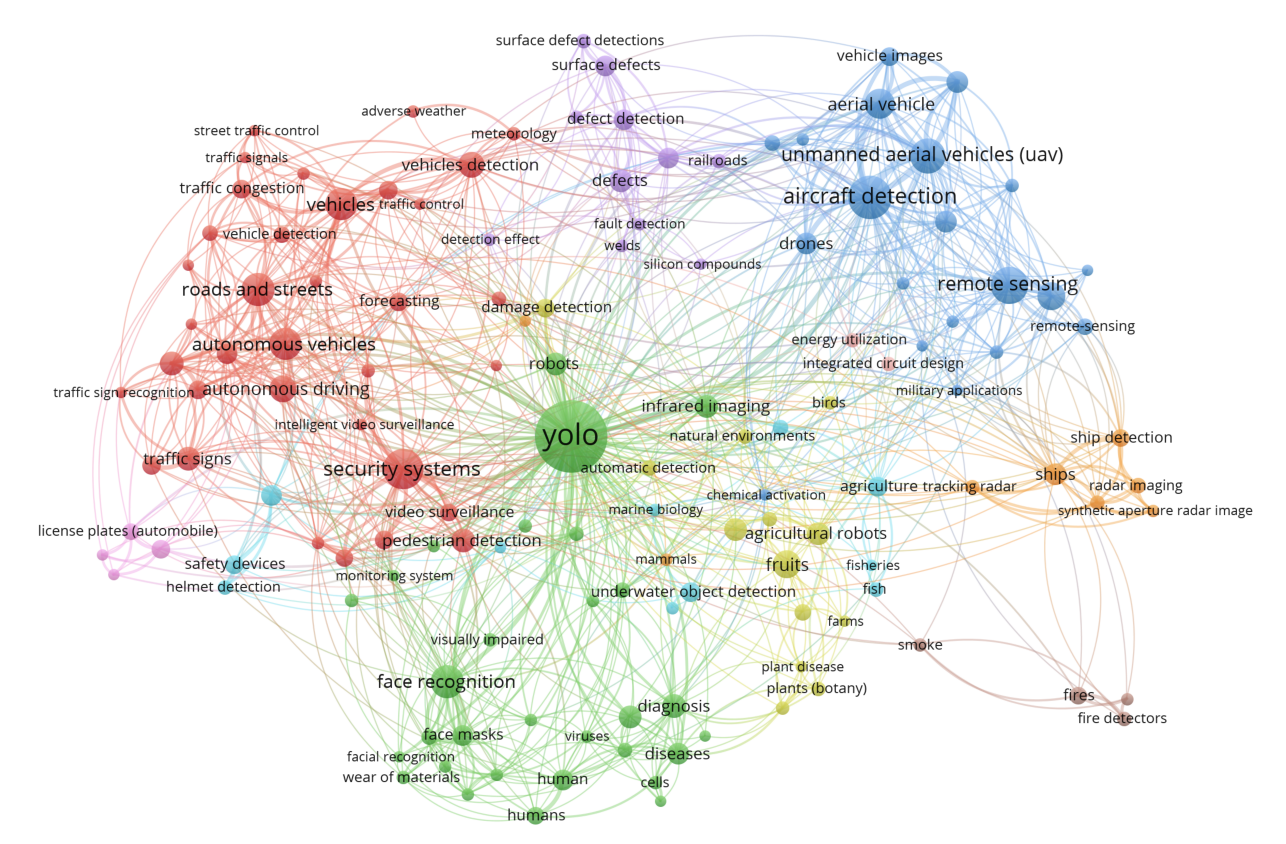
- 자율.주행
- 차량, 보행자, 자전거, 장애물 등을 탐지
- 빠른 반응을 요하는 운전 상황에서 실시간 인식 시스템에 사용된다.
- 영상 기반 행동 인식 및 감시
- 행동 인식, 스포츠 분석, 사람-컴퓨터 상호작용(HCI) 등에 활용
- 감시 카메라 영상에서 특정 행위나 동작 감지 가능
- 농업 분야
- 작물, 병해충 탐지 및 분류
- 정밀 농업을 위한 자동화된 수확/관리 시스템에 도움
- 안면 인식 및 생체인식
- 얼굴 탐지, 인증 시스템, 마스크 착용 여부 감지 등
- 원격 탐사
- 위성/항공 이미지 내 객체 탐지
- 토지 이용, 도시 계획, 환경 모니터링에 활용
위와 같은 분야이외에도 다양한 분야에서 YOLO 모델이 활용된다.
Object Detection Metrics and Non-Maximum Suppresion (NMS)
객체 탐지 평가 지표와 NMS
- AP (Average Precision) / mAP
- 모델이 예측한 박스들이 얼마나 정확한지 평가하는 정밀도 - 재현율(Precision-Recall) 기반 지표
- mAP = 각 클래스의 AP 평균값
- AP50 : IoU 0.5 이상에서만 계산한 AP
IoU (Intersection over Union) 이란?
⇒ 객체 탐지에서 예측한 바운딩 박스가 얼마나 정확하게 정답과 겹치는지 수치로 표현
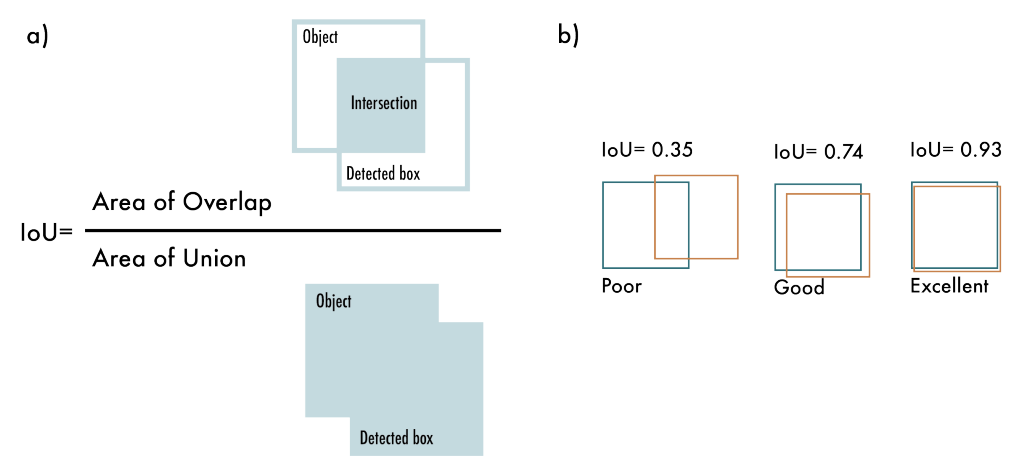
- AP 계산 방식 비교
| 항목 | VOC 방식 | COCO 방식 |
|---|---|---|
| 클래스 수 | 20개 | 80개 |
| IoU 기준 | 0.5만 사용 (AP50) | 0.5~0.95 |
| 샘플 방식 | 11-point | 101-point |
| 평가 정밀도 | 낮음 | 높음 (세밀한 구간 평가) |
⇒ 현재는 COCO 방식을 표준으로 사용
- NMS (Non-Maximum Suppression)
- 탐지 모델은 하나의 객체에 대해 여러 박스 예측 → 겹침 발생
- NMS는 신뢰도가 가장 높은 박스를 남기고, IoU가 높은 나머지 박스는 제거
- 📘 NMS 알고리즘 요약
- 신뢰도 임계값 이상인 박스만 선택
- 신뢰도 순으로 정렬
- 가장 높은 박스를 최종 박스에 추가
- 그 박스와 IoU ≥ τ 인 박스는 제거
- 반복


YOLO : You Only Look Once
YOLOv1 (You Only Look Once, 2015)
⇒ 한 번의 CNN 추론만으로 객체를 탐지한다는 의미
⇒ 기존의 방식 (Faster R-CNN 등)은 2단계 탐지였지만, YOLO는 단일 회귀 기반으로 전체 이미지에서 객체를 동시에 예측
작동 방식
- 그리드 분할
- 입력 이미지를 S x S 그리드로 나눈다. 기본 : 7 x 7
- 각 그리드 셀마다 B개의 바운딩 박스 기본 : 2개
- 각 박스
- 신뢰도, 중심좌표, 폭과 높이
- 클래스 확률 C개 (논문에서의 VOC : 20개 클래스)
- 출력 텐서
- shape = S x S x (B x 5 + C)
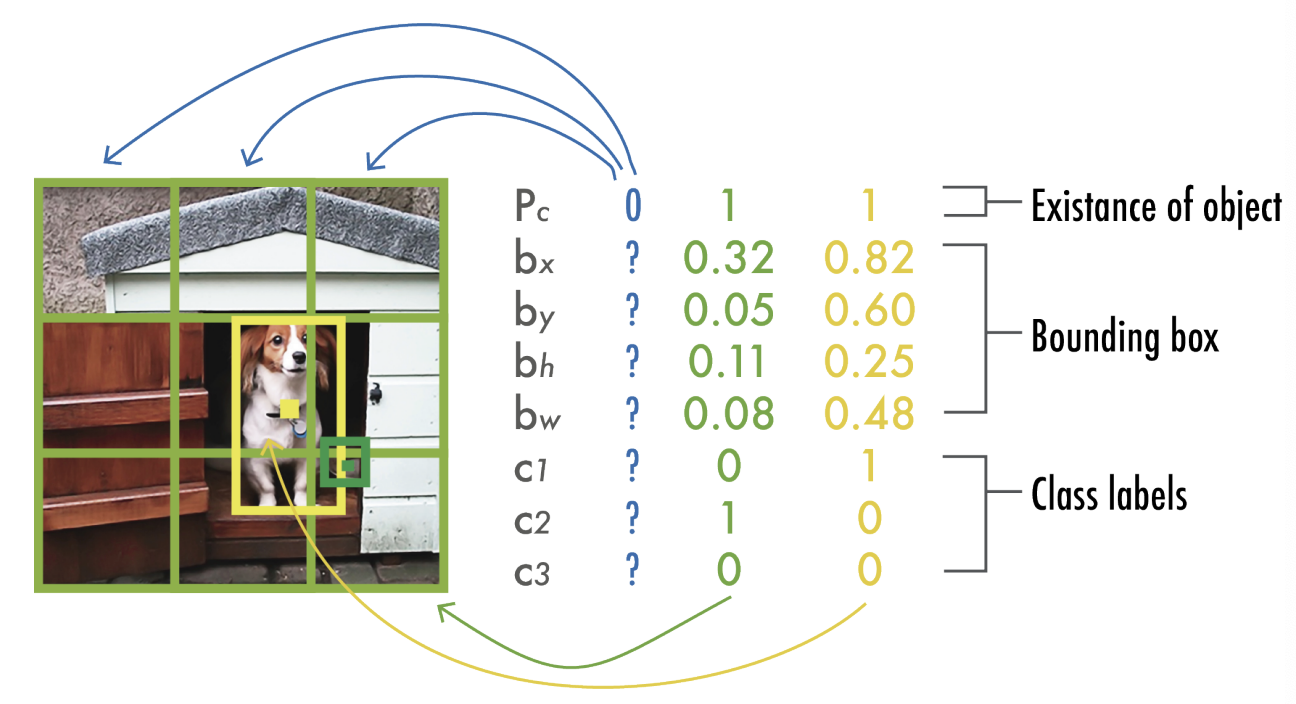
아키텍쳐
Layer 구성 Conv 총 24개 FC 2개 Activation Leaky ReLU, 마지막엔 Linear Fast YOLO : 경량화 버전으로 Conv 9개 사용
학습 방식
사전학습 ImageNet (224x224) 파인튜닝 VOC 2007/2012 (448x448) 데이터 증강 랜덤 크기 변환, HSV 색상 변경 손실 함수 구성
- 위치 오차 ( x , y , w , h )
- 객체 존재 유무에 따른 confidence 오차
- 클래스 예측 오차 (CrossEntropy 아님, MSE 기반)
YOLOv1의 장점
장점 설명 속도 빠름 한 번의 forward pass로 실시간 가능 단순 구조 end-to-end 학습, 분할 없음 경량화 가능 Fast YOLO로 모바일 가능성
YOLOv2 (2017, YOLO9000)
- 정확도 향상 + 다양한 객체 인식
[주요 개선점]
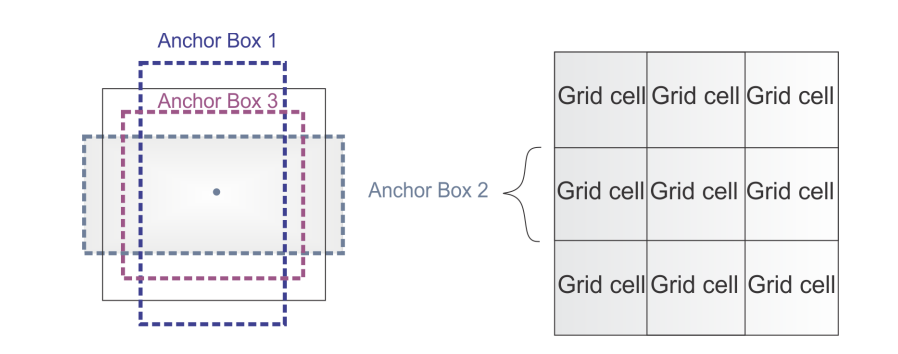
- Anchor Box 도입 → Faster R-CNN 에서 차용하여 위치 예측 개선
Batch Normalization
→ 학습 안정화, 과적합 방지 (모든 Conv layer에 적용)
High-resolution classifier
→ 448x448로 fine-tuning
- Fully Convolutional Network → FC 제거 → 다양한 해상도 입력 가능
Dimension Clustering
→ k-means로 anchor box의 크기 자동 설정 (5개 anchor 사용)
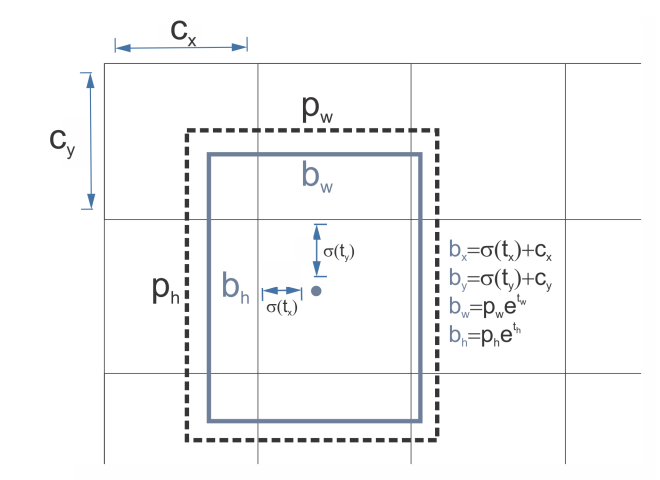
Direct Location Prediction
→ bounding box 좌표는 grid cell 기준 상대 좌표로 예측
Finer-Grained Features + Passthrough Layer
→ 고해상도 feature map (26x26)을 저해상도 feature map 과 채널 차원으로 결합
Multi-Scale Training
→ 학습 중 입력 해상도를 10배치마다 랜덤 변경 (320~608)
YOLOv3 (2018)
[주요 개선점]
Bounding Box Prediction 방식 변경
→ tx, ty, tw, th + objectness score → logistic regression으로 예측
가장 높은 IoU를 가지는 anchor만 positive로 지정
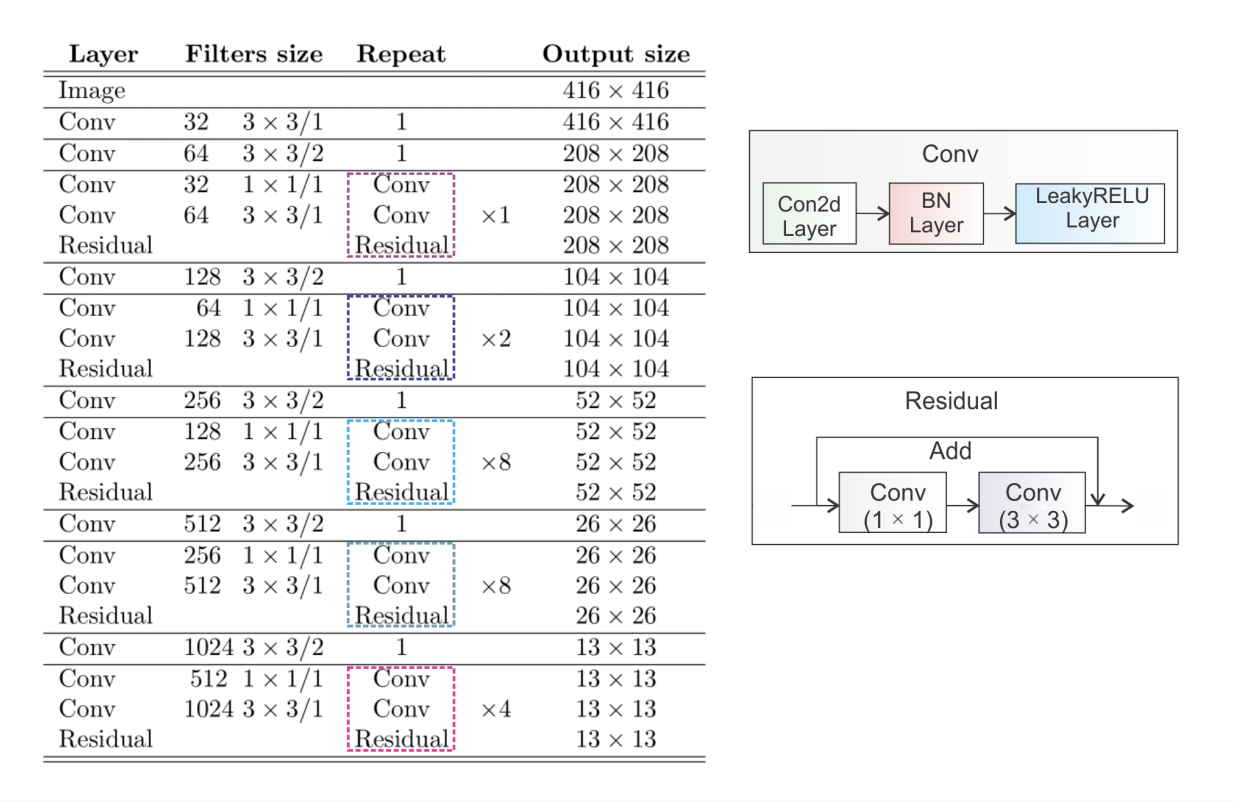
새로운 백본 : Darknet - 53
→ 53개의 convolution layer + residual connections
Max Pooling 제거 → stride=2 convolution 적용
→ ResNet-152급 정확도, 연산속도 2배 빠름
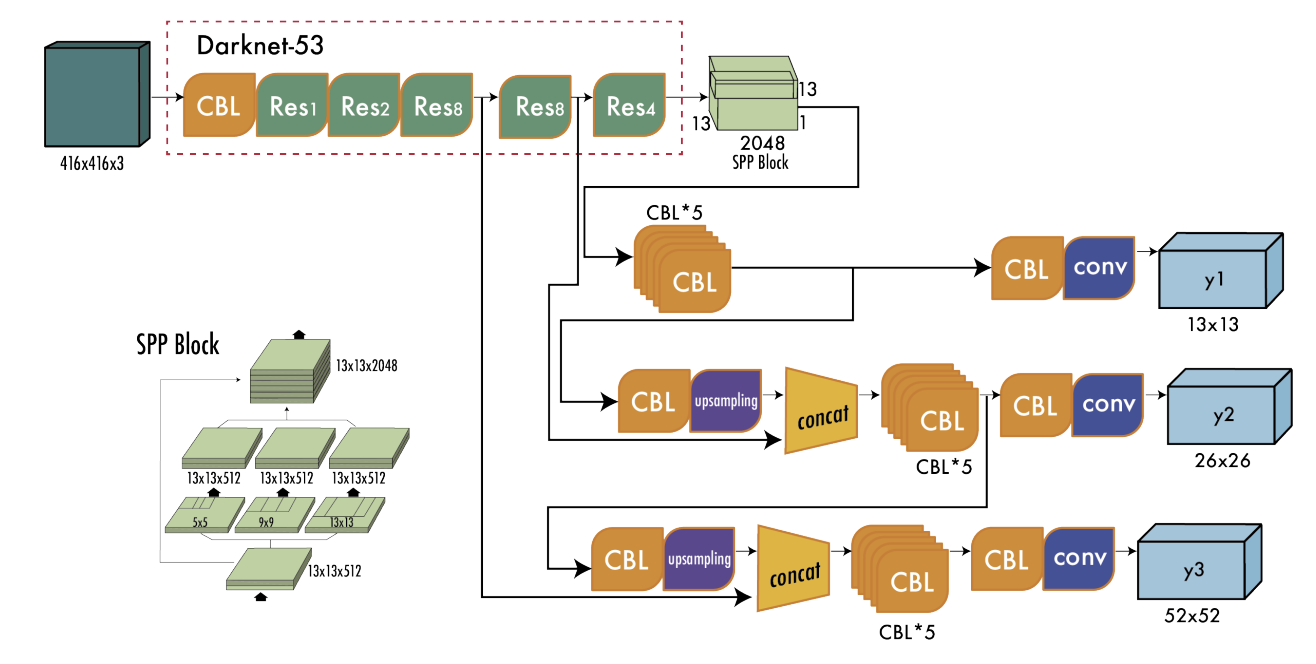
Multi-scale Prediction (3개 해상도)
13 x 13 (large object)
26 x 26 (medium object)
52 x 52 (small object)
→ 작은 객체 탐지 능력 대폭 향상
Feature Pyramid Netword (FPN) 과 유사한 구조
Anchor Box 개수 변화
→ 5개에서 9개 (3x3 스케일) 로 증가
Spatial Pyramid Pooling (YOLOv3 - SPP)
더 넓은 receptive field 확보 → AP50 약 2.7% 향상
YOLOv4 (2020)
[주요 개선점]
- 구조적 개선
| 구성 | YOLOv4에서의 주요 구성 요소 |
|---|---|
| Backbone | CSPDarknet53 + Mish activation |
| Neck | SPP(확장된 수용 영역) + PANet(FPN보다 효율적) + SAM(Spatial Attention Module) |
| Head | YOLOv3 방식 유지 |
⇒ 전체 구조 : CSPDarknet53 + PANet + SPP
CSPNet : 연산량 감소하면서도 성능 유지
SPP : 다양한 크기의 커널로 특성 추출 범위 확대 (stride = 1)
PANet : feature map을 concatenate(사슬 같이 이어)하여 효과적인 정보 전달
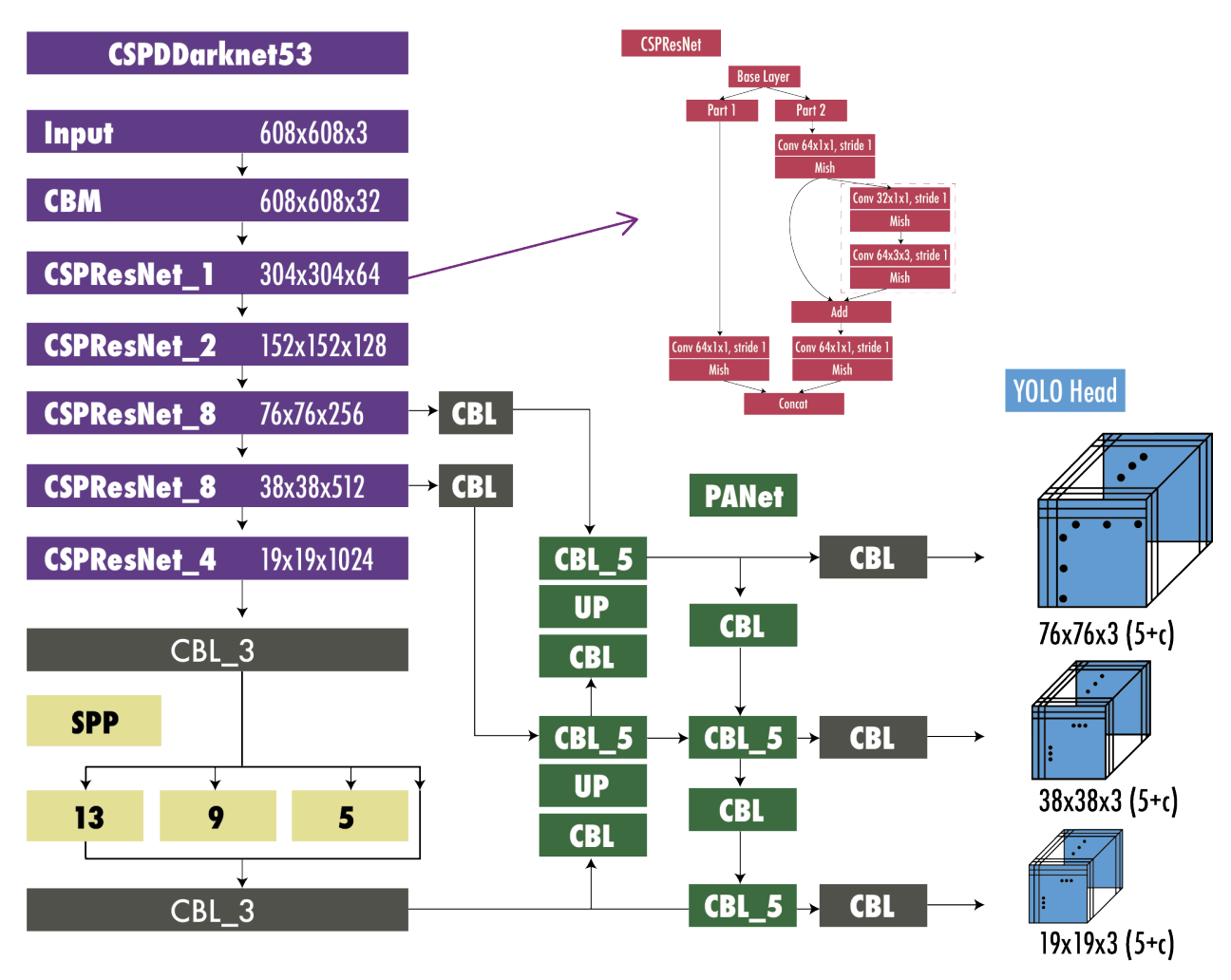
- 학습 전략 개선
| 기법 | 설명 |
|---|---|
| Mosaic augmentation | 4개 이미지를 하나로 합쳐 훈련 → 일반화 강화 |
| DropBlock regularization | CNN에 맞는 Dropout 대체 |
| Label smoothing | Overfitting 방지 |
| CloU loss | 기존 IoU보다 정확한 박스 회귀 손실 함수 |
| CmBN | Cross mini-batch normalization, 더 안정적인 통계 계산 |
| Self-adversarial Traing (SAT) | 적대적 perturbation으로 강건성 향상 |
- 최적화 기법
- Genetic Algorithm : 학습 초기 하이퍼파라미터 자동 탐색
- Cosine Annealing Scheduler : 부드럽고 효과적인 learning rate 감소 전략
YOLOv5 (2020, Ultralytics)
- DarkNet → PyTorch 기반으로 전환된 첫 YOLO
- 실제 산업 및 연구에서 가장 많이 사용된 YOLO 버전 중 하나
[주요 기술적 특징]
| 프레임워크 | PyTorch |
|---|---|
| Backbone | CSPDarknet53 + Stem (큰 커널로 시작해 메모리 효율 개선) |
| Neck | SPFF + CSP-PAN |
| Head | YOLOv3 스타일의 탐지 헤드 |
| Activation | SiLU |
| Loss | CIoU 기반 손실 함수 |
| Augmentation | Mosaic, CopyPaste, MixUp, Random Affine 등 다양한 기법 사용 |
| AutoAnchor | anchor box 자동 최적화 도구 (k-means + Genetic Evolution 기반) |
SPPF
→ 입력 feature map의 다양한 수용영역을 고려하여 다양한 크기의 객체를 인식할 수 있게 해주는 구조 (기존의 SPP보다 더 빠르고 효율적인 구조로 개선)
CSP-PAN
→ YOLOv5에서 Neck 부분의 특징 추출 및 정보 전달 강화를 위해 사용
- CSP 구조
- feature map을 두 갈래로 나눠 일부만 연산 → 다시 합침
- 연산량을 줄이면서 gradient 흐름 방해 안함
- PANet
- Bottom-up과 Top-down 경로 모두 사용하여 위치 정보와 의미 정보를 효율적으로 결합
YOLOv6 (2022)
[YOLOv6의 핵심 변화]
- EfficientRep Backbone
- 기존 YOLO보다 병렬성 높은 구조
- RepVGG 기반 구조로 추론 시 구조 단순화, 훈련과 추론을 분리
- Decoupled Head
- YOLO처럼 분류와 회귀를 분리된 경로로 처리
- 추가로 IoU 예측 브랜치 포함 → 위치 정밀도 향상
- Task-aligned Label Assignment
- TOOD에서 제안된 방법
- 분류와 회귀의 학습 목적을 잘 정렬하여 성능 향상
- Loss Functions
- VariFocal Loss : 중요한 예제를 더 집중 학습
- SIoU Loss : 물체의 모양과 방향까지 고려하는 고급 회귀 손실
- Quantization
- Post-training Quantization + RepOptimizer
- 채널 단위 distillation으로 정확도 손실 없이 속도 개선
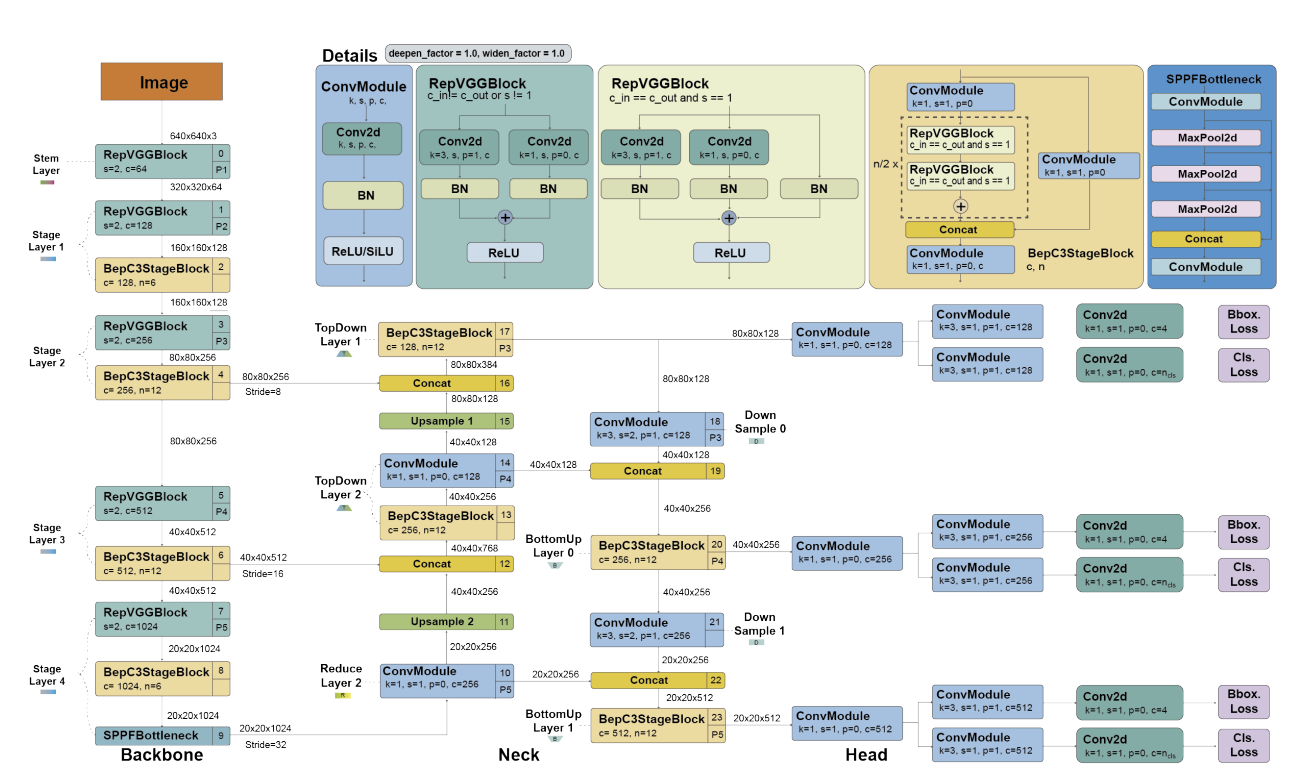
YOLOv7 (2022)
[주요 변화점]
- E-LAN (Extended Efficient Layer Aggregation Network)
- 깊은 네트워크에서도 효율적인 학습과 수렴을 지원
- 다양한 그룹의 피처를 shuffle → concat하여 정보 융합
- 잔차 경로 보존하며 학습 안정성 유지
- Model Scaling for concatenation-based Models
- YOLOv7은 concatenation (사슬 모형) 기반 아키텍처이기 때문에 기존 scaling 방식이 적합하지 않다.
⇒ depth 와 width를 동일한 비율로 확장하는 새로운 스케일링 전략 제안
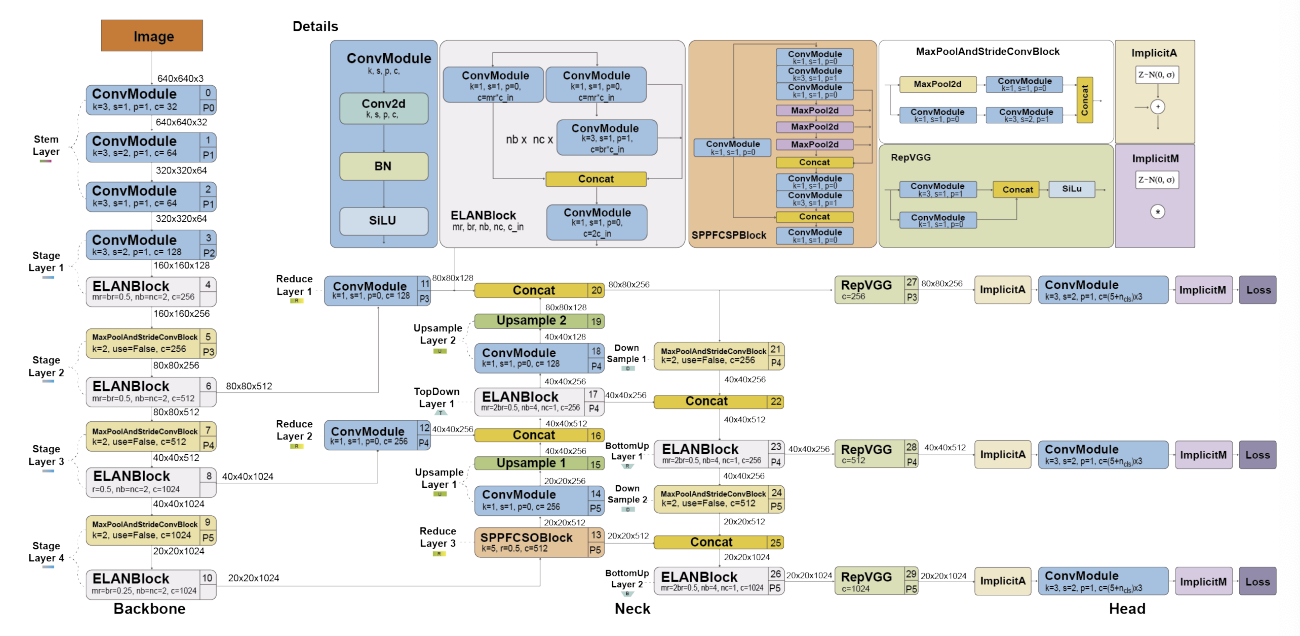
YOLOv8 (2023, Ultralytics)
[구조적 특징]
| 구성 요소 | 설명 |
|---|---|
| BackBone | YOLOv5와 유사, 개선된 C2f 모듈 사용 |
| C2f 모듈 | Cross-stage partial 구조 + bottleneck+ 2conv → 추론 정확도 향상 |
| Anchor-Free | YOLO 최초로 anchor 없이 직접 박스 중심 좌표 예측 |
| Decoupled Head | objectness, class, box regression을 독립적으로 처리 → 정확도 향상 |
| Activation | objectness → sigmoid, class → softmax |
| Loss 함수 | 박스 : CIoU + DFL, 분류 : binary cross entropy |
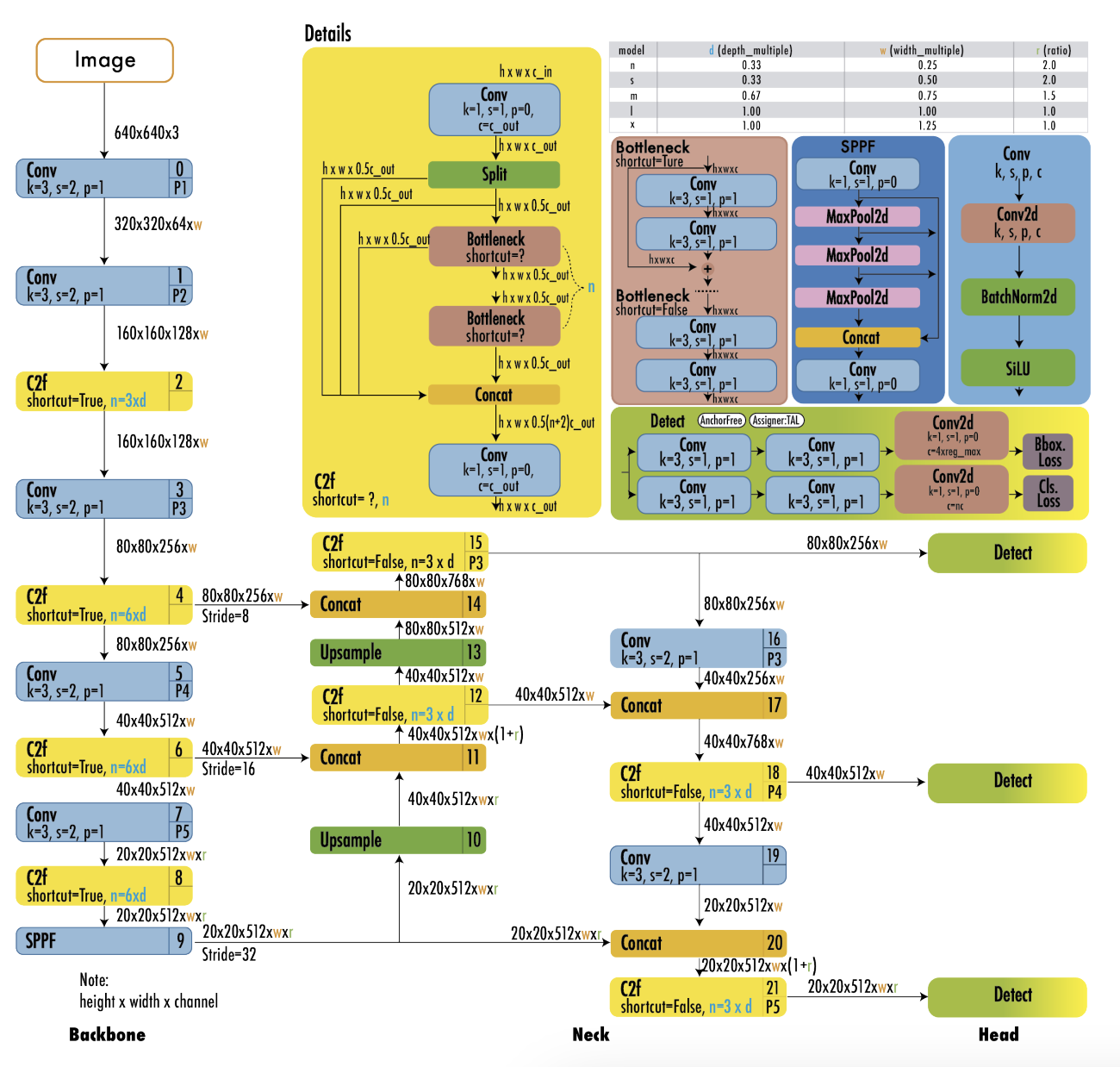
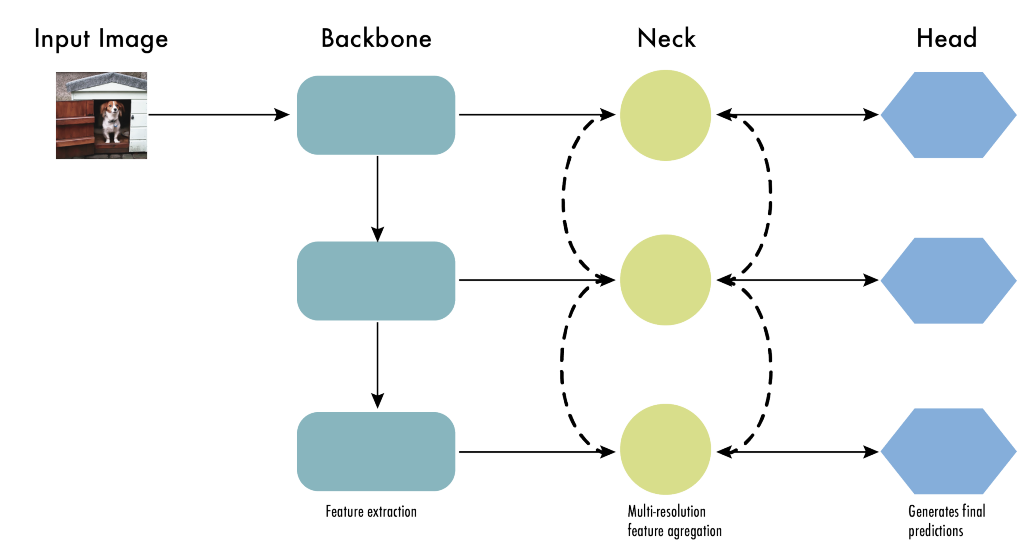
BackBone, Neck, Head?
| Backbone | 입력 이미지에서 특징(feature) 추출 | CNN 계열 (Darknet-53, RepVGG 등) |
|---|---|---|
| Neck | Backbone의 여러 레벨의 특징을 통합, 정제하여 Head로 전달 | FPN, PANet, SPPF, C2f 등 |
| Head | 객체의 클래스, 위치, confidence를 예측 | Anchor 기반 |
| Post-Processing | NMS 등으로 최종 결과 필터링 | Non-Maximum Suppression, Soft-NMS 등 |
Backbone
- 이미지에서 계층적 특징을 추출하는 부분
- 낮은 레벨 : 에지, 텍스처 등
- 높은 레벨 : 형태, 패턴, 객체의 구성 요소 등
Neck
- 다양한 해상도의 특징을 통합/보강
- 다중 스케일에서의 정보 결합이 핵심
Head
- 클래스 분류, 바운딩 박스 좌표 예측, confidence score 예측
- segmentation, pose estimation 도 수행
Post - Processing
- 예측 결과 중 겹치는 박스 제거, 가장 확률이 높은 결과만 남김
- 일반적으로는 NMS 사용
YOLO 구조는 Backbone(특징 추출) → Neck(통합) → Head(예측) → Post-Processing(결과정리)으로 구성
주요 변화 포인트 요약
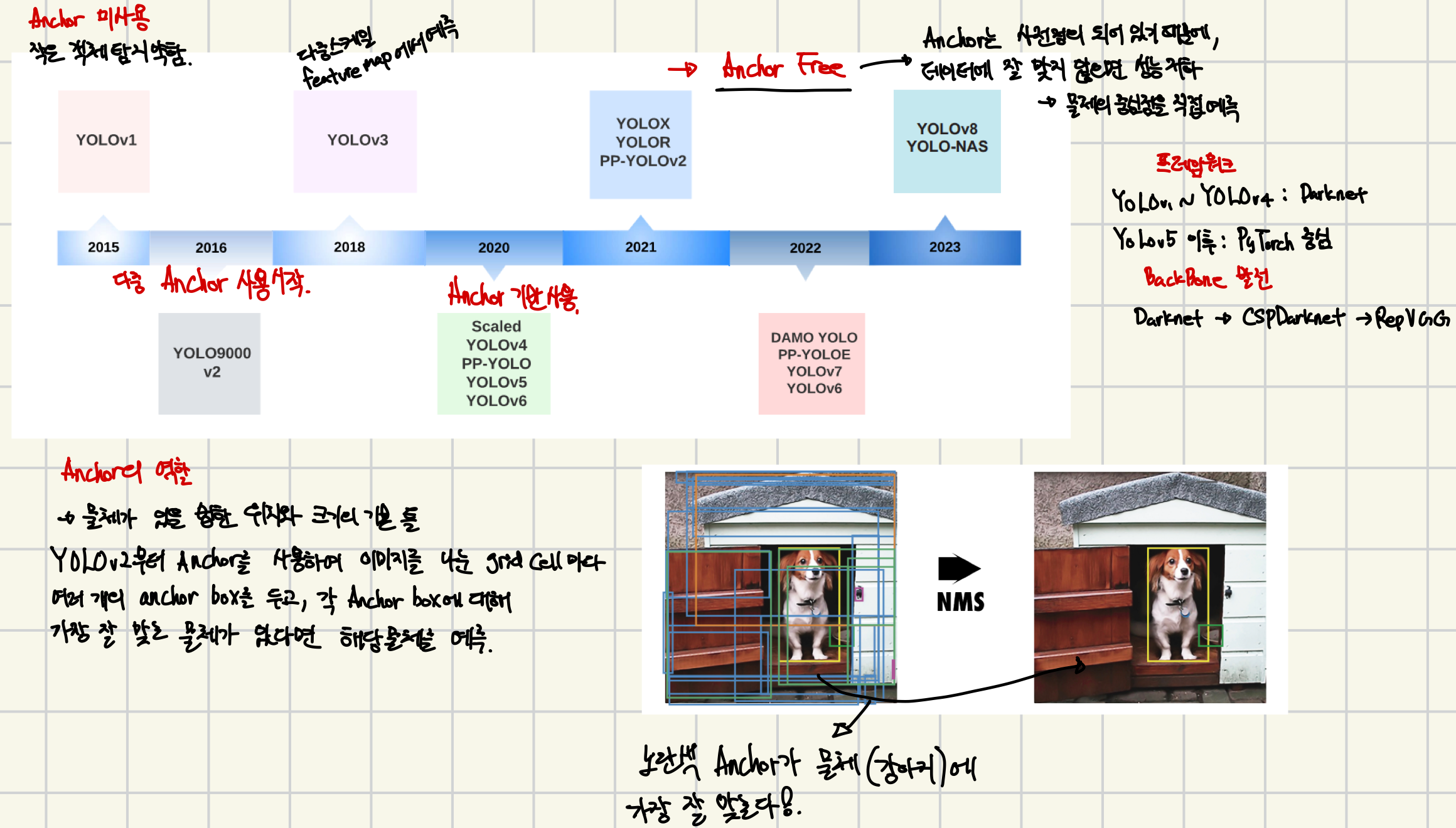
| YOLOv1 | 속도 중시 → 작은 객체 탐지 성능 저하 | | — | — | | YOLOv2 ~v3 | Anchor box, multi-scale feature → 정확도 개선 (각 grid cell마다 여러 개의 anchor box 사용) | | YOLOv4 ~ v5 | CSP 구조, SPP, Mosaic 등 다양한 기법으로 정확도 상승 + 속도 유지 다중스케일 feature map에서 예측 (13x13, 26x26, 52x52) → 작은 객체는 고해상도 feature 에서 탐지 | | YOLOv6 ~ v8 | 모델 경량화 버전부터 고성능 버전까지 다양한 크기 지원 |
Backbone 의 변화
| YOLOv1~v3 | Darknet |
|---|---|
| YOLOv4 | CSPNet + Mish |
| YOLOv5 | CSPDarknet + SPPF |
| YOLOv6 | RepVGG 기반 EfficientRep |
| YOLOv7~v8 | E-LAN (확장된 효율적 Layer Aggregation) |
정리
본 논문은 YOLOv1부터 YOLO-NAS에 이르기까지 YOLO 시리즈의 구조적 진화와 성능 향상을 폭넓게 다루며, 객체 탐지 분야에서 YOLO가 차지하는 핵심적인 위치를 잘 보여준다. YOLO는 초기에는 단일 CNN 기반의 빠른 탐지를 목표로 했으나, 시간이 지남에 따라 정밀도와 확장성까지 고려한 다양한 버전으로 발전해왔다.
특히 최근에는 anchor-free 접근, 자동 구조 탐색(NAS), 그리고 분류·세분화·자세 추정 등 멀티태스크 비전 문제까지 다루는 모델로 진화하며 범용적 비전 Backbone으로서의 가능성도 보여주고 있다.
향후에는 경량화된 YOLO 모델을 다양한 산업 분야에서 활용 가능할것 같다. (범용성이 넓은 모델이라 이미 많이 사용하고 있을 것 같다.