PR [FaceNet: A Unified Embedding for Face Recognition and Clustering]
FaceNet: A Unified Embedding for Face Recognition and Clustering
1. 연구의 배경
- 이전의 Face Recognition에 대한 접근 방식
- Deep Networks
- 단순히 여러 개의 계층으로 깊게 쌓인 신경망을 활용 (주로 Convolutional Neural Network 사용)
- Classification을 통해 얼굴 특징을 학습
- bottle-neck layer
- 심층 신경망에서 데이터의 차원(Dimensionality)이 일시적으로 크게 줄어드는 계층
- Deep Networks
문제점 → Indirectness , Inefficiency
- 위의 문제점을 해결하기 위해 PCA를 통해 차원을 줄이기 위한 시도가 있었지만, PCA는 선형 변환에 불과했으며, 이는 네트워크의 마지막 계층에서 쉽게 학습이 가능했다.
따라서, FaceNet은 위와 같은 문제를 해결하기 위해 Deep Convolution Network를 사용한 유클리드 임베딩 학습 방식을 제안
FaceNet
- 이미지 하나당 deep convolutional network를 사용하여 compact한 임베딩 벡터(128-차원) 생성
- 유클리드 공간에서 각 이미지(얼굴)간의 임베딩 벡터를 Triplet Loss를 사용하여 학습
- 유클리드 공간에서 임베딩 벡터간의 거리(유사도)를 계산
- 만약 동일한 사람의 얼굴이면 거리가 짧을 것이고, 다른 사람의 얼굴이면 거리가 멀 것이다.
연구의 배경 💡
이전의 Face Recognition에 대한 접근은 주로 Deep Networks와 bottle-neck layer를 활용한 접근이었다. 하지만, 해당 접근에는 Indirectness(간접성), Inefficiency(비효율성) 문제가 존재했다.
따라서, 기존의 Face Recognition에 대한 접근의 한계를 극복하기 위해 FaceNet을 제안한다.
FaceNet은 각 얼굴 이미지 당 Deep Convolutional Network를 사용하여 임베딩 벡터를 생성하고, 각각의 임베딩 벡터를 유클리드 공간에서 유사도(거리)를 측정 (같은 사람의 얼굴이면 거리가 짧고, 다른 사람의 얼굴이면 거리가 멀다; 여기서의 거리는 유사도를 의미한다.)
FaceNet의 목표는 Triplet Loss 를 활용하여 이 유클리드 공간에서 같은 사람의 임베딩 벡터 간의 거리는 최소가 되도록, 다른 사람의 임베딩 벡터 간의 거리는 최대가 되도록 학습하는 것이다.
2. 주요 기여
1. Illumination and Pose invariance

- 조명과 자세 변화에 대한 문제는 Face Recognition에서 오랜 난제
- 위의 사진(Figure 1)은 다양한 자세와 조명 조합에서 같은 사람과 다른 사람의 얼굴 쌍 사이의 FaceNet의 출력 거리를 나타낸다.
- 오랜 난제였던 조명과 자세 변화에 FaceNet은 강하다.
2. FaceNet 등장 전, 얼굴 인식 분야에서 최고 성능을 달성한 주요 연구와의 차이점
DeepFace (Taigman et al.)
FaceNet과의 차이점 → DeepFace는 복잡한 3D 정렬, 앙상블, 비선형 SVM 등 복잡한 구조로 훈련
DeepID (Sun et al.)
FaceNet과의 차이점 → 여전히 PCA나 Joint Bayesian 같은 추가적인 선형 변환을 사용, 오직 쌍(pair)의 이미지만 비교 (FaceNet은 Triplet Loss 3개의 이미지 사용)
⇒ FaceNet은 DeepFace나 DeepID와 같은 복잡한 시스템을 제거하며, 효율 극대화
- End-to-End Learning
- Triplet Loss를 도입하여 이미지 픽셀에서 임베딩 벡터까지 최적화하는 End-to-End 학습 방법론을 제안
- 유클리드 임베딩
- 얼굴의 특징을 128차원 유클리드 공간으로 매핑하고, 단순한 거리 계산만으로 얼굴 검증, 인식 등과 같은 Task가 가능
3. Triplet Loss와 임베딩 공간 설명
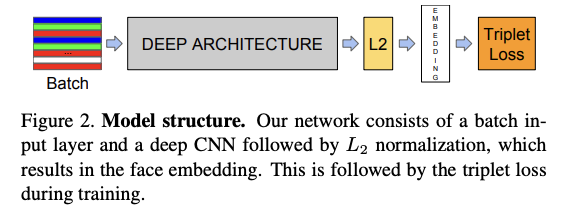
Triplet
- FaceNet은 compact한 128-D 임베딩 벡터를 Triplet 기반의 Loss Function을 사용하여 학습
- FaceNet의 Triplet
→ 모델을 학습시킬 때 이미지 3장을 한 세트(Triplet)로 묶어서 학습
- 2개의 matching 얼굴 썸네일을 1개의 non-matching 얼굴 썸네일로부터 구분하는 것을 목표로 함
- 각각의 썸네일에는 스케일 및 변환 이외에는 2D/3D 정렬을 수행하지 않음
- Triplet Loss의 목적
- 이미지 x를 d 차원의 특징 공간 R^d 상의 임베딩으로 변환하려하고, 이때 조명이나 각도 등 촬영 조건과 관계없이, 같은 사람의 얼굴들 사이의 거리는 작게, 다른 사람의 얼굴들 사이의 거리는 크게 만드는 것이 목표
Triplet Selection
- 학습 효율을 높이기 위해서는 Hard Triplet (틀리기 쉬운 어려운 데이터)를 찾는 것이 중요
- 거리가 최소인 데이터를 활용 (Anchor와 다르지만, 가장 가까이에 있는 이미지)
- 왜 전체 데이터셋에서 찾지 않는가?
- 전체 데이터셋에서 찾는 것은 현실적으로 불가능하며, 오류 데이터가 뽑힐 확률도 있다.
논문에서 제시하는 방법 2가지
- Offline Generation (오프라인 방식)
- N번 학습할 때마다 데이터의 일부 (Subset)에서 어려운 문제(Argmax, Argmin)들을 활용
- Online Generation (온라인 방식)
- 미니 배치 안에 있는 이미지 중에서 어려운 positive/negative 조합을 찾음
논문에서 택한 방식 → Online Generation (온라인 방식)
- 처음에는 Online Generation 방식으로 배치 안에 있는 이미지 중에서 가장 어려운(가장 거리가 가까운) negative 이미지와 Anchor를 기준으로 Positive를 모두 사용해서 Triplet을 구성
→ ‘Bad Local Minima’가 발생하여 결국 모델이 붕괴되었음
따라서, negative 이미지를 고를 때, 가장 어려운 (거리가 가장 가까운) 이미지를 선택하지 않고, Semi-Hard (적당히 가까운) negative 이미지를 선택하여 Triplet을 구성 (아래의 식을 통해 Semi-Hard Negative 이미지 선택)
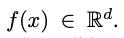
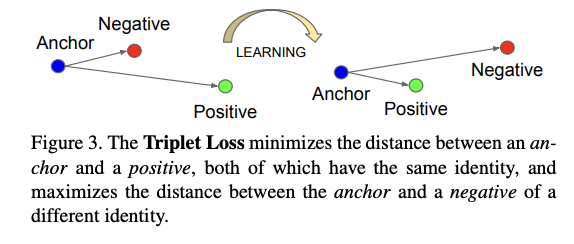
임베딩 공간
- 이미지 x를 d 차원의 유클리드 공간으로 임베딩한다.
- 임베딩한다는 것의 의미는 대상을 모델이 이해할 수 있는 좌표로 변환하는 것이며, 해당 논문에서 뜻하는 임베딩 공간은 사람의 얼굴이라는 정보를 연산과 거리 측정이 가능한 128개의 숫자 리스트로 변환하는 것을 의미한다.
여기서 어떠한 특정 사람의 이미지 x^a (anchor)와 동일한 사람의 또 다른 이미지 x^p (positive) 사이의 거리가 다른 사람의 이미지 x^n (negative) 사이의 거리보다 가까워지도록 학습한다. (아래의 사진에서 확인 가능)
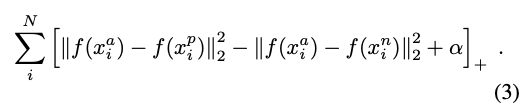
‘거리 학습’의 수학적 정의
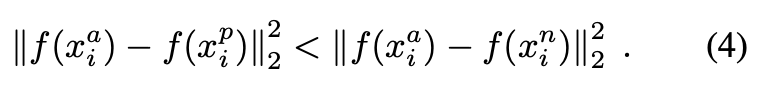
Loss Function
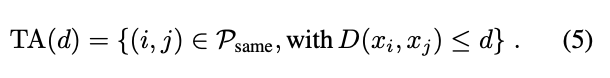
- 모델이 같은 사람의 이미지를 맞췄을 때
- Positive 거리 + α 보다 Negative 거리가 훨씬 멀리 있다.
- 모델이 같은 사람의 이미지를 맞추지 못했을 때
- Negative 거리가 더 가까이 붙어있다.
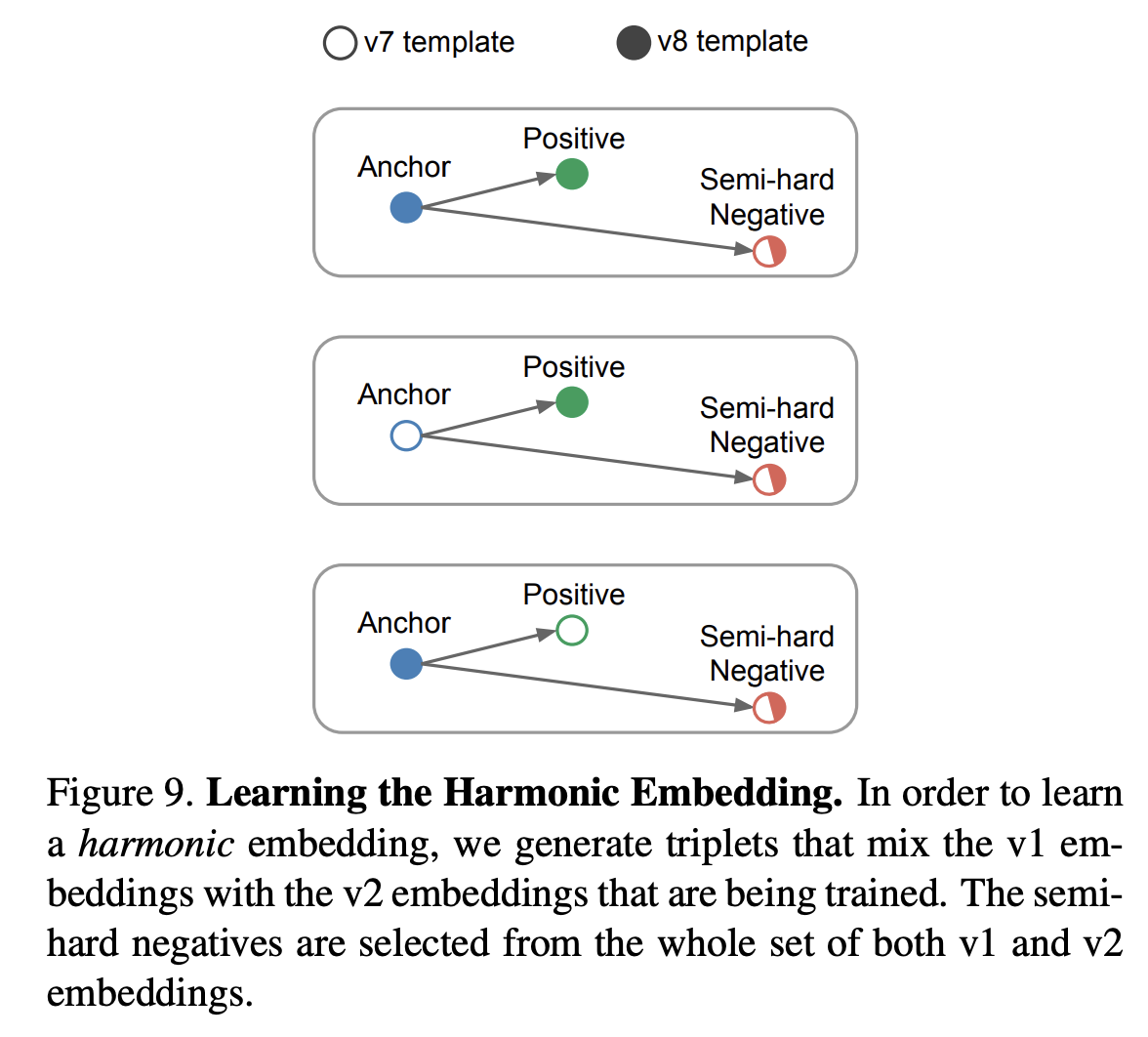
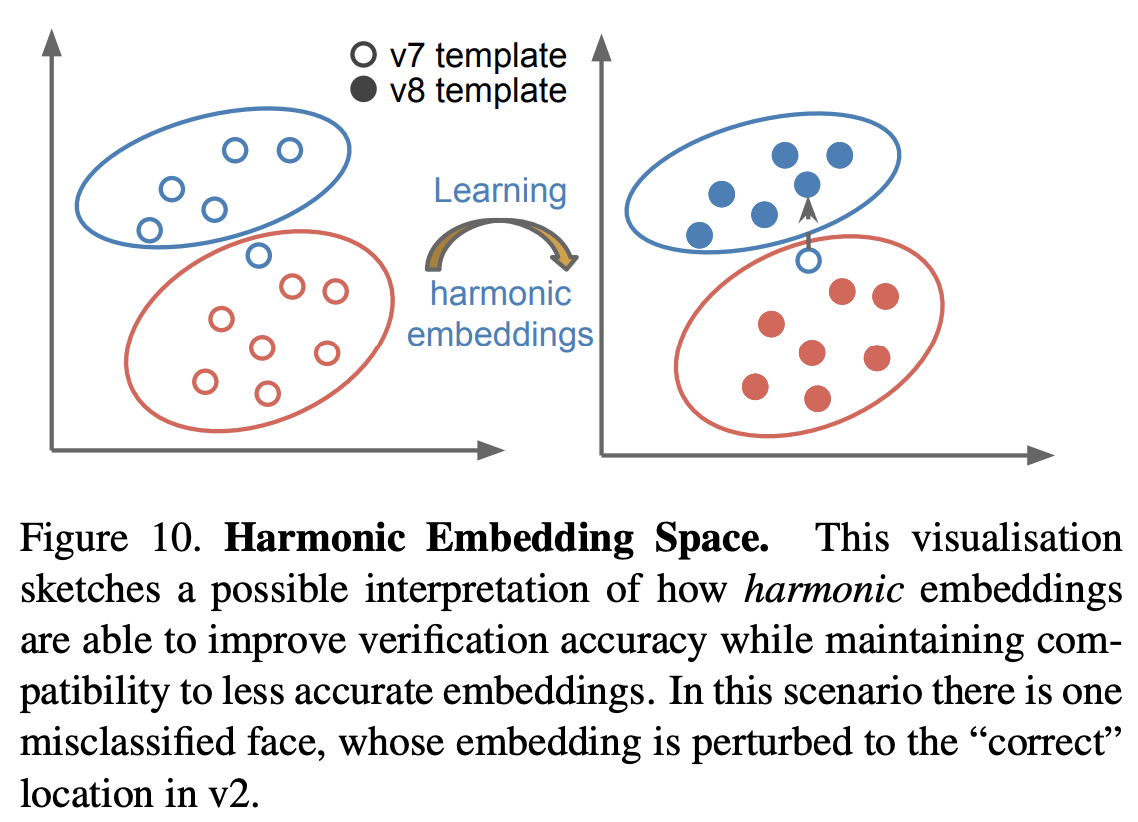
Harmonic Embedding & Triplet (Appendix)
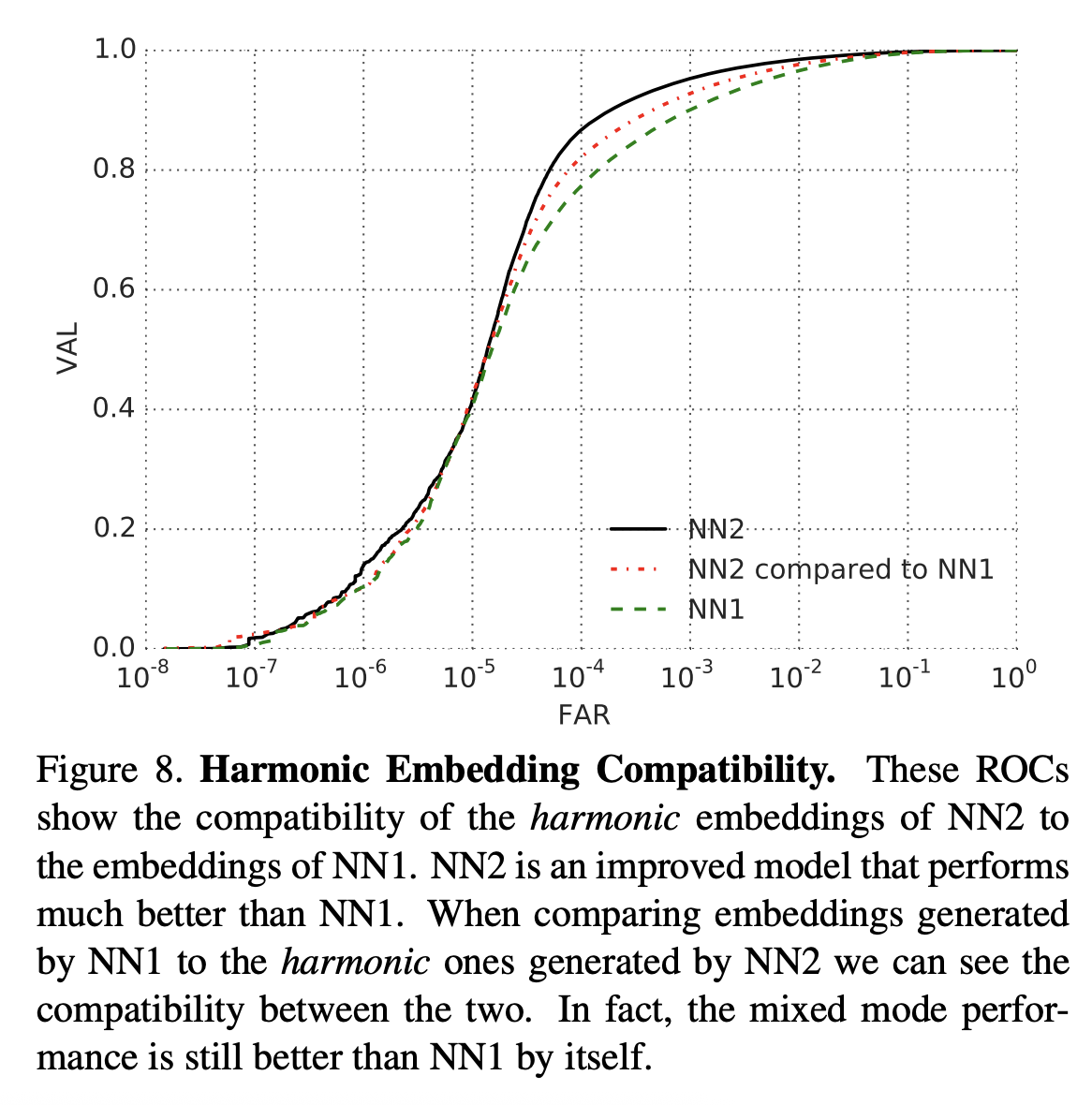
Harmonic Embedding
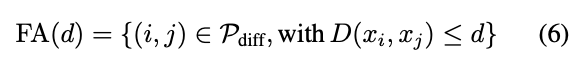
- 서로 다른 모델에서 생성된 임베딩 벡터(V1, V2)가 서로 호환이 되도록 하는 임베딩
- Harmonic Embbedding → 서로 다른 모델에서 생성된 임베딩 벡터들에 호환성을 부여하기 때문에, 시스템 업그레이드 과정을 단순화할 수 있다.
- 위의 사진에서 개선된 모델 NN2(V2)는 기존 NN1(V1)보다 성능이 좋으며, NN1 모델에 NN2 모델이 활용하는 임베딩 벡터를 부여했을 때, NN1모델보다 더 성능이 좋다.
→ NN1, NN2 모델 간의 호환성을 Harmonic Embedding을 통해 부여
Harmonic Triplet
Harmonic Triplet은 Triplet을 구성할 때 서로 다른 모델(V1,V2)이 생성한 임베딩 벡터를 섞어서 Triplet을 구성 (위의 사진처럼)
- 이를 통해 V2 모델이 V1의 좌표 공간을 따르도록 강제한다.
- 결과적으로 V2는 V1의 오류를 수정하면서, V1와 호환이 가능한 임베딩을 생성하게 된다.
4. 성능 및 실험
데이터셋 및 Task (Datasets) :
- LFW (Labeled Faces in the Wild), YouTube Faces를 비롯한 4개의 데이터셋을 활용하여 성능을 검증
- Hold-out Test set 활용
- 학습에 사용하지 않은(Disjoint Identities) 100만 장의 이미지를 통해 Hold-out Test Set 구축
- 이를 5개의 세트(각 200k)로 나누어 교차 검증을 수행, 각 세트마다 (100k x 100k) 방대한 규모의 이미지 쌍을 비교하여 FAR과 VAL을 측정
- Personal Photos 활용
- 라벨 오류가 없는 고품질의 개인 사진 데이터
- Academic Datasets (LFW, Youtube Faces)
- 학계 표준 벤치마크 데이터셋, 특히 LFW는 사진 검증을, Youtube Faces에서는 동영상 기반 검증을 수행
- Hold-out Test set 활용
- 평가는 주로 얼굴 검증 (Face Verification) Task로 진행되었고, 주어진 두 장의 얼굴 이미지가 동일 신원(Identity) 인지 아닌지를 판별
평가 지표 :
- 쌍을 이루는 2개의 이미지의 임베딩 벡터 간의 L2 거리 (Squared L2 Distance)를 계산하고, 임계값 (d)를 기준으로 판단
- 거리가 d 이하면 같은 사람 (P_same), 초과면 다른 사람 (P_diff)로 분류)
- VAL (Validation Rate), FAR (False Accept Rate) 지표 사용
- 타인을 본인으로 오인하는 비율 (FAR), 통제한 상태에서 본인을 얼마나 잘 알아보는지 (VAR)
[수식 해석]
(5)
- P_same : 실제로 같은 사람
- ≤ d : 모델이 동일 인물이라고 판별한 경우
→ 동일한 사람의 이미지이며, 2개의 이미지가 동일한 Identity를 가졌다고 판별한 경우
(6)
- P_diff : 실제로 다른 사람
- ≤ d : 모델이 동일 인물이라고 판별한 경우
→ 서로 다른 사람의 이미지 쌍인데, 2개의 이미지가 동일한 Identity를 가졌다고 판별한 경우
(7)

- 임계값 d에 따른 VAL (검증 성공률) 과 FAR (잘못된 허용 비율) 식
- 임계값 d를 엄격하게 설정 → FAR은 낮아지면서 보안은 완벽해지지만, 반대로 VAL이 떨어짐
- 임계값 d를 느슨하게 설정 → VAL은 높아져 편리하지만, 반대로 FAR이 높아짐
실험 (Experiments) :
실험 데이터 및 전처리
- 약 800만명의 신원으로 구성된 1억~2억 장의 얼굴 이미지를 사용 (방대한 양의 데이터)
- 각 이미지에 얼굴 탐지기 (Face Detector)를 적용하여 얼굴 영역을 타이트하게 검출(Bounding Box)한 후, 네트워크의 입력 해상도에 맞춰 Resize하여 입력으로 사용
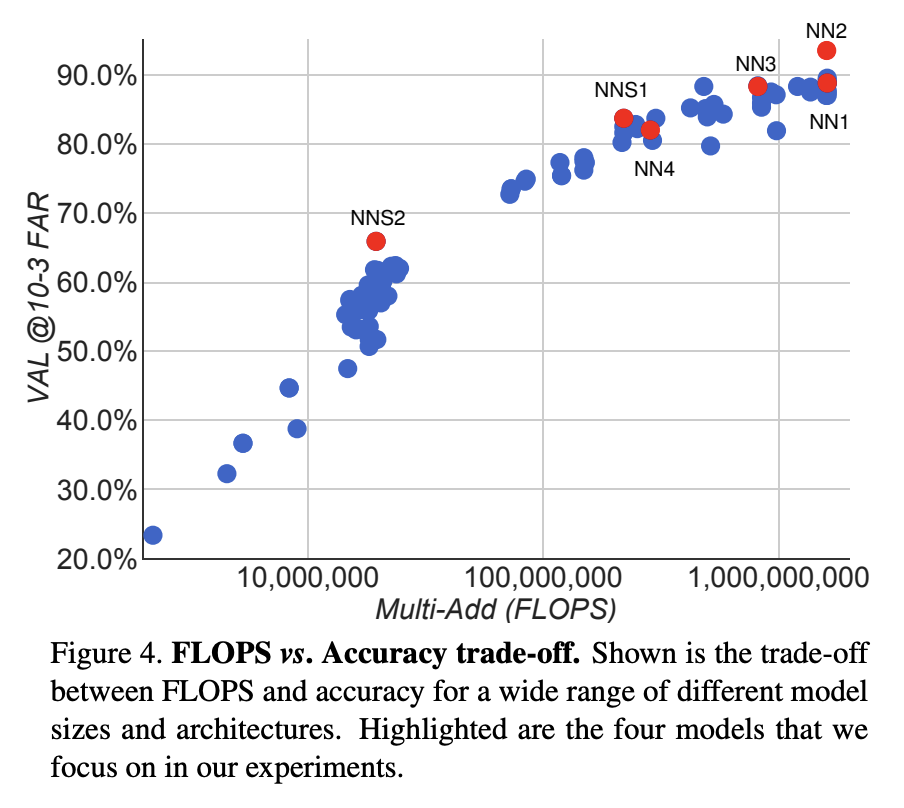
모델의 정확도와 FLOPS (연산량) 사이의 관계

- 모델의 정확도는 연산량 (FLOPS)와 강한 양의 상관관계를 보인다.
- 반면, 모델의 파라미터 수와 성능 간의 관계는 비례하지 않는다.
- Inception 기반 모델 (NN2)은 기존 모델 (NN1) 대비 파라미터 수가 1/20에 불과하지만, 유사한 수준의 FLOPS를 유지하며 동등한 정확도를 달성
→ FaceNet은 Inception 아키텍처를 통해 모델 경량화와 고성능을 동시에 확보
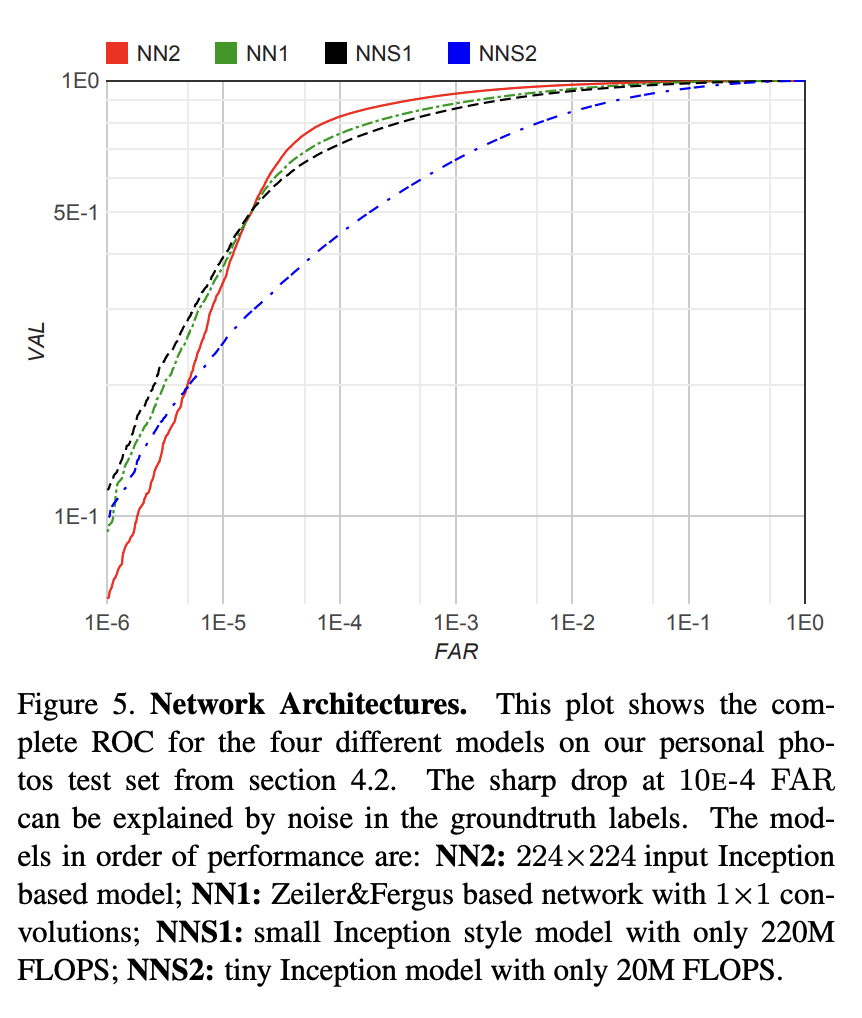
CNN Model의 영향
- 아키텍처 비교
- Zeiler & Fergus 모델과 최신 Inception 기반 모델 2가지를 비교 분석
실험 결과 → 두 아키텍처의 최고 성능 모델들은 정확도 면에서 눈에 띄는 차이를 보이지 않음
하지만, Inception 기반 모델은 연산량 (FLOPS)와 파라미터 수를 획기적으로 줄이면서도 높은 성능을 유지
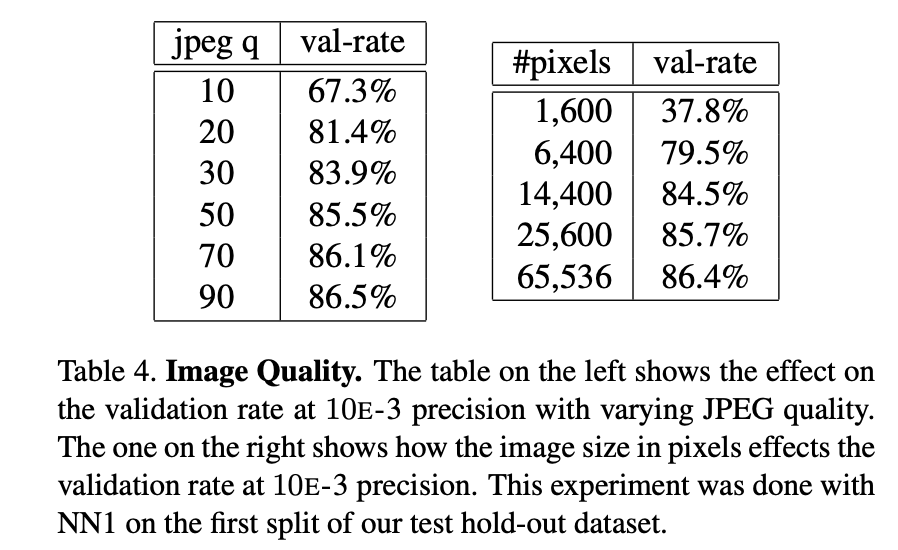
이미지 품질에 대한 강건성
- JPEG 압축률이 매우 높은 상황이나, 이미지 해상도가 크게 낮아진 상황에서도 강건성을 유지
- 220 x 220 해상도로 학습된 모델임에도, 80x80 픽셀 수준의 저해상도 이미지에서도 준수한 성능을 유지
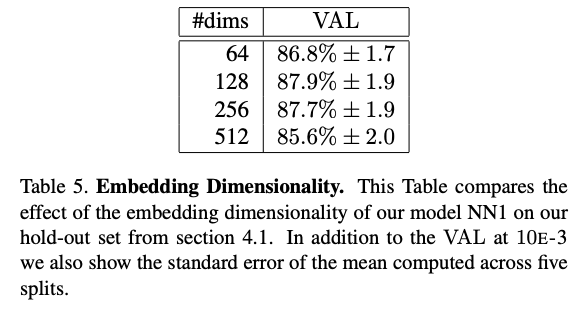
임베딩 차원의 최적화
- 다양한 차원으로 실험을 진행해본 결과, 정확도와 연산 효율성 간의 균형이 가장 뛰어난 128차원을 최종적으로 선택
- 128 차원보다 큰 차원을 사용하더라도 통계적으로 유의미한 성능 향상은 없었으며, 오히려 학습 난이도만 높아졌다.
- 128차원 실수 벡터를 128바이트로 양자화 하더라도 정확도 손실이 거의 없었다.
성능
Performance on LFW
- Standard Protocol, 10-Fold Cross Validation 활용
- 임계값 (Threshold) : d(거리)를 1.242 기준으로 남/녀를 구분할 때 결과가 가장 좋았음
1번째 테스트 방법
- 이미지 가운데 부분을 crop하여 테스트
→ 정확도 : 98.87%
2번째 테스트 방법
- 구글의 자체적인 얼굴 탐지기 (Proprietary Face Detector)를 사용하여 얼굴 정렬을 수행한 후, 입력으로 사용
→ 정확도 : 99.63%
[결과의 의미]
- vs DeepFace : 에러율을 1/7로 줄임
- vs DeepId2 : 기존의 최고 기록보다 에러를 30% 더 줄임
“FaceNet은 얼굴 인식 표준 데이터인 LFW 데이터셋에서 99.63%의 정확도를 기록하며 SOTA를 갱신”
<LFW 데이터셋에 대해서 오분류된 이미지
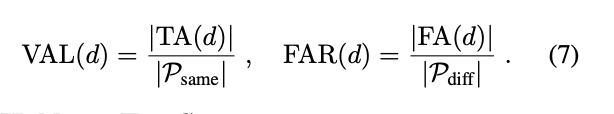
Performance on Youtube Faces DB
- 각 비디오에서 검출된 첫 100개 프레임의 모든 쌍에 대해 평균 유사도를 계산하는 방식 사용
→ 95.12%의 분류 정확도 달성
- vs DeepFace : 동일하게 100프레임을 사용한 DeepFace (91.4%) 대비 에러율을 약 50% 감소
- vs DeepId2+ : DeepId2+ (93.2%) 대비 에러율을 약 30% 감소
평균 유사도를 사용하는 이유?
- 동영상은 흔들리거나, 옆모습이 나오는 등 프레임마다 품질이 다르다.
- 따라서 100장을 다 비교하여 평균을 내는 방식을 통해 노이즈를 상쇄시켜 안정적인 결과를 얻음
Face Clustering

- 병합 군집화 (Agglomerative Clustering) 알고리즘을 사용
- 조명 변화나 포즈, 가림뿐만 아니라 나이 변화에도 불구하고 동일 인물을 하나의 그룹으로 정확하게 군집화
→ FaceNet은 인물의 고유한 신원 정보를 효과적으로 임베딩하고 있다.
5. 응용 가능성과 한계 분석
응용 가능성
- 연산 효율성을 통한 무제한 확장성
- 기존의 SVM 같은 무거운 분류기와 비교해보았을때 FaceNet은 이미지 간의 유클리드 거리만 측정하면 된다.
- 128차원의 임베딩 벡터를 정확도 손실 없이 128 바이트로 양자화하는 것이 가능하기 때문에 방대한 규모의 데이터를 적은 메모리에 적재하고 빠른 속도로 검색이 가능
→ 복잡한 분류기 대신 단순하고 효율적인 방식을 통해 기존 보안 시스템을 넘어 다양한 산업 분야로의 유연한 확장이 가능하다.
- Appendix에서 제안한 하모닉 임베딩(Harmonic Embedding)을 응용하여 모바일 기기와 서버가 협력하는 시스템을 구축할 수 있다.
- 모바일 : 연산량이 적은 경량화 모델을 탑재하여 빠르게 임베딩 생성
- 서버 : 정확도가 높은 대형 모델로 관리
→ Harmonic Embedding을 통해 서로 호환되도록 학습하여 모바일 환경의 경량성 및 속도와 서버 환경의 고성능 및 대규모 데이터 처리를 결합한 시스템을 구축할 수 있다.
한계 분석
- Error 케이스 분석 및 모델 경량화 (CPU 사용량 감소)
- 학습 속도 개선 (더 작은 배치 크기를 활용한 Curriculum Learning, 마이닝 기법 개선 등)
- 가장 어려운 (Hardest) 샘플만을 골라 모델을 학습시키면 붕괴되는 문제가 있었으며, 이는 적절한 난이도의 데이터를 지속적으로 공급해줘야 한다는 한계가 존재한다.
- FaceNet의 압도적 성능에 구글 내부의 비공개 데이터셋 (약 2억장)이 기여하는 바가 크다고 생각한다. 이와 같은 대규모의 정제된 데이터를 확보하기 어렵기 때문에, 논문의 성능을 재현하는 데에는 한계가 분명히 존재할 것이다.